Amazon Web Services ブログ
Amazon EMR Serverless のベストプラクティス 10 選
本記事は 2026 年 1 月 26 日 に公開された「Top 10 best practices for Amazon EMR Serverless」を翻訳したものです。
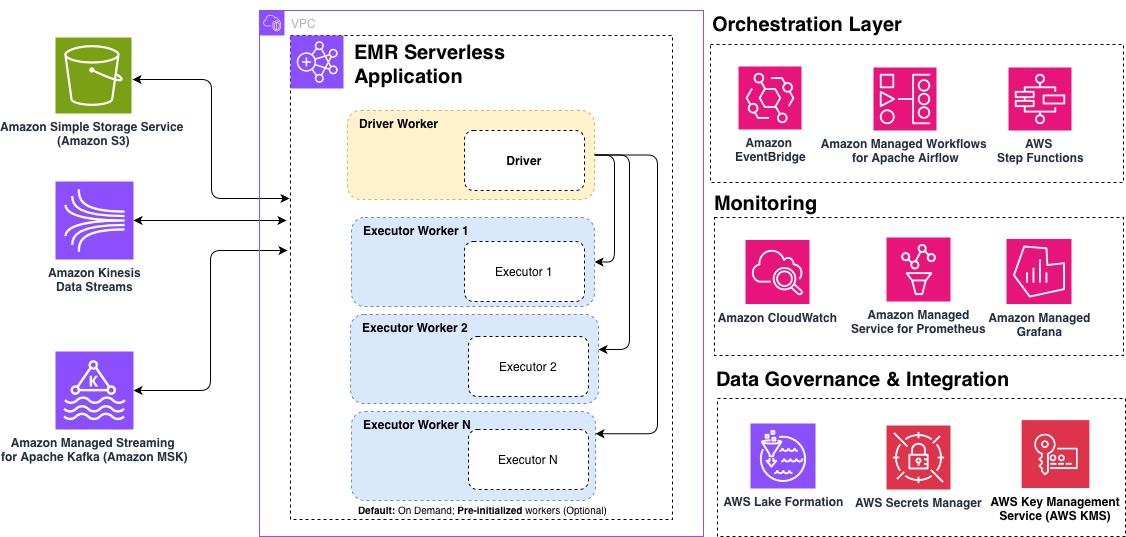
Amazon EMR Serverless は Amazon EMR のデプロイオプションの 1 つで、Apache Spark や Apache Hive などのオープンソースビッグデータ分析フレームワークを、クラスターやサーバーの設定・管理・スケーリングなしで実行できます。EMR Serverless は、データストレージ、ストリーミング、オーケストレーション、モニタリング、ガバナンスにわたる Amazon Web Services (AWS) サービスと統合し、サーバーレス分析ソリューションを実現します。
本記事では、EMR Serverless ワークロードのパフォーマンス、コスト、スケーラビリティを最適化するためのベストプラクティス 10 選を紹介します。EMR Serverless を使い始めたばかりの方も、既存の本番ワークロードを改善したい方も、効率的でコスト効率の高いデータ処理パイプラインの構築に役立つ内容です。以下の図は、EMR Serverless のエンドツーエンドアーキテクチャを示しており、分析パイプラインへの統合方法を表しています。
1. アプリケーションは一度定義して繰り返し使う
EMR Serverless アプリケーションはクラスターテンプレートに相当し、ジョブ送信時にインスタンス化され、再作成せずに複数のジョブを処理できます。アプリケーションを再利用することで起動レイテンシーを削減し、運用管理を簡素化できます。
EMR on EC2 一時クラスターの一般的なワークフロー:

EMR Serverless の一般的なワークフロー:

アプリケーションは自己管理型のライフサイクルを備えており、必要なときに手動操作なしでリソースをプロビジョニングします。ジョブが送信されると自動的にキャパシティをプロビジョニングします。事前初期化キャパシティのないアプリケーションでは、ジョブ完了後すぐにリソースが解放されます。事前初期化キャパシティが設定されている場合、設定されたアイドルタイムアウト (デフォルト 15 分) を超えるとワーカーが停止します。このタイムアウトは、CreateApplication または UpdateApplication API の AutoStopConfig でアプリケーションレベルで調整できます。たとえば、ジョブが 30 分ごとに実行される場合、アイドルタイムアウトを延長すると実行間の起動遅延を解消できます。
ほとんどのワークロードには、オンデマンドキャパシティが適しています。ジョブの要件に基づいてリソースを自動スケーリングし、アイドル時には課金されません。ETL ワークロード、バッチ処理ジョブ、最大限のジョブ回復力が必要なシナリオなど、一般的なユースケースに適したコスト効率の高いアプローチです。
即時起動が厳密に求められるワークロードには、オプションで事前初期化キャパシティを設定できます。事前初期化キャパシティは、数秒以内にジョブを実行できるドライバーとエグゼキューターのウォームプールを作成します。ただし、パフォーマンスが向上する分、コストは高くなります。事前初期化ワーカーはアプリケーションが停止状態になるまでアイドル中も継続的に課金されます。また、事前初期化キャパシティはジョブを単一のアベイラビリティゾーンに制限するため、回復力が低下します。
事前初期化キャパシティを検討すべきケース:
- 起動レイテンシーが許容できない、サブ秒の SLA 要件がある時間的制約の厳しいジョブ
- ユーザー体験が即時応答に依存するインタラクティブ分析
- 数分ごとに実行される高頻度の本番パイプライン
それ以外のほとんどのケースでは、オンデマンドキャパシティがコスト、パフォーマンス、回復力のバランスに優れています。
リソースの最適化に加えて、ワークロード全体でのアプリケーションの整理方法も検討してください。本番ワークロードでは、ビジネスドメインやデータの機密レベルごとに別々のアプリケーションを使用しましょう。アプリケーションを分離することでガバナンスが向上し、重要なジョブと重要でないジョブ間のリソース競合を防げます。
2. AWS Graviton プロセッサで価格性能比を向上
適切なプロセッサアーキテクチャの選択は、パフォーマンスとコストの両方に大きく影響します。Graviton ARM ベースプロセッサは、x86_64 と比較して優れた価格性能比を実現します。
EMR Serverless は最新のインスタンス世代が利用可能になると自動的に更新されるため、追加設定なしで最新のハードウェア改善の恩恵を受けられます。
EMR Serverless で Graviton を使用するには、CreateApplication でアプリケーション作成時に architecture パラメータで ARM64 を指定するか、既存のアプリケーションには UpdateApplication API を使用します:
Graviton 使用時の考慮事項:
- リソースの可用性 – 大規模ワークロードの場合、Graviton ワーカーのキャパシティプランニングについて AWS アカウントチームに相談することを検討してください。
- 互換性 – 一般的に使用される標準ライブラリの多くは Graviton (arm64) アーキテクチャと互換性がありますが、使用しているサードパーティパッケージやライブラリの互換性を検証する必要があります。
- 移行計画 – Graviton の導入には戦略的なアプローチを取りましょう。新しいアプリケーションはデフォルトで ARM64 アーキテクチャで構築し、既存のワークロードは中断を最小限に抑える段階的な移行計画で移行します。段階的に移行することで、信頼性を損なわずにコストとパフォーマンスを最適化できます。
- ベンチマークの実施 – 正確な価格性能比はワークロードによって異なります。ワークロード固有の結果を把握するために、独自のベンチマークを実施することを推奨します。詳細は「Achieve up to 27% better price-performance for Spark workloads with AWS Graviton2 on Amazon EMR Serverless」を参照してください。
3. デフォルトを活用し、必要に応じてワーカーを適正化
ワーカーはワークロードのタスクを実行するために使用されます。EMR Serverless のデフォルト設定はほとんどのユースケースに最適化されていますが、処理時間の改善やコスト効率の最適化のためにワーカーのサイズを適正化する必要がある場合があります。EMR Serverless ジョブを送信する際は、メモリサイズ (GB) やコア数などのワーカー設定を Spark プロパティで定義することを推奨します。
EMR Serverless のデフォルトワーカーサイズは 4 vCPU、16 GB メモリ、20 GB ディスクです。一般的にほとんどのジョブにバランスの取れた構成ですが、パフォーマンス要件に応じてサイズを調整することもできます。事前初期化ワーカーに特定のサイズを設定している場合でも、ジョブ送信時に必ず Spark プロパティを設定してください。事前初期化キャパシティを超えてスケールする際に、デフォルトプロパティではなく指定したワーカーサイズが使用されます。Spark ワークロードの適正化では、ジョブの vCPU:メモリ比率が重要です。エグゼキューターの仮想 CPU コアあたりに割り当てるメモリ量は、この比率で決まります。Spark エグゼキューターはデータを効果的に処理するために CPU とメモリの両方が必要で、最適な比率はワークロードの特性によって異なります。
まずは以下のガイダンスを参考にし、ワークロード固有の要件に基づいて設定を調整してください。
エグゼキューター設定
以下の表は、一般的なワークロードパターンに基づく推奨エグゼキューター設定です:
| ワークロードタイプ | 比率 | CPU | メモリ | 設定 |
|---|---|---|---|---|
| コンピューティング集約型 | 1:2 | 16 vCPU | 32 GB | spark.emr-serverless.executor.cores=16spark.emr-serverless.executor.memory=32G |
| 汎用 | 1:4 | 16 vCPU | 64 GB | spark.emr-serverless.executor.cores=16spark.emr-serverless.executor.memory=64G |
| メモリ集約型 | 1:8 | 16 vCPU | 108 GB | spark.emr-serverless.executor.cores=16spark.emr-serverless.executor.memory=108G |
ドライバー設定
以下の表は、一般的なワークロードパターンに基づく推奨ドライバー設定です:
| ワークロードタイプ | 比率 | CPU | メモリ | 設定 |
|---|---|---|---|---|
| 汎用 | 1:4 | 4 vCPU | 16 GB | spark.emr-serverless.driver.cores=4spark.emr-serverless.driver.memory=16G |
| Apache Iceberg ワークロード | 1:8 (メタデータルックアップ用の大きなドライバー) | 8 vCPU | 60 GB | spark.emr-serverless.driver.cores=8spark.emr-serverless.driver.memory=60G |
設定をさらにモニタリングおよびチューニングするには、Amazon CloudWatch ジョブワーカーレベルメトリクスでワークロードのリソース消費を監視し、ボトルネックを特定します。CPU 使用率、メモリ使用量、ディスク使用率のメトリクスを追跡し、以下の表を参考に設定を調整してください。
| 観測されたメトリクス | ワークロードタイプ | 推奨アクション | |
| 1 | 高メモリ (>90%)、低 CPU (<50%) | メモリバウンドワークロード | vCPU:メモリ比率を増加 |
| 2 | 高 CPU (>85%)、低メモリ (<60%) | CPU バウンドワークロード | vCPU 数を増加し、1:4 比率を維持 (例: 8 vCPU 使用時は 32 GB メモリ) |
| 3 | 高ストレージ I/O、通常の CPU/メモリ、長いシャッフル操作 | シャッフル集約型 | サーバーレスストレージまたはシャッフル最適化ディスクを有効化 |
| 4 | 全メトリクスで低使用率 | 過剰プロビジョニング | ワーカーサイズまたは数を削減 |
| 5 | 一貫して高使用率 (>90%) | 過少プロビジョニング | ワーカー仕様をスケールアップ |
| 6 | 頻繁な GC 一時停止** | メモリ圧迫 | メモリオーバーヘッドを増加 (10〜15%) |
**頻繁なガベージコレクション (GC) の一時停止は、Spark UI の Executors タブで確認できます。GC time 列があり、一般的にタスク時間の 10% 未満であるべきです。また、ドライバーログに GC (Allocation Failure)] メッセージが頻繁に含まれている場合もあります。
4. T シャツサイジングでスケーリング境界を制御
デフォルトでは、EMR Serverless は動的リソース割り当て (DRA) を使用し、ワークロードの需要に基づいてリソースを自動スケーリングします。EMR Serverless はジョブのメトリクスを継続的に評価してコストと速度を最適化するため、必要なワーカー数を見積もる必要がありません。
コスト最適化と予測可能なパフォーマンスのために、以下のいずれかのアプローチでスケーリングの上限を設定できます:
- ジョブレベルで spark.dynamicAllocation.maxExecutors パラメータを設定
- アプリケーションレベルの最大キャパシティを設定
各ジョブの spark.dynamicAllocation.maxExecutors を個別に細かく調整するのではなく、ワークロードプロファイルを表す T シャツサイズとして設定を考えることができます:
| ワークロードサイズ | ユースケース | spark.dynamicAllocation.maxExecutors |
|---|---|---|
| Small | 探索的クエリ、開発 | 50 |
| Medium | 定期的な ETL ジョブ、レポート | 200 |
| Large | 複雑な変換、大規模処理 | 500 |
この T シャツサイジングアプローチにより、キャパシティプランニングが簡素化され、個々のジョブを最適化するのではなく、ワークロードカテゴリに基づいてパフォーマンスとコスト効率のバランスを取れます。
EMR Serverless リリース 6.10 以降では、spark.dynamicAllocation.maxExecutors のデフォルト値は無制限ですが、それ以前のリリースでは 100 です。
EMR Serverless はジョブの各ステージで必要なワークロードと並列性に基づいて、ワーカーを自動的にスケールアップまたはスケールダウンします。ジョブのメトリクスを継続的に評価してコストと速度を最適化するため、ワーカー数を見積もる必要がありません。
ただし、予測可能なワークロードの場合、エグゼキューター数を静的に設定したい場合があります。その場合は DRA を無効にしてエグゼキューター数を手動で指定します:
5. EMR Serverless ジョブに適切なストレージをプロビジョニング
ストレージオプションを理解し、適切にサイジングすることで、ジョブの失敗を防ぎ、実行時間を最適化できます。EMR Serverless は、ジョブ実行中の中間データを処理するストレージオプションが複数あります。選択するストレージオプションは EMR リリースとユースケースによって異なります。EMR Serverless で利用可能なストレージオプションは以下のとおりです:
| ストレージタイプ | EMR リリース | ディスクサイズ範囲 | ユースケース | メリット |
|---|---|---|---|---|
| サーバーレスストレージ (推奨) | 7.12+ | N/A (自動スケーリング) | ほとんどの Spark ワークロード、特にデータ集約型ワークロード |
|
| 標準ディスク | 7.11 以前 | ワーカーあたり 20〜200 GB | 10 TB 未満のデータセットを処理する小〜中規模ワークロード |
|
| シャッフル最適化ディスク | 7.1.0+ | ワーカーあたり 20〜2,000 GB | マルチ TB を処理する大規模 ETL ワークロード |
|
ストレージ設定をワークロードの特性に合わせることで、EMR Serverless ジョブを大規模でも効率的かつ安定的に実行できます。
6. マルチ AZ がデフォルトで組み込みの回復力を提供
EMR Serverless アプリケーションは、事前初期化キャパシティが有効でない場合、最初からマルチ AZ です。フェイルオーバーが組み込まれているため、手動操作なしで AZ 障害に対応できます。単一のジョブは単一のアベイラビリティゾーン内で動作し、クロス AZ データ転送コストを防ぎます。後続のジョブは複数の AZ に適切に分散されます。EMR Serverless が AZ の障害を検出すると、新しいジョブを正常な AZ に送信し、AZ 障害にもかかわらずワークロードの実行を継続できます。
EMR Serverless のマルチ AZ 機能を最大限に活用するには、以下を確認してください:
- 複数のアベイラビリティゾーンにまたがるサブネットを選択して VPC へのネットワーク接続を設定
- アプリケーションを単一の AZ に制限する事前初期化キャパシティを避ける
- ワーカーのスケーリングをサポートするために各サブネットに十分な IP アドレスがあることを確認
マルチ AZ に加えて、Amazon EMR 7.1 以降ではジョブの回復力を有効にでき、エラーが発生した場合にジョブを自動的にリトライできます。複数のアベイラビリティゾーンが設定されている場合、別の AZ でもリトライされます。この機能はバッチジョブとストリーミングジョブの両方で有効にできますが、リトライ動作は両者で異なります。
最大リトライ回数を定義するリトライポリシーを指定してジョブの回復力を設定します。バッチジョブのデフォルトは自動リトライなし (maxAttempts=1) です。ストリーミングジョブでは、EMR Serverless は無制限にリトライし、1 時間以内に 5 回失敗するとリトライを停止するスラッシング防止機能が組み込まれています。このしきい値は 1〜10 回の間で設定できます。詳細は「Job resiliency」を参照してください。
ジョブをキャンセルする必要がある場合、デフォルトの即時終了ではなく、ジョブをクリーンにシャットダウンするための猶予期間を指定できます。カスタムクリーンアップアクションを実行する必要がある場合は、カスタムシャットダウンフックも含められます。
マルチ AZ サポート、自動ジョブリトライ、グレースフルシャットダウン期間を組み合わせることで、中断に耐え、手動操作なしでデータの整合性を維持できる EMR Serverless ワークロードを構築できます。
7. VPC 統合でセキュリティと接続性を拡張
デフォルトでは、EMR Serverless は Amazon Simple Storage Service (Amazon S3)、AWS Glue、Amazon CloudWatch Logs、AWS Key Management Service (AWS KMS)、AWS Security Token Service (AWS STS)、Amazon DynamoDB、AWS Secrets Manager などの AWS サービスにアクセスできます。Amazon Redshift や Amazon Relational Database Service (Amazon RDS) など VPC 内のデータストアに接続するには、EMR Serverless アプリケーションの VPC アクセスを設定する必要があります。
EMR Serverless アプリケーションの VPC アクセスを設定する際は、最適なパフォーマンスとコスト効率のために以下の考慮事項に留意してください:
- 十分な IP アドレスを計画 – 各ワーカーはサブネット内で 1 つの IP アドレスを使用します。ジョブのスケールアウト時に起動されるワーカーも含まれます。IP アドレスが不足すると、ジョブがスケールできず、ジョブの失敗につながる可能性があります。最適なパフォーマンスのためにサブネットプランニングのベストプラクティスに従っていることを確認してください。
- プライベートサブネットのアプリケーションには Amazon S3 用ゲートウェイエンドポイントを設定 – VPC エンドポイントなしでプライベートサブネットで EMR Serverless を実行すると、Amazon S3 トラフィックが NAT ゲートウェイ経由でルーティングされ、追加のデータ転送料金が発生します。S3 用 VPC エンドポイントにより、トラフィックを VPC 内に保持し、コストを削減して Amazon S3 操作のパフォーマンスを向上できます。
- ネットワークインターフェースの AWS Config コストを管理 – EMR Serverless は各ワーカーに対して AWS Config にエラスティックネットワークインターフェースレコードを生成し、ワークロードのスケールに伴いコストが蓄積される可能性があります。EMR Serverless ネットワークインターフェースの AWS Config 追跡が不要な場合は、リソースベースの除外やタグ付け戦略を使用してフィルタリングし、他のリソースの AWS Config カバレッジは維持することを検討してください。
詳細は「Configuring VPC access for EMR Serverless applications」を参照してください。
8. ジョブ送信と依存関係管理を簡素化
EMR Serverless は StartJobRun API による柔軟なジョブ送信をサポートしており、完全な spark-submit 構文を受け付けます。ランタイム環境の設定には、spark.emr-serverless.driverEnv と spark.executorEnv プレフィックスを使用して、ドライバーとエグゼキュータープロセスの環境変数を設定します。機密設定やランタイム固有の設定を渡す際に特に便利です。
Python アプリケーションの場合、venv を作成し、tar.gz アーカイブとしてパッケージ化するか、spark.archives を使用して Amazon S3 にアップロードし、適切な PYSPARK_PYTHON 環境変数を設定して、仮想環境で依存関係をパッケージ化すると、ドライバーとエグゼキューターワーカー全体で Python の依存関係を利用できます。
高負荷時の制御を向上させるには、ジョブの同時実行とキューイング (EMR 7.0.0+ で利用可能) を有効にして、同時に実行できるジョブ数を制限します。この機能により、同時実行制限を超えて送信されたジョブは、リソースが利用可能になるまでキューに入れられます。
ジョブの同時実行とキュー設定は、CreateApplication または UpdateApplication API の SchedulerConfiguration プロパティで設定できます。
--scheduler-configuration '{"maxConcurrentRuns": 5, "queueTimeoutMinutes": 30}'
9. EMR Serverless の設定で制限を適用
EMR Serverless はワークロードの需要に基づいてリソースを自動スケーリングし、ほとんどのユースケースで Spark 設定のチューニングなしで機能する最適化されたデフォルトが用意されています。コスト管理のために、予算とパフォーマンス要件に合ったリソース制限を設定できます。高度なユースケースでは、リソース消費を細かく調整し、クラスターベースのデプロイメントと同等の効率を実現する設定オプションも提供しています。制限を適切に設定することで、パフォーマンスとコスト効率のバランスを取れます。
| 制限タイプ | 目的 | 設定方法 |
|---|---|---|
| ジョブレベル | 個々のジョブのリソースを制御 | spark.dynamicAllocation.maxExecutors または spark.executor.instances |
| アプリケーションレベル | アプリケーションまたはビジネスドメインごとのリソースを制限 | アプリケーション作成時または更新時に最大キャパシティを設定 |
| アカウントレベル | 全アプリケーションにわたる異常なリソーススパイクを防止 | 自動調整可能なサービスクォータ「Max concurrent vCPUs per account」。Service Quotas コンソールから引き上げをリクエスト |
これら 3 つのレイヤーの制限が連携して、異なるスコープで柔軟にリソースを管理できます。ほとんどのユースケースでは、T シャツサイジングアプローチによるジョブレベルの制限設定で十分であり、アプリケーションレベルとアカウントレベルの制限はコスト管理の追加的なガードレールになります。
10. CloudWatch、Prometheus、Grafana でモニタリング
EMR Serverless ワークロードのモニタリングにより、デバッグ、コスト最適化、パフォーマンス追跡が容易になります。EMR Serverless は連携する 3 つのモニタリング階層があります: Amazon CloudWatch、Amazon Managed Service for Prometheus、Amazon Managed Grafana です。
- Amazon CloudWatch – CloudWatch 統合はデフォルトで有効になっており、AWS/EMRServerless 名前空間にメトリクスを発行します。EMR Serverless はアプリケーションレベル、ジョブ、ワーカータイプ、キャパシティ割り当てタイプレベルで毎分 CloudWatch にメトリクスを送信します。CloudWatch を使用して、ワークロードの可観測性を高めるダッシュボードを設定したり、ジョブの失敗、スケーリングの異常、SLA 違反に対するアラームを設定できます。CloudWatch と EMR Serverless を使用することで、ユーザーに影響が出る前に問題を検知できます。
- Amazon Managed Service for Prometheus – EMR Serverless リリース 7.1+ では、Prometheus を有効にして詳細な Spark エンジンメトリクスを Amazon Managed Service for Prometheus にプッシュでき、メモリ使用量、シャッフルボリューム、GC 圧力などエグゼキューターレベルで可視化できます。メモリ制約のあるエグゼキューターの特定、シャッフルが多いステージの検出、データスキューの発見に活用できます。
- Amazon Managed Grafana – Grafana は CloudWatch と Prometheus の両方のデータソースに接続し、可観測性と相関分析を統合した単一画面として利用できます。3 つの階層を組み合わせることで、インフラストラクチャの問題とアプリケーションレベルのパフォーマンス問題を関連付けられます。
追跡すべき主要メトリクス:
- ジョブの完了時間と成功率
- ワーカーの使用率とスケーリングイベント
- シャッフルの読み取り/書き込みボリューム
- メモリ使用パターン
詳細は「Monitor Amazon EMR Serverless workers in near real time using Amazon CloudWatch」を参照してください。
まとめ
本記事では、パフォーマンスの最適化、コスト管理、大規模での安定した運用を実現するための Amazon EMR Serverless のベストプラクティス 10 選を紹介しました。アプリケーション設計、ワークロードの適正化、アーキテクチャの選択に注力することで、効率的で回復力のあるデータ処理パイプラインを構築できます。
詳細は「Getting started with EMR Serverless」ガイドを参照してください。
著者について
この記事は Kiro が翻訳を担当し、Solutions Architect の Woosuk Choi がレビューしました。