AWS Storage Blog
Build intelligent ETL pipelines using AWS Model Context Protocol and Amazon Q
Data scientists and engineers spend hours writing complex data pipelines to extract, transform, and load (ETL) data from various sources into their data lakes for data integration and creating unified data models to build business insights. The process involves understanding the source and target systems, discovering schemas, mapping source and target, writing and testing ETL scripts, and finally scheduling and monitoring the pipeline. Today, this whole development process is mostly done manually, leading to delayed insights and reduced productivity.
Traditionally, data engineers have built the ETL pipelines from scratch using Amazon Web Services (AWS) services such as AWS Glue, Amazon EMR, and Amazon Managed Workflows for Apache Airflow (MWAA), to move and transform data between different internal and external data sources such as Amazon Redshift, Amazon S3 data lakes, Amazon S3 Tables, and self-managed operational databases such as PostgreSQL or MySQL. You can now use agentic AI applications and Model Context Protocol (MCP) servers to build the same pipelines with reduced engineering effort using conversational AI while maintaining security best practices. MCP is an open protocol that enables seamless integration between large language model (LLM)-based applications and external data sources and tools. Whether you’re building an AI-powered integrated development environment (IDE), enhancing a chat interface, or creating custom AI workflows, MCP provides a standardized way to connect LLMs with the context they need. Using conversational AI with the AWS MCP servers can solve the data pipeline development complexities by using conversational interactions with AWS services to build the end-to-end ETL pipelines much more quickly, increasing productivity while maintaining security standards and best practices.
In this post, we implement two use cases using conversational AI and share our lessons learned and best practices on how you can replicate the same for your organization.
- Data scientists use conversational AI to extract specific datasets for analysis without writing complex queries. The AI understands the request and generates the code, making one-time data extraction tasks clear and quick.
- Data engineers streamline the creation of ETL pipelines that move data from Redshift to S3 Tables to implement fully managed Apache Iceberg for integration of Redshift data with an organization’s data lake and provide a cost effective, performant and scalable solution for on-demand queries. This process of defining transformations and setting up data flows is streamlined through a conversational interface and reduces development time and maintenance.
Solution overview
To showcase the use cases discussed in the previous section, we use Visual Studio code editor and Amazon Q Developer. We install the Redshift MCP Server, AWS Data Processing MCP Server, and S3 Tables MCP Server. The following is the list of activities we demonstrate in this post:
- List and analyze storage resources by retrieving available S3 buckets and Redshift Serverless workgroups in your AWS environment.
- Create the S3 bucket. Verify that the S3 bucket’s setup and access controls are in line with your organization’s security best practices.
- Explore the Redshift database schemas and table structures, providing detailed information about columns, data types, and relationships within specified workgroups.
- Access and preview Redshift table contents efficiently, allowing quick data validation and exploration using AI-guided queries.
- Generate and execute optimized SQL queries for data analysis, with AI assisting in creating complex JOINs, filters, and aggregations to derive meaningful insights.
- Facilitate seamless data export from Redshift to S3 using UNLOAD commands, automatically handling CSV formatting, compression, and file partitioning based on data volume.
- Navigate through exported data by listing S3 bucket contents, validating CSV file structures, and retrieving sample data for verification, all through natural language interactions.
- Load the data into S3 Tables.
- Validate the migration and query the data.
- Create a reusable script for production migration.
Each capability integrates with MCP servers to provide context-aware, intelligent data processing that understands and adapts to specific business requirements while maintaining security and performance best practices.
Prerequisites
Set up the appropriate AWS Identity and Access Management (IAM) roles and permissions and handle delete and table maintenance operations separately. This is because these tasks are not exposed through the Redshift, data processing, and S3 Tables MCP Servers.
To get started with the MCP Server, we set up these prerequisites:
- An AWS account.
- Install AWS Command Line Interface (AWS CLI) version 2.27 and set up credentials.
- Install Q extension in Visual Studio (1.85.0 and above).
- For installing each MCP server, choose the following link, go to the Installation section of the page, and choose Install on VS Studio. This opens VS Code and configures the MCP server. Choose save configuration.
- Install Redshift MCP Server.
- Install S3 Tables MCP Server.
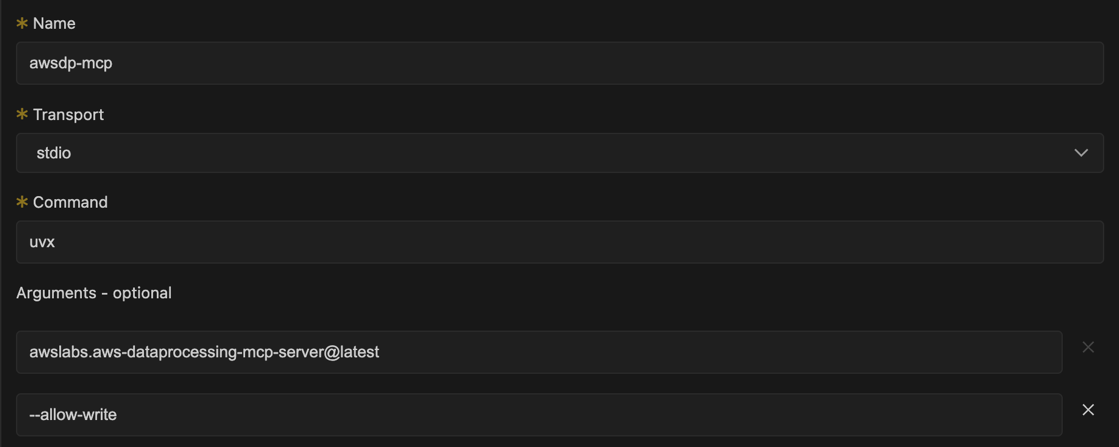
- Install Data Processing MCP. Make sure that in Arguments you have –allow-write, as shown in the following figure:
- Create a new Amazon Redshift Serverless or use an existing non-production one for testing.
End-to-end demo workflow
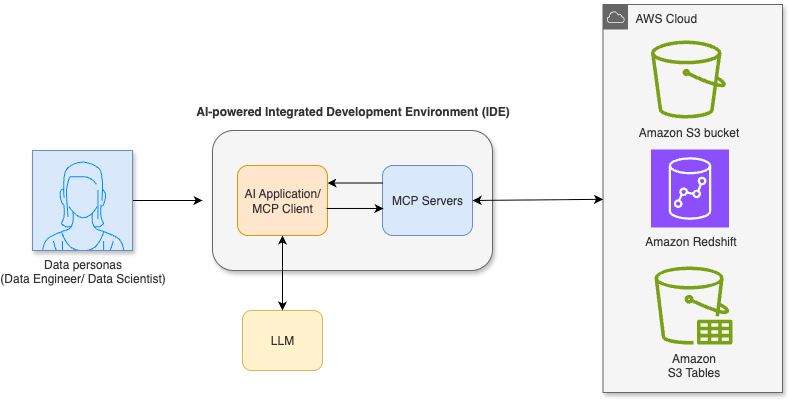
Both use case examples show how conversational AI replaces traditional coding methods, making data tasks efficient. The following architecture diagram shows the high-level workflow used in both use cases and how different components interact with each other.
Use case 1: Loading data into a general purpose S3 bucket
A data scientist urgently needs order data from Redshift for a high-priority project. Instead of writing traditional code or waiting for the data engineers, they decide to use AI tools to extract and transfer the data to an S3 bucket, thereby saving time and effort.
First, we create the destination S3 bucket. We highly recommend verifying that the S3 bucket’s setup and access controls are in line with your organization’s security best practices. In the following prompts, replace “<your AWS account number>” with your AWS account number.
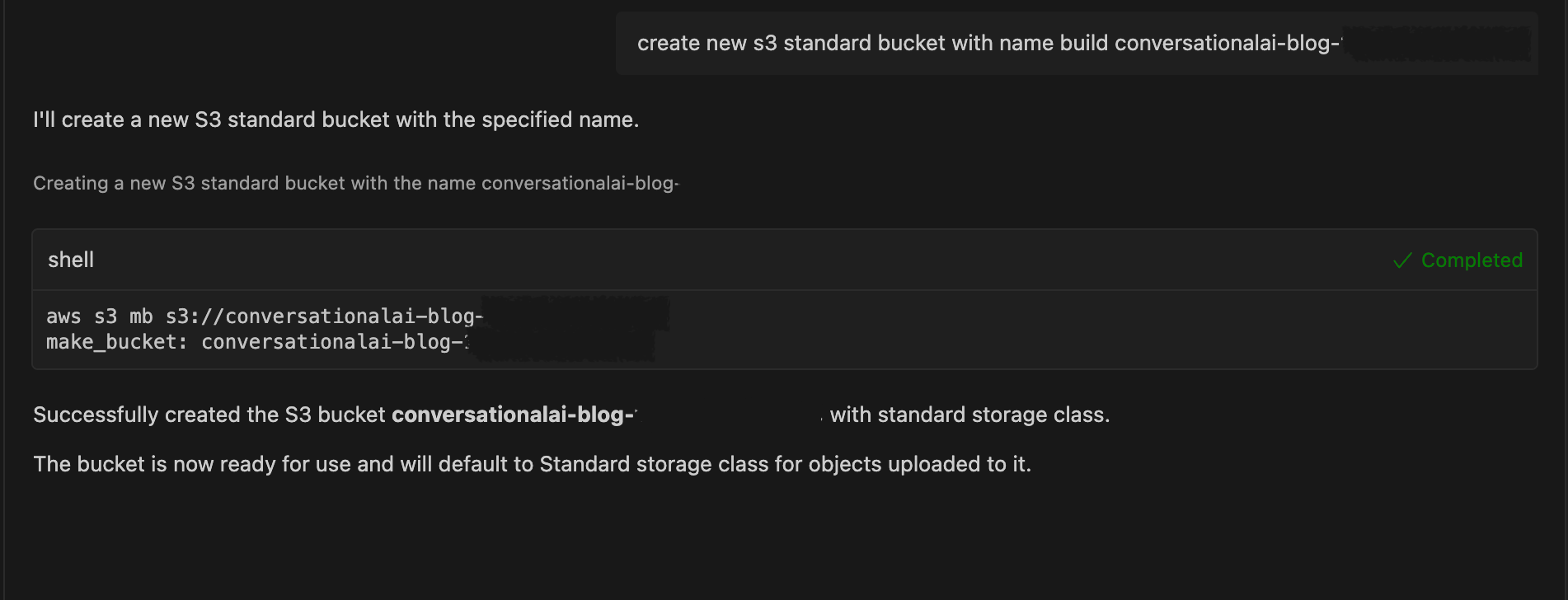
Prompt: create new s3 standard bucket with name build conversationalai-blog-1-<<your AWS account number>>
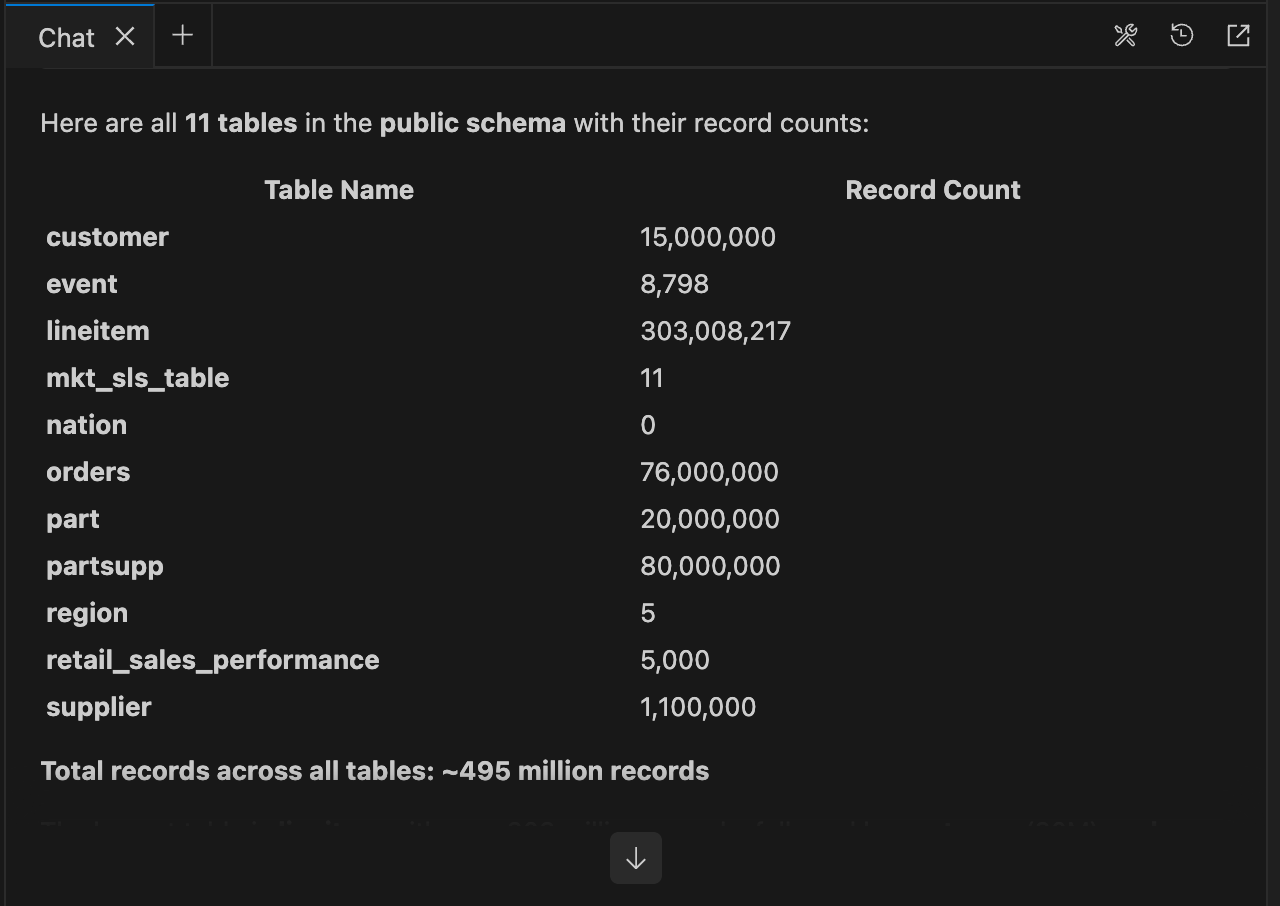
1. List Redshift tables.
Prompt: list all tables in public schema and count the number of records in each table
2. Sample a few records in the table.
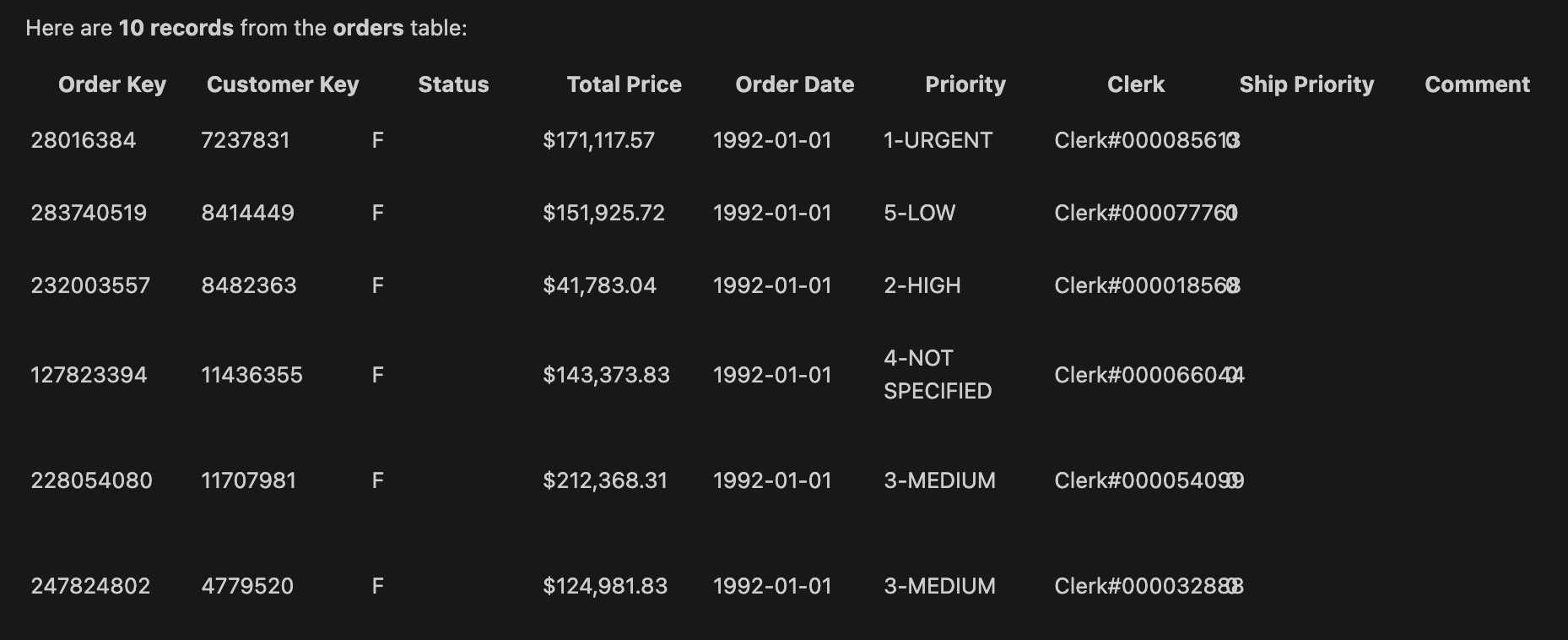
Prompt: list 10 records from orders table
3. Join the Customer and Order table on the custkey column. Filter on order priority columns to include only ‘1-URGENT’, ‘2-HIGH’, or ‘3-MEDIUM’ priorities, and extract the data to the S3 location.
Prompt: Using the Redshift UNLOAD command, extract and export order details and customer information data where order priority is ‘1-URGENT’, ‘2-HIGH’, or ‘3-MEDIUM’ into CSV file format, then store the output in the S3 bucket ‘conversationalai-blog-1-<<your AWS account number>>’, ensuring all relevant order and customer data fields are included in the export.
4. Verify that the data is unloaded to the S3 bucket.
Prompt: list a few records data files in conversationalai-blog-1-<<your AWS account number>> bucket
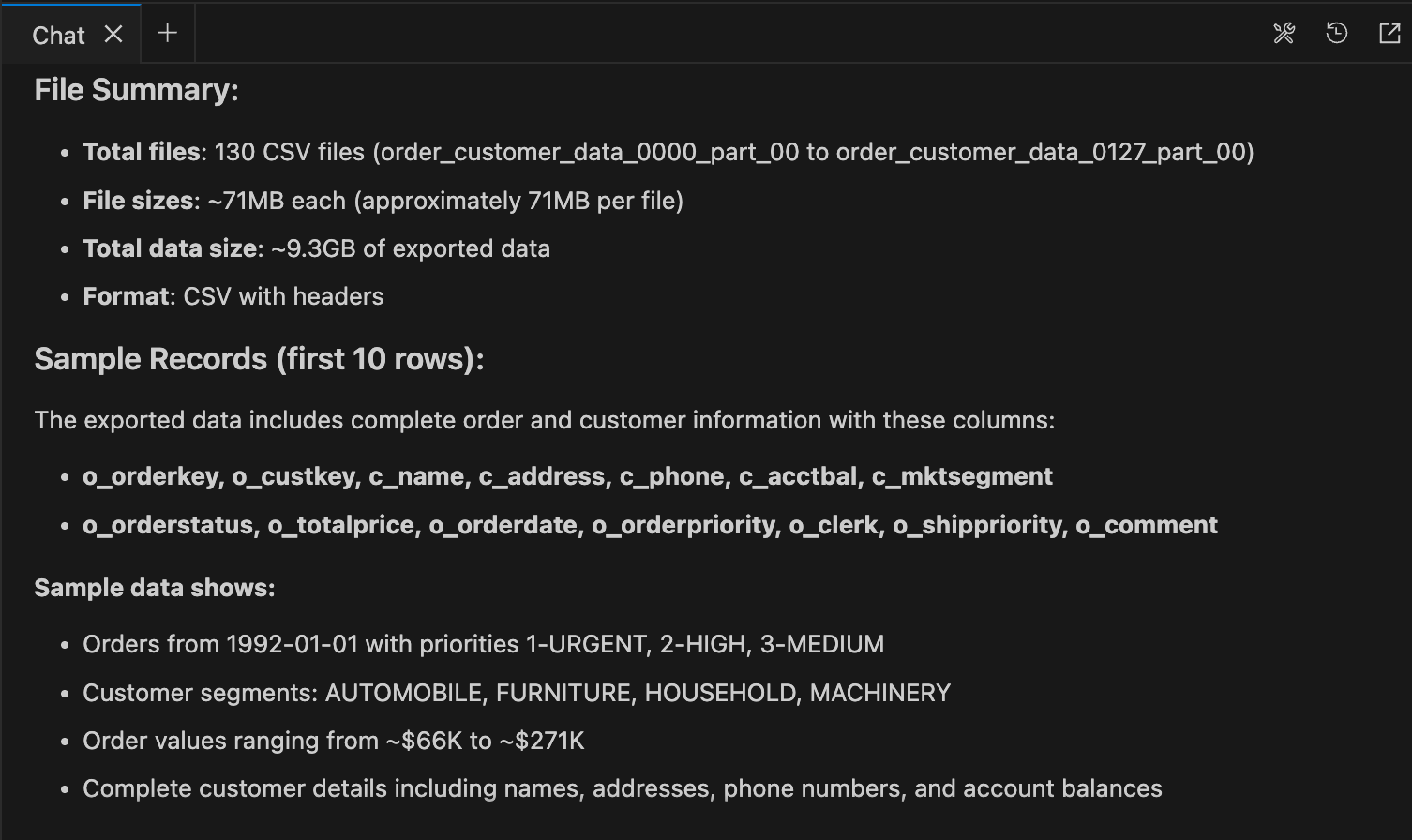
5. Conduct a quality check.
Prompt: do a quality check on the data in the bucket conversationalai-blog-1-<<your AWS account number>> and save the report to another s3 bucket: conversationalai-blog-<<your AWS account number>>
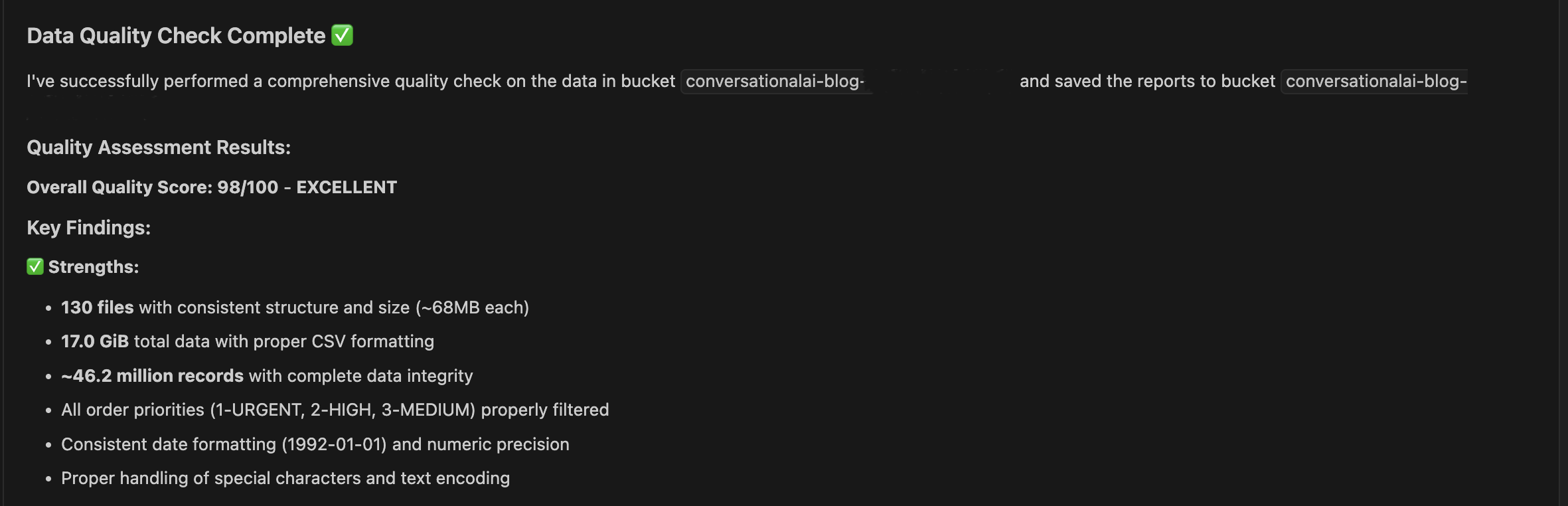
The following are the details for Data Validation and Reports Generated for data quality.
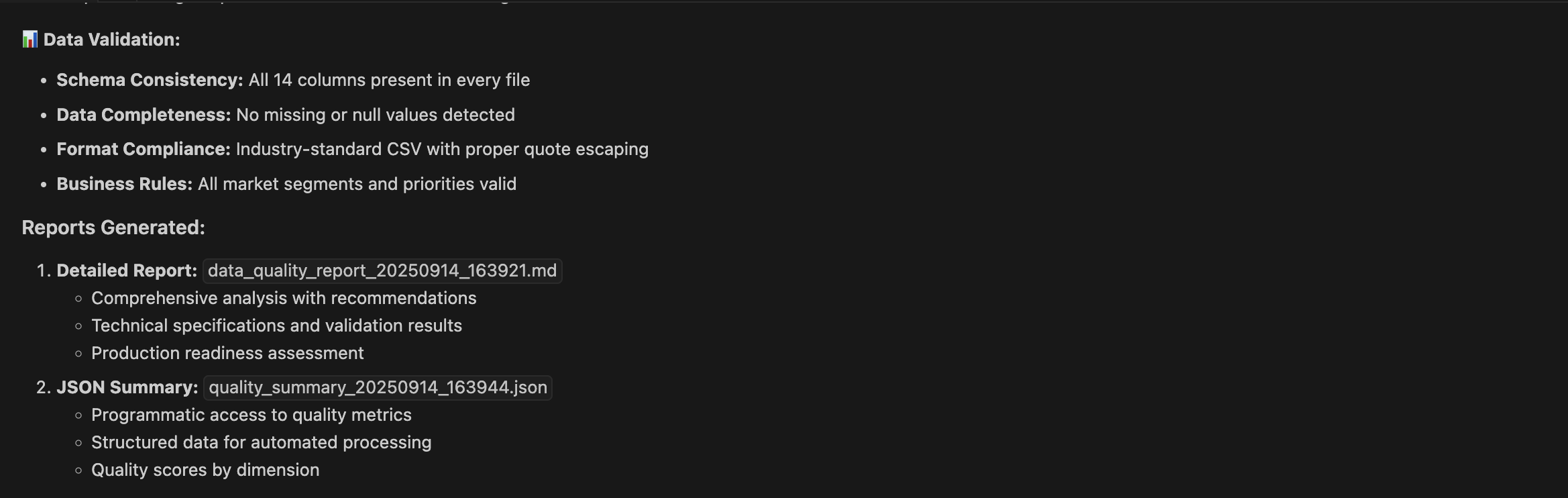
The following are details of recommendations for production use.

6. After running quality checks, the data scientist confirms the data meets their standards and notifies the team that it’s ready for analysis.
Use case 2: Migrate to Amazon S3 Tables
Using conversational AI, data engineers can quickly build ETL pipelines from Redshift to S3 Tables. The AI generates parameterized scripts suitable for production use, making large-scale data migrations efficient and improving developer productivity.
The following figure shows an architecture diagram of the ETL pipeline that you build in this use case.
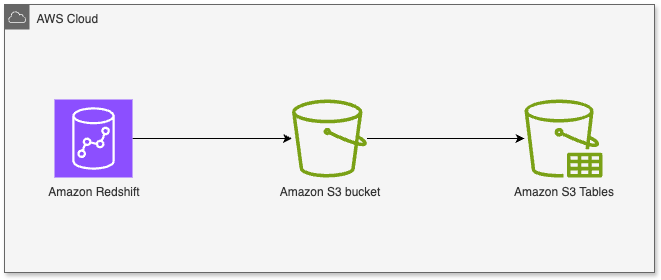
1. First, create S3 tables, which are the destination for the order customer data that you extracted from Redshift in the first use case.
Prompt: Create a new S3 table bucket called order-customer-data-blog with namespace ns_ order_customer_data_blog

2. Import the order customer data that you extracted from Redshift to the S3 bucket in the first use case into the S3 Tables.
Prompt: Import all files beginning with ‘order_customer_data’ into namespace ‘ns_order_customer_data_blog’ from S3 bucket ‘conversationalai-blog-1-<<your AWS account number>>’
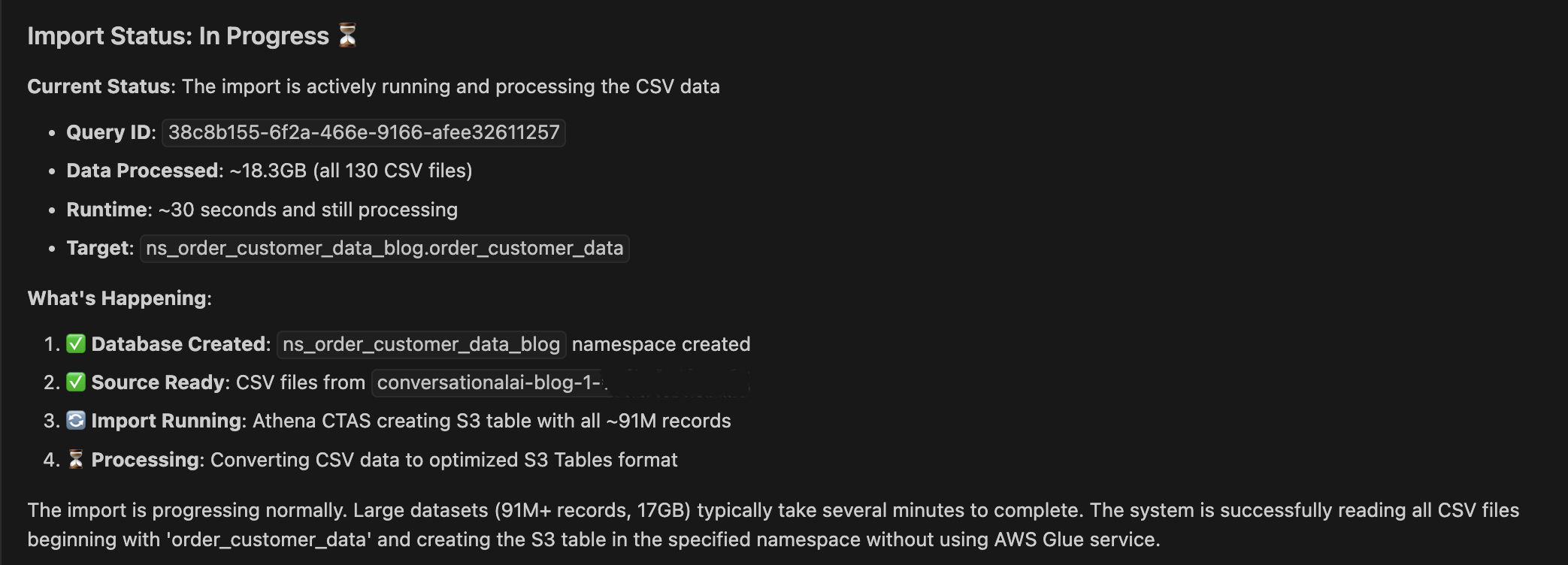
3. Verify the import is complete.
Prompt: check if import completed

4. Test if the records are loaded successfully by sampling records.
Prompt: sample a few records
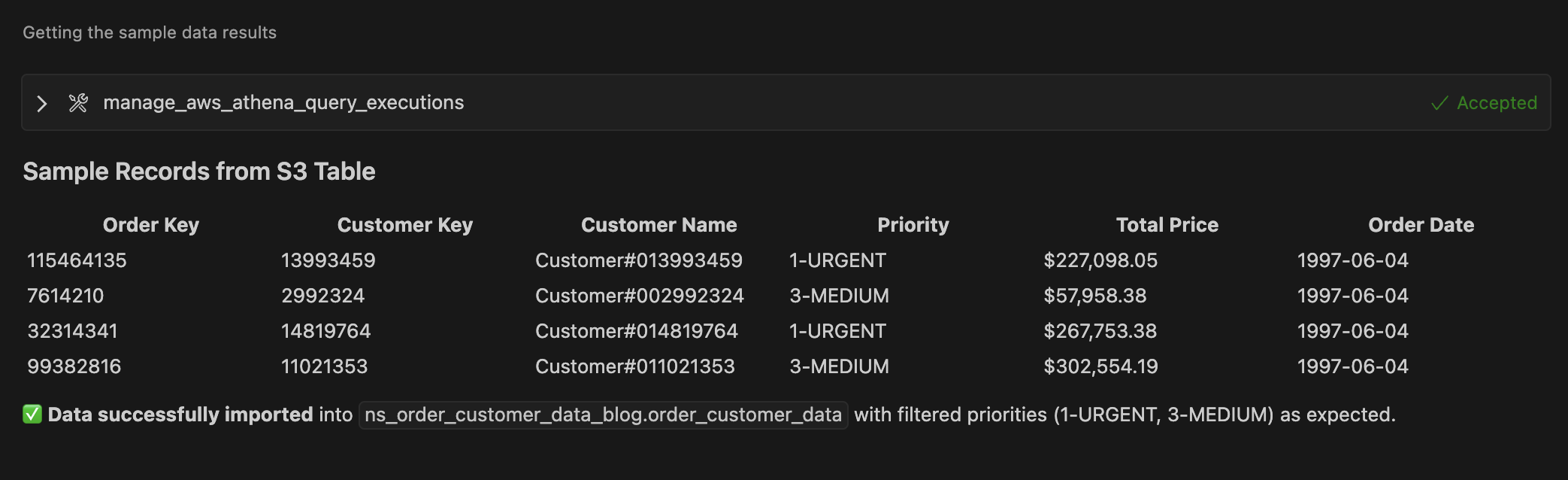
5. In the final step, data engineers create parameterized PySpark scripts for production use cases. Verify all AI-generated code before using it to make sure of result accuracy, security, and performance.
Prompt: Create a PySpark script that takes order date as a parameter and imports ‘order_customer_data*’ files from S3 bucket ‘conversationalai-blog-1-<<your AWS account number>>’ into namespace ‘ns_order_customer_data_blog’, and save the script to the bucket’s script folder.
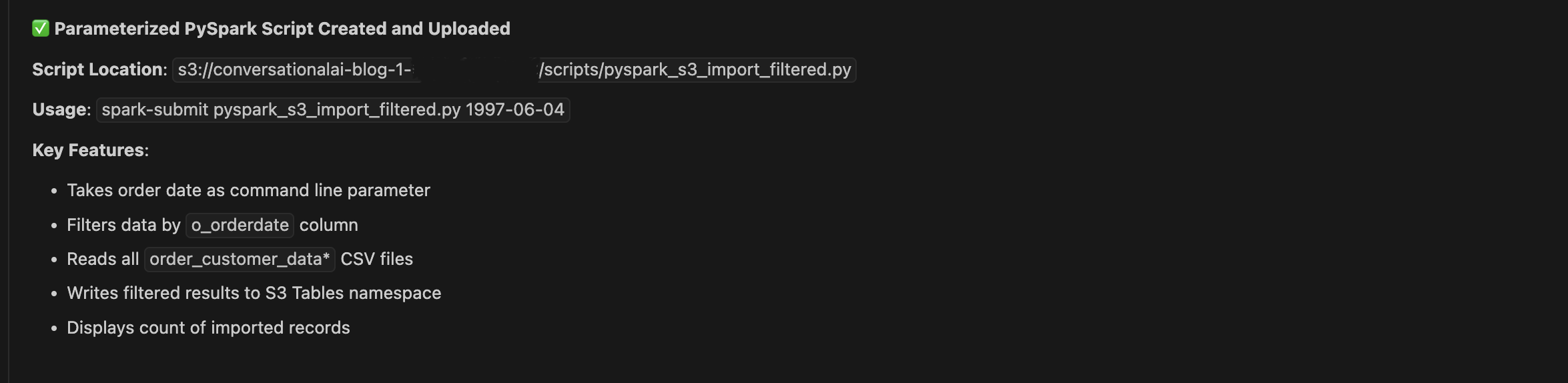
Based on the preceding prompt, the AI agent creates the following PySpark script:
import sys
from pyspark.sql import SparkSession
from pyspark.sql.functions import col
# Get order date parameter
if len(sys.argv) != 2:
print("Usage: script.py <order_date>")
sys.exit(1)
order_date = sys.argv[1]
# Initialize Spark with S3 Tables support
spark = SparkSession.builder \
.appName("ImportOrderCustomerDataFiltered") \
.config("spark.sql.extensions", "org.apache.iceberg.spark.extensions.IcebergSparkSessionExtensions") \
.config("spark.sql.catalog.spark_catalog", "org.apache.iceberg.spark.SparkSessionCatalog") \
.config("spark.sql.catalog.spark_catalog.type", "hive") \
.getOrCreate()
# Read CSV files from S3
df = spark.read \
.option("header", "true") \
.option("inferSchema", "true") \
.csv("s3://conversationalai-blog-1-<<your AWS account number>>/order_customer_data*")
# Filter by order date
filtered_df = df.filter(col("o_orderdate") == order_date)
# Write to S3 Tables namespace
filtered_df.write \
.format("iceberg") \
.mode("overwrite") \
.saveAsTable("ns_order_customer_data_blog.order_customer_data")
print(f"Imported {filtered_df.count()} records for order date: {order_date}")
spark.stop()Considerations
Although AI agents could reduce the ETL development cycle by automating the process using natural language, the following best practices should be considered to conform to the data accuracy, governance, and security standards of your organization before any production implementation.
- Prompt engineering excellence
- Be precise and explicit in writing AI prompts
- Structure prompts with clear context and expected deliverables
- Test and iterate prompts for optimal results
- Break complex requirements into manageable chunks
- Security first mindset
- Strictly follow the principle of least privilege for IAM roles
- Only grant minimum necessary permissions for specific tasks
- Regularly audit access controls and permissions
- Never compromise security for convenience
- Data validation and quality control
- Always validate AI-generated code before production deployment
- Implement thorough testing of data transformations
- Validate data consistency and accuracy
- Double-check generated SQL queries for optimization
These three fundamental lessons prove to be the most critical to project success. Precise prompt engineering reduced development time and improved accuracy. Security best practices protected sensitive data while enabling necessary access. Manual validation made sure of reliable and accurate data processing, maintaining high data quality standards throughout the pipeline.
Cleaning up
To avoid incurring future charges, clean up the resources that you created during this walkthrough. You may also use AWS CLI for deletion.
- Delete the S3 buckets and S3 Tables created for testing this solution.
- Delete any other infrastructure that you created for this experiment.
Conclusion
In this post, we showcased how combining modern AI tools with traditional data processing can make complex tasks much clearer and faster. We used generative AI and MCP servers alongside Amazon Redshift and Amazon S3 to transform what used to be days of coding work into a streamlined process that only takes hours to complete.
This new approach saves time and completely changes how we handle data. We allow AI to help us understand and process information more naturally to create a system that’s more efficient. The result is a solution that makes business data more accessible and analyzable, while setting up a framework that can be reused for future projects. It’s a practical example of how AI is making data engineering more accessible and efficient, proving that technology can streamline even the most complex data challenges.