- AWS Builder Center›
- builders.flash
はじめに
こんにちは。株式会社メタップス SRE チーフエンジニアの山北と申します。
メタップスではファイナンスやマーケティング、DX 支援といった領域で、さまざまなプロダクトを展開しています。開発チームはプロダクトごとに配置されますが、これらのサービスのインフラを横断して運用しているのが SRE チームです。
メタップスでの SRE チームの立ち上げは 2018 年となり、インフラストラクチャのコード化を始め、サービスの監視体制やマイクロサービス移行、スケーケテビリィ改善、デプロイ戦略 など多岐に渡る改善を推進してきました。
SRE メンバーはまだ少数のため、SLO の運用やセキュリティ施策など課題は多々ある状況ですが、今回はその中で、インフラ基盤を監視する上で見えてきた課題や、改善施策に取り組んでいる話をしたいと思います。
これまでのシステム監視における課題
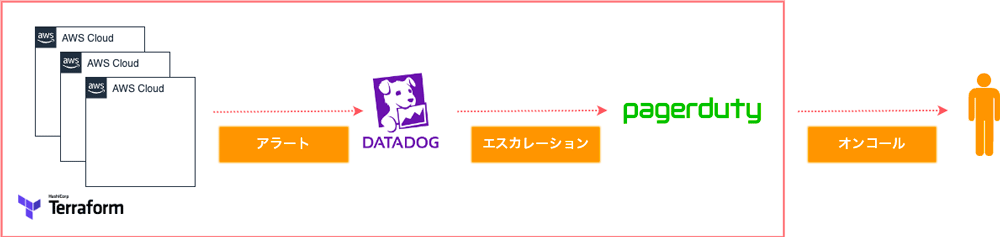
メタップスではインフラ基盤の監視に Datadog を採用しており、利用者への影響があれば PagerDuty にエスカレーションし、オンコール担当エンジニアが対応する流れとなっています。
AWS や Datadog のアカウントはプロダクトごとに分離されていますが、各プロダクトのアーキテクチャはそこまで大きく変わらないため、インフラ基盤のコード化には Terraform を採用しました。
Datadog の監視項目は、CPU やメモリのしきい値をはじめ、ロードバランサーのレイテンシーやディスクの IOPS、ネットワーク I/O など多岐に渡ります。プロダクトごとに約 50 のモニターが設定され、一定のしきい値を超えたアラートは Slack に通知する仕組みを構築しました。
この運用はプロダクト数が少ないうちは上手く回っていましたが、エンジニア一人が 3〜4 のプロダクトを見始めると、アラートの取りこぼしや異常データの早期発見が難しくなるという課題が生じました。
運用自動化への取り組み
SRE エンジニアはシステムアラートが発生していない日々の時間に、開発チームからの要望やインフラ基盤の改善に取り組んでいます。
その中の一つに運用自動化 (トイルの削減) があります。トイルの例としては、次のようなものが上げられます。
-
EC2 インスタンスへの定期的なセキュリティパッチの適用
-
一定期間を経過したアプリケーションログの削除
-
AWS Config コンプライアンス違反通知の精査
-
許可されていない API コールの調査
一つひとつのタスクはそれほど重くありませんが、プロダクトが増えるにつれ、これらの対応はエンジニアの負担となっていきました。
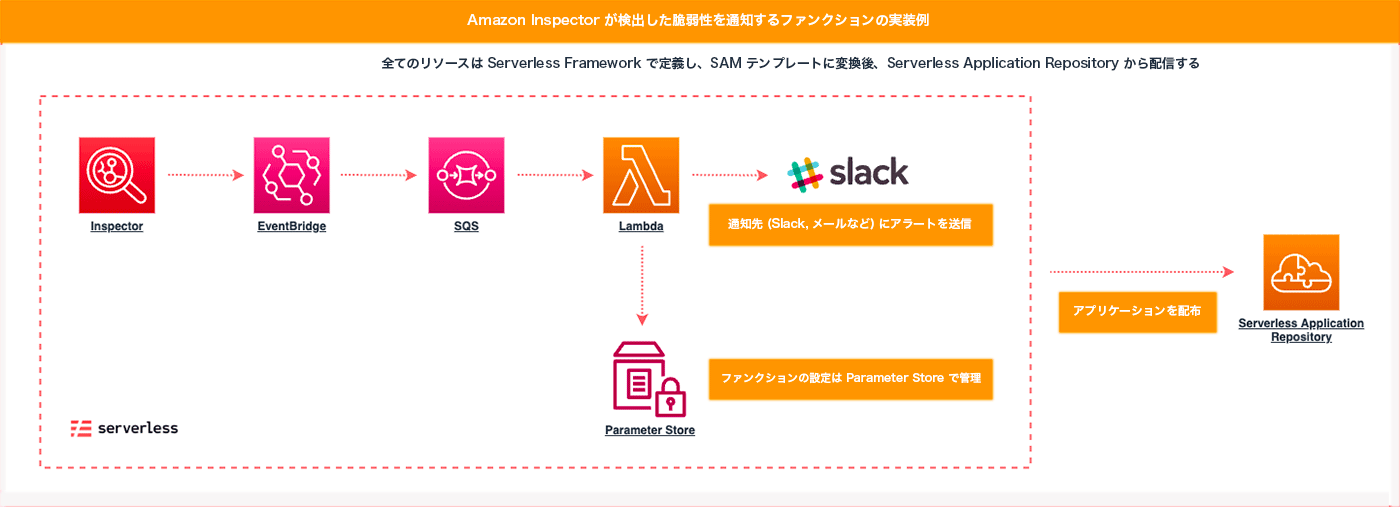
そこでタスク解決のための軽量な AWS Lambda ファンクションを個々に実装し、AWS Serverless Application Repository からパッケージを配布する仕組みを構築しました。
サーバーレスを活用した仕組み
AWS Serverless Application Repository は、サーバーレスアプリケーションを構築するためのフレームワークである AWS SAM をベースに、開発者が実装したアプリケーションを任意の AWS アカウントに配布する仕組みを提供します。
アプリケーションのデプロイには AWS CloudFormation が使われるため、利用者側でデプロイをコード管理することもでき、アプリケーションのバージョンアップも容易となるメリットがあります。
メタップスではサーバーレスアプリケーションの開発基盤として Serverless Framework を利用しているため、Serverless Application Repository にアプリケーションを登録するには、リソースの定義を SAM 形式に変換する必要がありました。
そこで Serverless Framework から publish コマンドを実行することで、設定ファイルに定義されたリソースセットを元に SAM 形式のテンプレートを作成するプラグインで実装しました。このコマンドは、アプリケーションのバージョン管理やリポジトリへの登録も行うため、CI/CD パイプラインとの連携もサポートしています。
このような仕組みの導入により、SRE チームが運用する AWS アカウントは Terraform 経由で常に最新のアプリケーションをデプロイできる体制となりました。現在は社内でテスト運用段階ですが、将来的にはプラグインやアプリケーションを含め、パッケージの一部は OSS として公開したいと考えています。
そして次に改善が必要となったのが、タスクの自動化によって集められたイベントログの管理です。ログの中には、AWS Config のコンプライアンス違反や、セキュリティパッチの適用結果といったログが含まれます。
イベントデータの一部は Slack に通知していたのですが、前述の監視体制における課題とも相まって、エンジニアがアラートに気付かないケースがより顕著になりました。
イベントデータの可視化
システムの状態を可視化するダッシュボードを開発
システム障害が発生したとき、オンコール担当者は PagerDuty の第一報を元に Datadog モニターを確認します。
クライアントに対するレスポンスで HTTP 5xx が発生しているのであれば、リクエストが ELB のターゲットグループに到達しているのか。アプリケーションに到達しているのであれば、どのマイクロサービスで問題が起きているか、Sentry や APM、アプリケーションログなどを元にリクエストをトレースします。
これら一連のプロセスは、トラブルシュートに長けたエンジニアであればそこまで迷うことはありませんが、プレイブックを作成していても、チームメンバー全員に同じスキルを求めるのは難しい側面があります。これは監視の仕組みがサイロ化された弊害とも言えます。
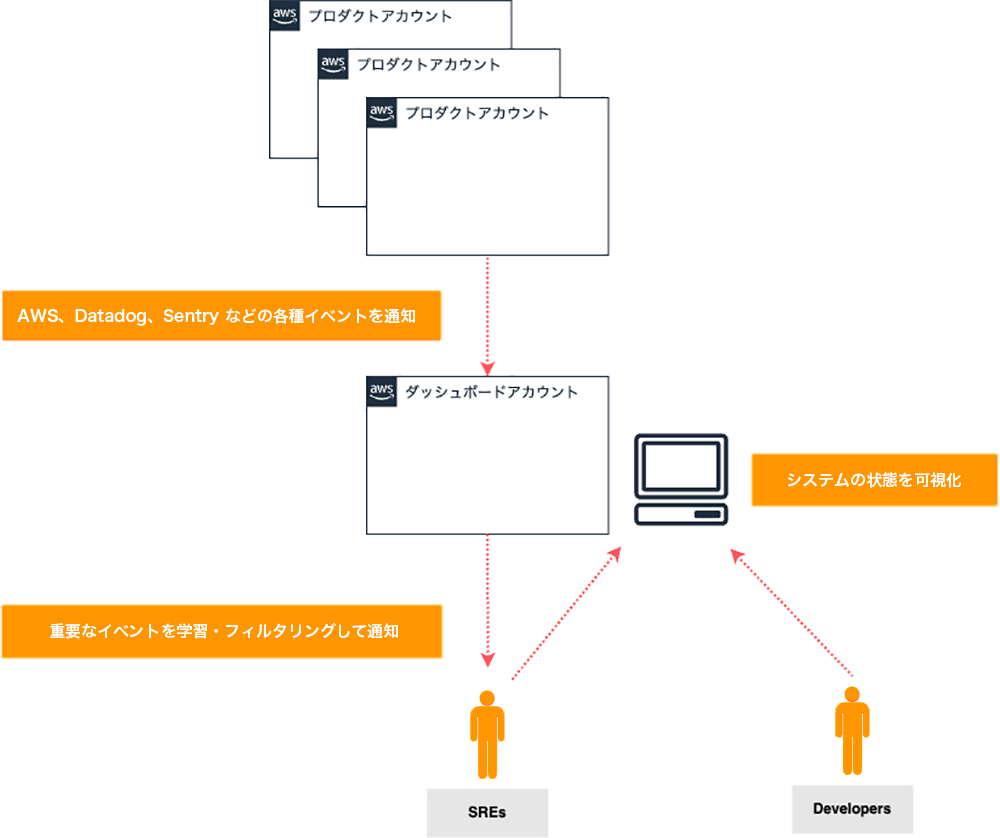
そこで SRE チームでは、各プロダクトで発生したアラートや、トイルの削減によって得られたイベントデータを 1 カ所に集約し、システムの状態を可視化するダッシュボードを開発することにしました。
イベントデータ送信の仕組み
イベントデータは、Amazon EventBridge や Webhook などを介して、データ収集エンドポイント (Amazon API Gateway) に送信される仕組みです。
イベントには次のようなデータタイプが含まれます。
-
PagerDuty : インシデント
-
Datadog : アラート、SLO 実測値
-
Sentry : アプリケーションで発生した例外
-
Amazon GuardDuty : AWS 環境内で検知されたセキュリティリスク
-
Amazon Inspector : EC2 やコンテナに含まれる脆弱性
-
Amazon Security Hub : セキュリティアラート
-
Amazon ECS : クラスタの状態
-
AWS Config : リソースのコンプライアンス状態
-
アプリケーションログ : AWS Fargate (Fluent Bit) から出力されたログ
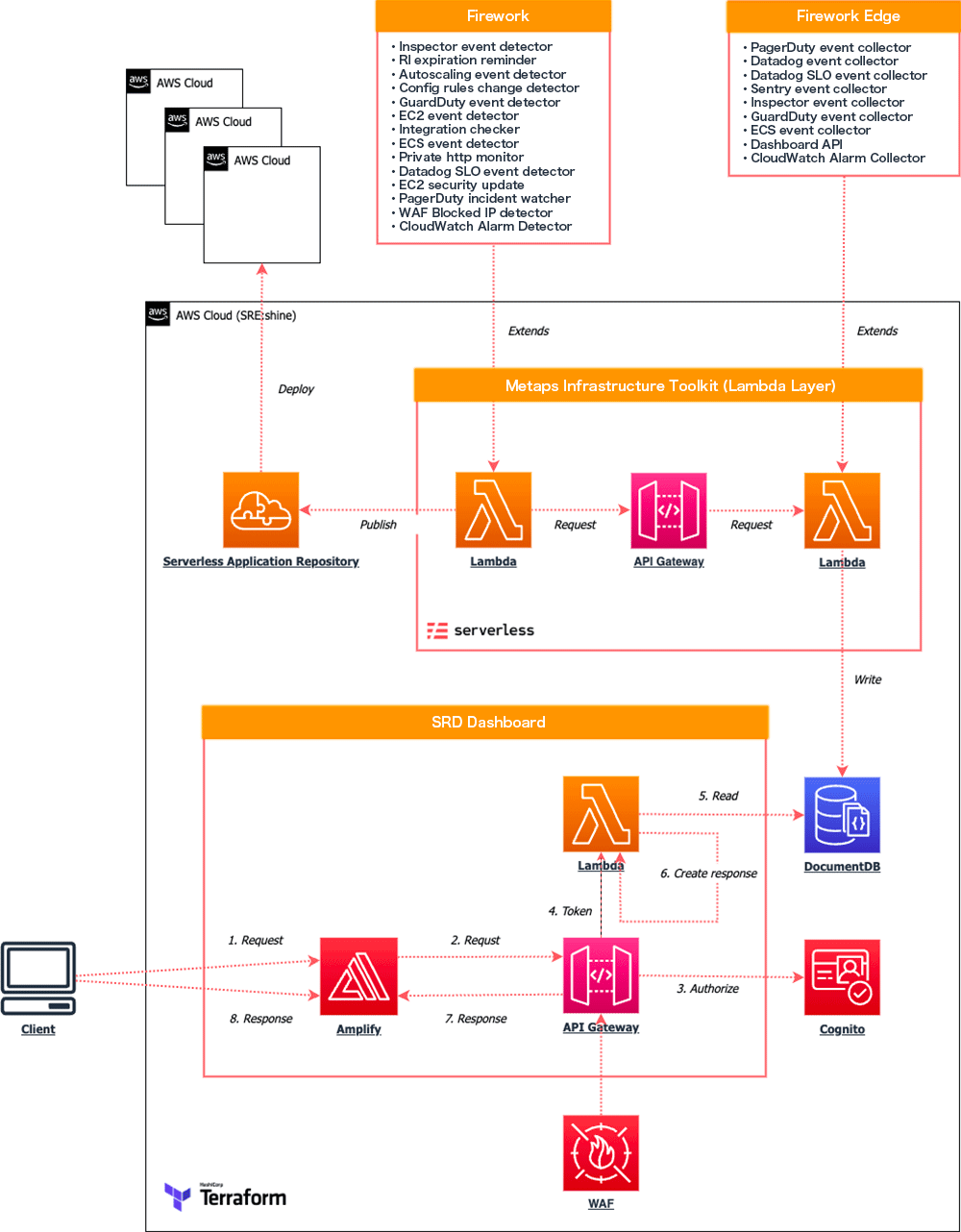
イベントログ送信の検証
イベントログが認可されたクライアントから送信されているかの検証には、API Gateway が提供する API キーを利用しています。
尚、全てのイベント送信元は HTTP ヘッダーに API キーを埋め込む形を想定していたのですが、SaaS によっては Webhook に HTTP ヘッダーを指定できないケースがあり、一部では URL のクエリ文字列を用いたカスタムオーソライザーによる認可を採用しました。クエリ文字列を用いた認可の仕組みについては、「Accepting API keys as a query string in Amazon API Gateway」の記事を参考に実装しています。
収集したイベントログはデータベース (Amazon DocumentDB) に格納され、ダッシュボードでは様々なワークロードを横断する形でシステムの状態を俯瞰できます。これはオブザーバビリティを実現する仕組み作りとも言えます。
ダッシュボードについて
現在、ダッシュボードには OSS の Metabase を利用して可視化していますが、継続的な運用を加味して、自前のダッシュボードを開発中です。
将来的にはポストモーテムの管理や、アプリケーションログの異常検知といった仕組みを組み込むことで、信頼性を計測するダッシュボードとしての機能をより強化させます (ちょうど先日 Amazon DevOps Guru が Log Anomaly Detection をサポートしたので、この辺りも検証を進めていければと考えています)。
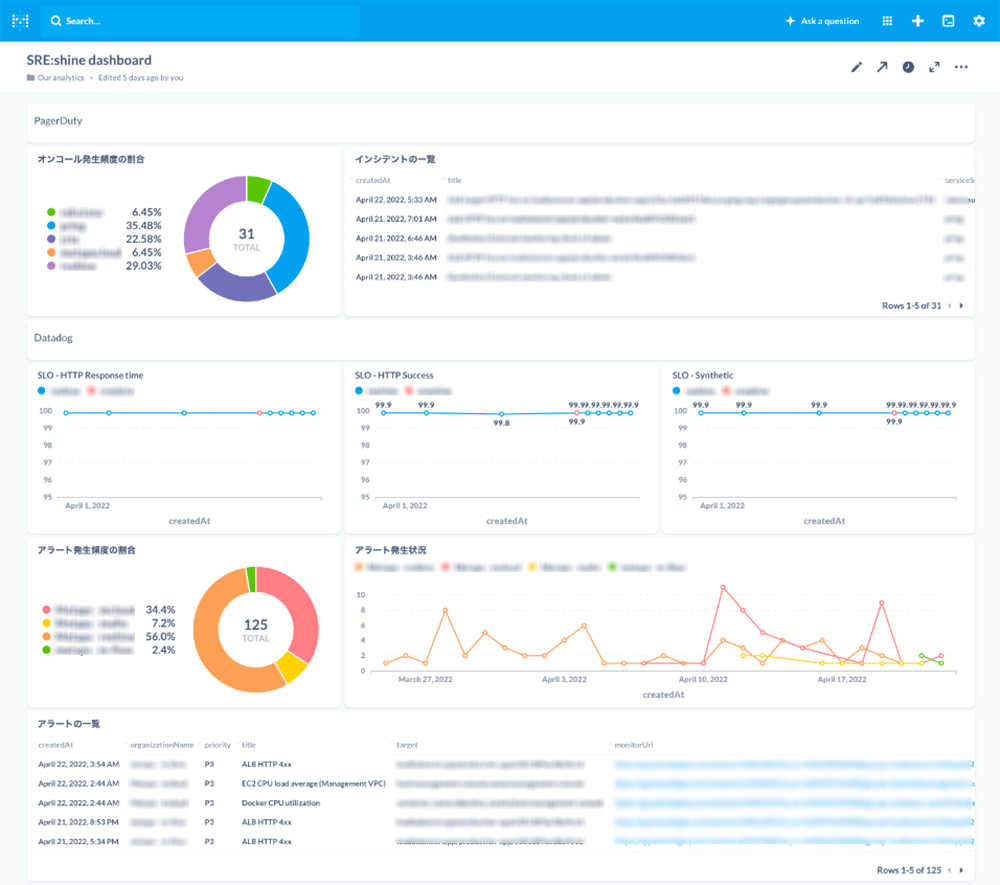
今後について : 横断的な監視の実現
今回は、SRE チームでダッシュボードを内製化するに至った経緯をご紹介させていただきました。このダッシュボードの強みとしては次の 3 点が挙げられます。
- インシデント特化型で、テレメトリデータを可視化できる。
- イベント駆動型のため、特定の SaaS に依存しない。
- 複数のプロダクトを横断して管理できる。
この仕組みの導入により、SRE エンジニアはダッシュボードを確認するだけで、担当プロダクトのシステム状態を確認することができ、監視コストを大幅に下げることに成功しました。
今後、Web アプリケーションの運用において、SRE エンジニアにはモニタリングからオブザーバビリティの実装、更には複数のシステムを監視できる体制基盤作りが求められます。そうした中で、SRE のためのダッシュボードというプラットフォームは重要性が高まると考えられます。
本記事が皆様の運用効率化へ向けたご参考になれば幸いです。
著者プロフィール
山北 尚道
株式会社メタップス
re:shine グループ マネジャー / SRE チーフエンジニア
ベトナム・ハノイでのオフショア事業立ち上げからキャリアをスタートし、アプリケーション開発からマネジメントまでを経験。
2015 年に株式会社メタップスに参画。徐々にクラウドインフラにも携わり、現在は同社で横断的なテックリードや SRE エンジニアとして従事。

Did you find what you were looking for today?
Let us know so we can improve the quality of the content on our pages