- AWS Builder Center
- builders.flash
AWS Lambda におけるバースト耐性
2022-12-02 | Author : 下川 賢介
はじめに
この記事は AWS Lambda と Serverless Advent Calendar 2022 の 12 月 2 日の記事になります。
皆様 こんにちは。 AWS の下川 (@_kensh) です。いかがお過ごしでしょうか ? 毎年 Serverless Advent Calendar を host していまして、多くの方にたくさんの良記事を投稿をいただき、また多くの方に読んでいただけて嬉しく思います。
さて、世間では AWS re:Invent 2022 と World Cup 2022 で盛り上がっていますが、この記事はそれらとほとんど無関係な記事になっています。(一部 re:Invent アップデートも記載)
本稿では、AWS サービスのうち特に AWS Lambdaのバースト耐性について考えてみたいと思います。どのように バースト耐性を実装するか、その手がかりに本稿がなれれば幸いです。
builders.flash メールメンバー登録
token bucket algorithm
概要
token bucket algorithm が本稿のテーマになるのでまずはその意味を wikipedia から拾ってみたいと思います。
概要
トークンバケットは、バケット内のトークンの存在に基づいてトラフィックの転送をいつ行うかを指示する制御機構である。バケットには複数のトークンがあり、それぞれがあるバイト列単位に対応したり、事前に設定した大きさの1つのパケットに対応している。バケット内のトークンはパケットを送信する際に削除される。ネットワーク管理者は何バイトの転送に何個のトークンを対応させるかを設定する。トークンがあるとき、トラフィックを転送できる。バケット内にトークンがないとき、パケットを転送することはできない。従って、個別のフローに十分なトークンが割り当てられていて、バーストしきい値が適切に設定されていれば、そのフローはバースト的に転送可能である。
あるシステムに requests per second (rps) の Quota 設定がされている場合を考えます。例えば 10 rps を Quota 設定されている API エンドポイントがあった場合、200 rps がクライアントから送信されたときに期待としては およそ 190 requests が throttle します。
200 rps 全て処理させたい場合、考えうる対処は 200 rps の Quota に API を設定変更するか、クライアント側で exponential backoff retry させるなどが思い付くでしょうか。
もちろん、これらの対処でも十分である場合も多いですが、クライアントが定常的に 200 rps 送信するのではなく、あるタイミングで一気に送信がスパイクして 200 rps になるが、ほとんどの時間帯では 0 〜 10 rps 程度であるようなシステム特性を持つワークロードも多いと思います。
スパイクに対応するようにシステムにバースト耐性を持たせておくことで、rps の Quota 設定は定常時に合わせて低く設定しておくことができるようになります。
上の例だと、10 rps を API の Quota 設定としておきながらも、200 rps まで バーストさせれるように設定できれば良いと思いませんか ?
そのようなシステム設計に対処するためのアルゴリズムの一つが token bucket algorithm になります。
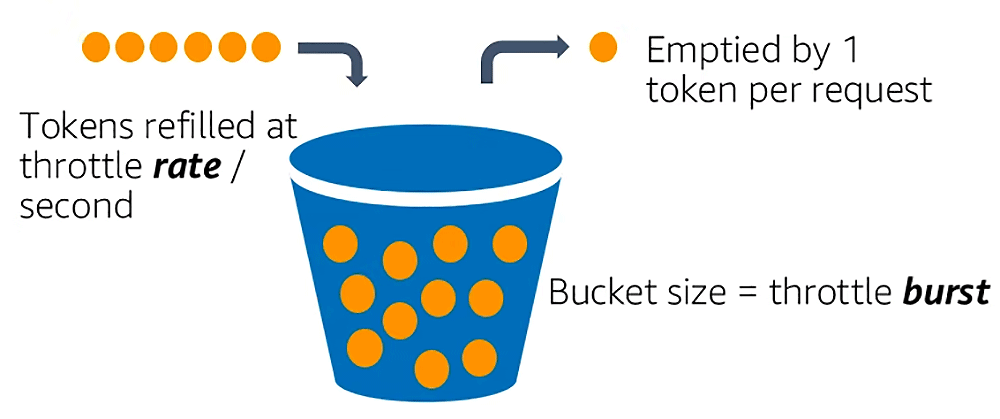
考え方としては、また上記のスパイクするシステムを例にとって話すと、200 token が入る bucket (バケツのこと / S3 bucket とは何の関係もありません) を用意しておきます。API に 1 回のリクエストが来るたびに bucket から 1 token を払い出します (消費します)。リクエストのたびに token は消費していくので、bucket の中身はどんどん減っていきます。bucket の中身が枯渇した時点で throttle となります。
token bucket algorithm が本稿のテーマになるのでまずはその意味を wikipedia から拾ってみたいと思います。
概要
トークンバケットは、バケット内のトークンの存在に基づいてトラフィックの転送をいつ行うかを指示する制御機構である。バケットには複数のトークンがあり、それぞれがあるバイト列単位に対応したり、事前に設定した大きさの1つのパケットに対応している。バケット内のトークンはパケットを送信する際に削除される。ネットワーク管理者は何バイトの転送に何個のトークンを対応させるかを設定する。トークンがあるとき、トラフィックを転送できる。バケット内にトークンがないとき、パケットを転送することはできない。従って、個別のフローに十分なトークンが割り当てられていて、バーストしきい値が適切に設定されていれば、そのフローはバースト的に転送可能である。
あるシステムに requests per second (rps) の Quota 設定がされている場合を考えます。例えば 10 rps を Quota 設定されている API エンドポイントがあった場合、200 rps がクライアントから送信されたときに期待としては およそ 190 requests が throttle します。
200 rps 全て処理させたい場合、考えうる対処は 200 rps の Quota に API を設定変更するか、クライアント側で exponential backoff retry させるなどが思い付くでしょうか。
もちろん、これらの対処でも十分である場合も多いですが、クライアントが定常的に 200 rps 送信するのではなく、あるタイミングで一気に送信がスパイクして 200 rps になるが、ほとんどの時間帯では 0 〜 10 rps 程度であるようなシステム特性を持つワークロードも多いと思います。
スパイクに対応するようにシステムにバースト耐性を持たせておくことで、rps の Quota 設定は定常時に合わせて低く設定しておくことができるようになります。
上の例だと、10 rps を API の Quota 設定としておきながらも、200 rps まで バーストさせれるように設定できれば良いと思いませんか ?
そのようなシステム設計に対処するためのアルゴリズムの一つが token bucket algorithm になります。
考え方としては、また上記のスパイクするシステムを例にとって話すと、200 token が入る bucket (バケツのこと / S3 bucket とは何の関係もありません) を用意しておきます。API に 1 回のリクエストが来るたびに bucket から 1 token を払い出します (消費します)。リクエストのたびに token は消費していくので、bucket の中身はどんどん減っていきます。bucket の中身が枯渇した時点で throttle となります。
refill rate
そこで、bucket を埋め戻す (refill) する機構が必要になります。これが refill rate と呼ばれるものです。上記の例だと 10 rps を設定していたので、これが refill rate に該当します。
bucket は最大 200 token まで 1 秒間に最大 10 token の速さで埋め戻されると理解することができます。
この仕掛けを使うと、200 token 分一気にバーストすることが出来、突如発生するスパイクに対応する耐久性のあるシステムになります。またどこまでもバーストするのではなく、bucket サイズ分だけというコントロールがされています。リクエストが無い (または緩やかな) 時間帯に refill rate によって埋め戻すことで次のスパイクに備えることができます。
つまりバースト耐性を持つ多くのシステムが Quota として設定している rps は単純な "リクエストレートの制限" というよりは refill rate の設定になっていることがあるということです。
先ほどの refill rate 10 rps をさらに 50 rps にすると、burst は 200 まで、refill は 50 rps という設定になります。バーストの特性と rps の特性を柔軟に定義することが出来るようになります。
さらに興味がある方は、こちらのAWS ブログを参照ください。
Building well-architected serverless applications: Regulating inbound request rates »
スループット向上のために採用
Amazon API Gateway では、この token bucket algorithm をスループット向上のために採用していることが AWS 公式ドキュメントに明記されています。
API Gateway は、トークンバケットアルゴリズムを使用してトークンでリクエストをカウントし、API へのリクエストを調整します。特に API Gateway では、アカウントのすべての API に送信されるリクエストのレートとバーストをリージョンごとに検証します。トークンバケットアルゴリズムでは、これらの制限の事前定義されたオーバーランがバーストによって許可されますが、場合によっては、他の要因によって制限がオーバーランされることがあります。
AWS Lambda における バースト耐性
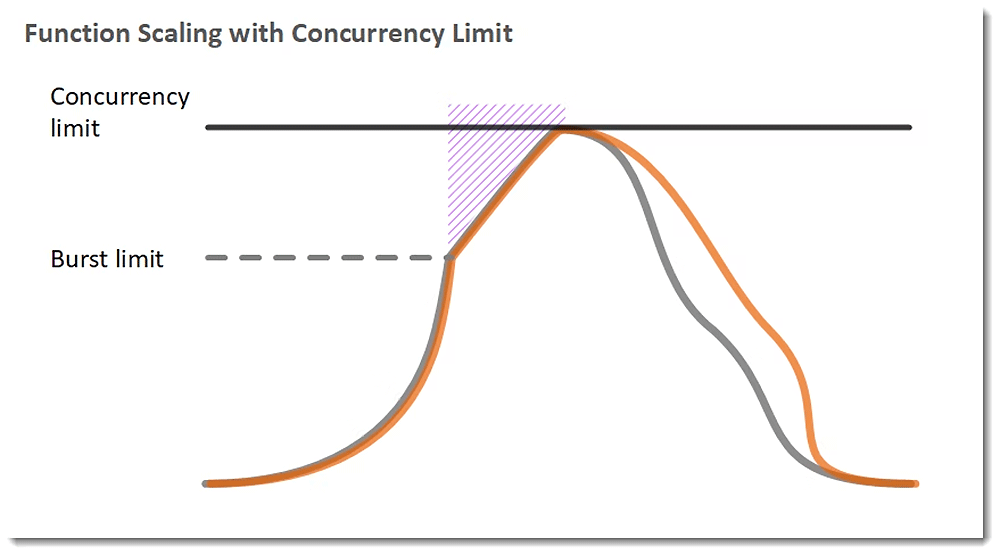
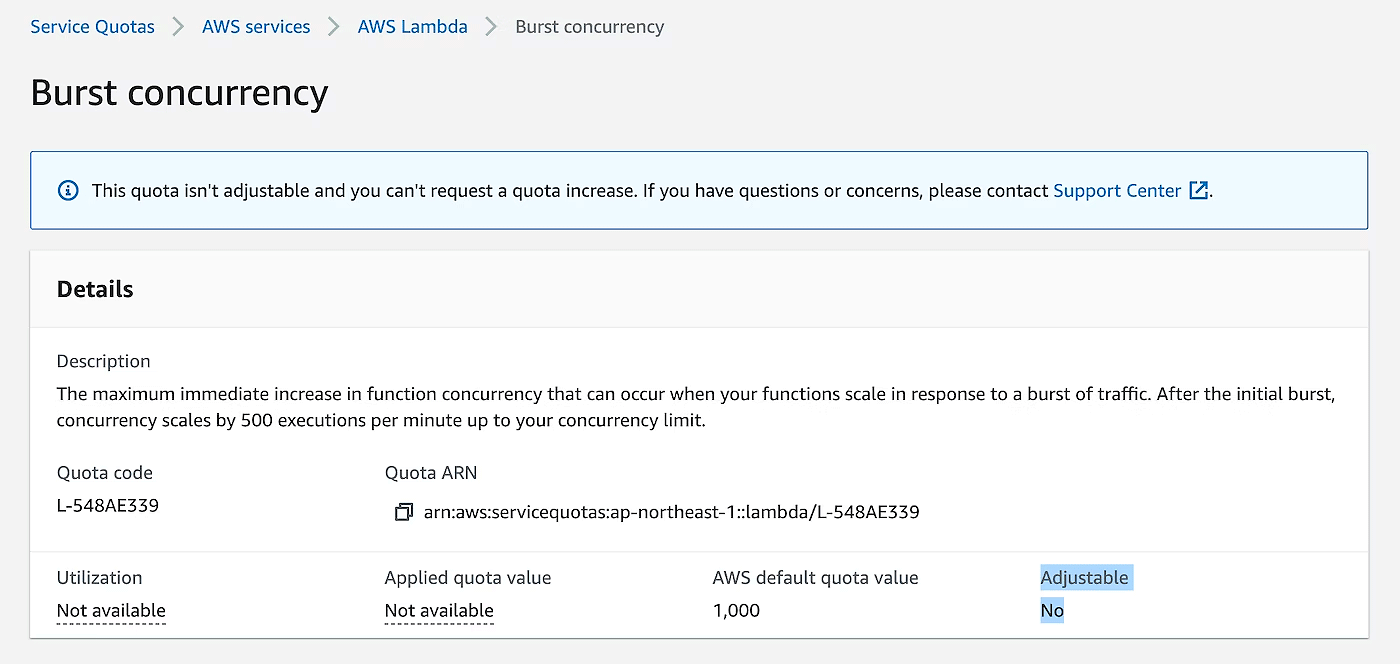
AWS Lambda では 同時実行数にバースト耐性を持たせています。AWS Lambda には同時実行数の Quota とバーストの Quota の 2 種類の値があります。このうち同時実行数の方は制限緩和可能です。東京リージョンですと、同時実行数は 1000 (default, 制限緩和可能) で、バーストは 1000 (制限緩和不可)、バーストに関しては 1 分間に 500 インスタンス増加 (制限緩和不可) になっています。
同時実行数の Quota とバーストの Quota
バーストの同時実行数
Lambda の同時実行数の押し上げを試す
さらに、AWS Lambda のスケーリングメカニズムについて知りたい方はぜひこちらも参照ください。
では、そこで利用されているアルゴリズムは API Gateway や他の多くのシステムと同様に token bucket algorithm なのでしょうか ?
残念ながら、どういうアルゴリズムが採用されているか AWS Lambda の公式ドキュメントには明記されていません。ですが、Lambda のバースト耐性の動きを外形的に観測するとおおよそ token bucket algorithm と類似した挙動を示します。
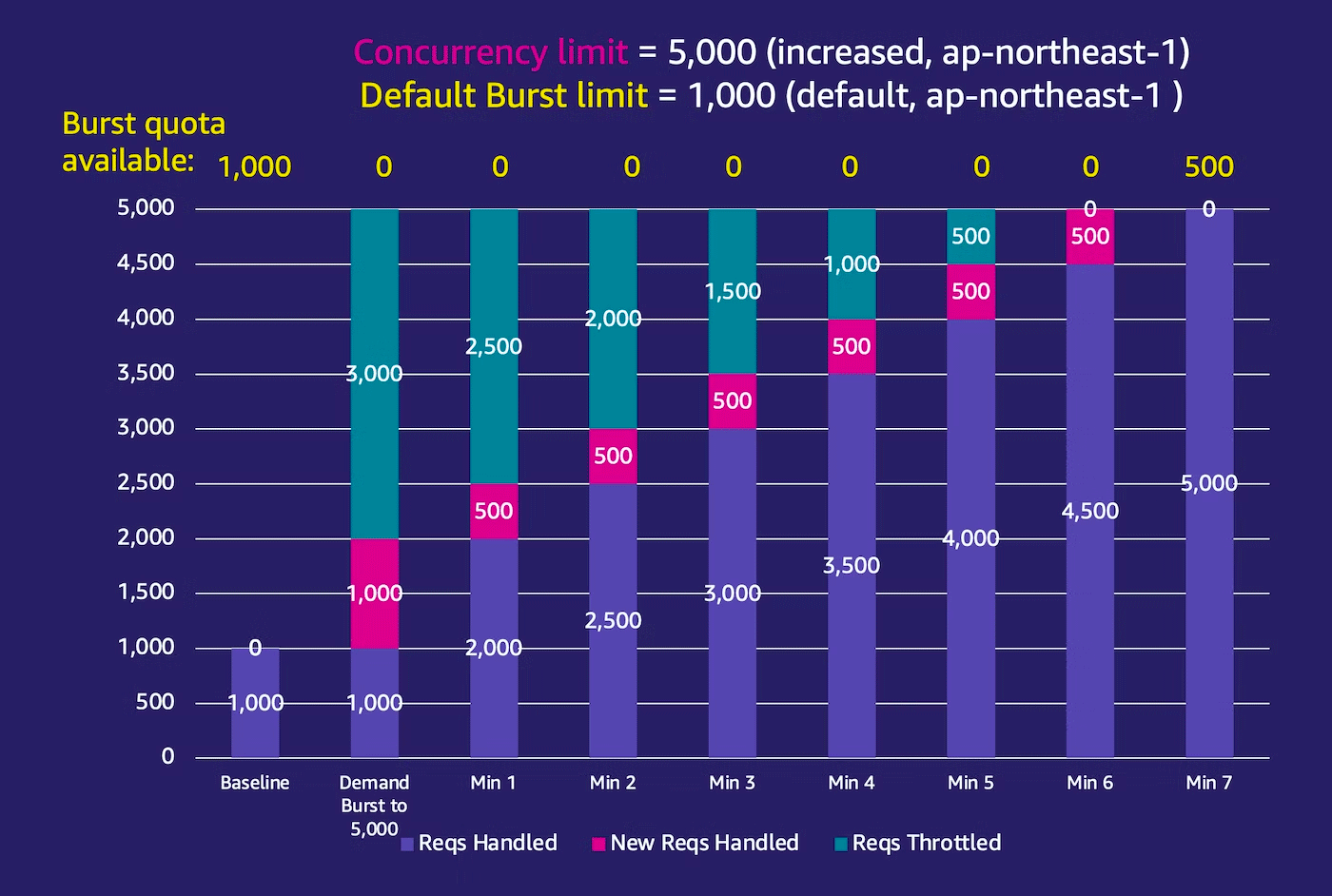
ここで、AWS Lambda の同時実行数を 5000 同時実行まで緩和したとします。他のパラメータについては、バースト Quota はハードリミットの 1000、そして 1 分に 500 のインスタンス増加のままです。
token bucket algorithm の言葉で置き換えると、bucket size が 1000、そして refill rate 500/m の token-bucket と捉えてみることができます。(もう一度言いますが実際の採用アルゴリズムは不明)
Lambda 関数のタイムアウト時間を最大の 900s に設定しておき、handler 実装内で sleep を 900s 入れておきます (Lambda インスタンスが再利用されにくいように)。Lambda の同時実行数が 1000 からスタートさせてみて、クライアントから一気に Lambda の Invoke API を大量に同時コールすることによって、Lambda の同時実行数を 5,000 まで押し上げようと試みてみます。
一気に同時実行数を増やす
Lambda は一気にバースト制限の 1000 同時実行追加まで同時実行数を増やします (合計 2,000 同時実行)。そしてそれ以上のスパイクは受付ることができず Throttleします (同時実行数は 5000 に上限緩和しているのでバーストの制限に抵触している)、このバースト bucket は 1 分間に 500 回復するので、クライアントからのリクエストをキープしたまま観測してみます。
そしてそれ以降も 5000 同時実行数を達成すべくリクエストを継続すると、1 分間に 500 同時実行数ずつ増加しているのが表から見てとれます。
バースト耐性をさらに向上させるには?
ここまで見てきた通り、AWS Lambda の同時実行数の上限緩和をしても、Lambda のバースト性の制約から一気に同時実行数上限までバーストするわけでは無いと言うことがわかりました。
同時実行数のバースト性を高めるには Provisioned Concurrency を利用する方法があります。 Provisioned Concurrency を使うと 5000 同時実行でも 10000 同時実行でも暖めたインスタンスの数だけバーストします。(詳しくは、Lambda の Provisioned Concurrency と 1 年付き合ってみて思ったこと。を参照ください)
ただ、よく考えると何も同時実行数のバースト性に頼らずに、リクエストハンドリングのバースト性を向上させれば良いと言うことに気がつきます。Lambda 関数の 1 インスタンスは同時にリクエストを受けれる数は 1 ですが、処理が終われば次のリクエストを受け付けることができます。先ほどの例ではあえて、900s の sleep を入れて実験したため、1 インスタンスが再利用され無いように組んでいました。
例えば、100ms の Lambda Handler 実行時間の関数だとすると 1 インスタンスで 1 秒間におよそ 10 tps 処理することができます。ですので、先ほどの例の 5000トランザクションであれば 500 同時実行程度で捌けることになります。(詳しくは、「AWS Lambdaの実行モデルについて考えてみる」を参照ください)
よって、
同時実行数のバースト性 << リクエストハンドリングのバースト性
を意識して、同時実行数によるスケールを考えるより、Lambda handler の処理時間チューニングを考えていく方がよりスケーラブルなシステムになります。
AWS Lambda のパフォーマンスチューニング資料
AWS Lambda のパフォーマンスチューニングに関しては、こちらの資料をご参考ください

Lambda Snap Start
また、Cold Start の抑制をすることで、Lambda の処理時間を短くすることができ、単一トランザクションでの Lambda 関数インスタンスの占有時間が短くなります。
AWS re:Invent 2022 で登場した、AWS Lambda の Snap Start を使うことで Cold Start の抑制が可能になっています。

まとめ
AWS Lambda のバースト耐性の話をしてきましたが、token bucket algorithm 自体の考え方は汎用的です。もし興味がある方はご自身で実装されるのも面白いかもしれません。もし実装された方はどのように実装したかブログなどで公開いただけると嬉しいです。
AWS Lambda の同時実行数のバースト性についてもご理解いただけたかと思いますが、本文で述べたとおり、リクエストハンドリングを効率的にして、同時実行数の増加に頼らないレイテンシーの低い実行時間こそがスケーリングにとって肝心だとご理解いただければ幸いです。
筆者プロフィール
下川 賢介 (@_kensh)
アマゾン ウェブ サービス ジャパン合同会社
シニア サーバーレススペシャリスト ソリューションアーキテクト
Serverless Specialist Solutions Architect として AWS Japan に勤務。
Serverless の大好きな特徴は、ビジネスロジックに集中できるところ。
ビジネスオーナーにとってインフラの管理やサービスの冗長化などは、ビジネスのタイプに関わらず必ず必要になってくる事柄です。
でもどのサービス、どのビジネスにでも必要ということは、逆にビジネスの色はそこには乗って来ないということ。
フルマネージドなサービスを使って関数までそぎ落とされたロジックレベルの管理だけでオリジナルのサービスを構築できるという Serverless の特徴は技術者だけでなく、ビジネスに多大な影響を与えています。
このような Serverless の嬉しい特徴をデベロッパーやビジネスオーナーと一緒に体験し、面白いビジネスの実現を支えるために日々活動しています。
