Amazon Web Services 한국 블로그
Amazon Nova Multimodal Embeddings: 에이전틱 RAG와 시맨틱 검색을 위한 첨단 임베딩 모델
오늘은 Amazon Bedrock에서 사용할 수 있는 에이전틱 검색 증강 생성(RAG) 및 시맨틱 검색 애플리케이션용 첨단 멀티모달 임베딩 모델인 Amazon Nova Multimodal Embeddings를 소개합니다. 단일 모델을 통해 텍스트, 문서, 이미지, 비디오, 오디오를 지원하여 높은 정확도로 크로스모달 검색이 가능한 최초의 통합 임베딩 모델입니다.
임베딩 모델은 텍스트, 시각, 오디오 입력을 임베딩이라는 수치 표현으로 변환합니다. 이러한 임베딩은 AI 시스템이 비교, 검색하고 분석할 수 있는 방식으로 입력 값의 의미를 캡처하여 시맨틱 검색과 RAG 등의 사용 사례를 지원합니다.
갈수록 많은 조직들이 텍스트, 이미지, 문서, 비디오, 오디오 콘텐츠 전반에 흩어져 있는 방대한 양의 비정형 데이터로부터 통찰을 이끌어낼 솔루션을 찾고 있습니다. 예를 들어 어떤 조직에 제품 이미지, 인포그래픽과 텍스트가 포함된 브로셔, 사용자가 업로드한 비디오 클립이 있을 수 있습니다. 임베딩 모델은 비정형 데이터로부터 가치를 창출할 수 있지만, 기존 모델은 일반적으로 한 가지 콘텐츠 유형을 처리하는 데 특화되어 있습니다. 이러한 한계로 인해 고객은 복잡한 크로스모달 임베딩 솔루션을 구축하거나 단일 콘텐츠 유형에 초점을 맞춘 사용 사례로 제한하게 됩니다. 이 문제는 텍스트와 이미지가 인터리빙된 문서나 시각, 오디오, 텍스트 요소가 포함된 비디오처럼 기존 모델이 크로스모달 관계를 효과적으로 캡처하기 어려운 혼합 양식 콘텐츠 유형에도 적용됩니다.
Nova Multimodal Emdings는 혼합 양식 콘텐츠 전반에 걸친 크로스모달 검색, 참조 이미지를 이용한 검색, 시각적 문서 검색 등의 사용 사례를 고려하여 텍스트, 문서, 이미지, 비디오, 오디오를 위한 통합된 시맨틱 공간을 지원합니다.
Amazon Nova Multimodal Embeddings 성능 평가
광범위한 벤치마크를 기준으로 모델을 평가한 결과, 다음 표에 설명된 바와 같이 바로 높은 정확도로 사용할 수 있습니다.
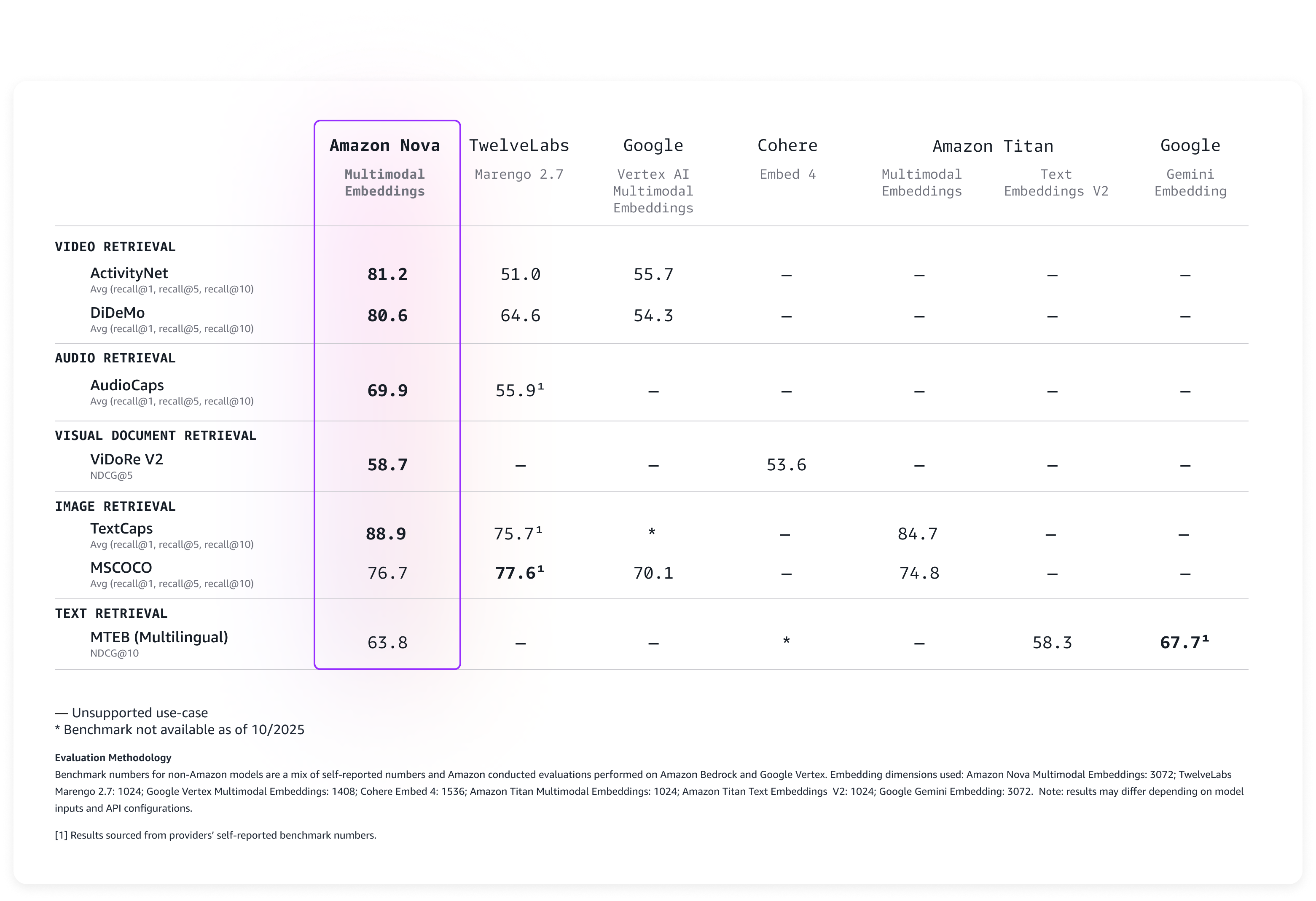
Nova Multimodal Embeddings는 최대 8K 토큰의 컨텍스트 길이, 최대 200개 언어의 텍스트를 지원하며 동기식, 비동기식 API를 통해 입력을 허용합니다. 또한 긴 형식의 텍스트, 비디오 또는 오디오 콘텐츠를 관리 가능한 세그먼트로 분할하여 각 부분에 대한 임베딩을 생성하는 분할(‘청킹’이라고도 함)을 지원합니다. 마지막으로 이 모델은 Matryoshka 표현 학습(MRL)을 사용하여 훈련된 4개의 출력 임베딩 차원을 제공하므로 정확도 변경을 최소화하면서 지연 시간이 짧은 엔드 투 엔드 검색을 제공합니다.
새 모델을 실제로 어떻게 사용할 수 있는지 살펴보겠습니다.
Amazon Nova Multimodal Embeddings 사용
Nova Multimodal Embeddings를 시작할 때는 Amazon Bedrock의 다른 모델과 동일한 패턴을 따릅니다. 이 모델은 텍스트, 문서, 이미지, 비디오 또는 오디오를 입력으로 허용하고 시맨틱 검색, 유사성 비교 또는 RAG에 사용할 수 있는 숫자 임베딩을 반환합니다.
다음은 다양한 콘텐츠 유형으로부터 임베딩을 생성하고 나중에 검색할 수 있도록 저장하는 방법을 보여주는 실제 AWS SDK for Python(Boto3) 사용 예시입니다. 간단히 대규모 벡터 저장과 쿼리를 기본적으로 지원하는 비용 최적화된 스토리지인 Amazon S3 Vectors를 사용하여 임베딩을 저장하고 검색하겠습니다.
텍스트를 임베딩으로 변환하는 기본 단계부터 시작하겠습니다. 이 예시는 단순한 텍스트 설명을 시맨틱 의미를 포착하는 숫자 표현으로 변환하는 방법을 보여줍니다. 이러한 임베딩은 나중에 문서, 이미지, 비디오 또는 오디오의 임베딩과 비교하여 관련 콘텐츠를 찾을 수 있습니다.
코드를 쉽게 따라할 수 있도록 스크립트의 한 부분씩 보여드리겠습니다. 전체 스크립트는 이 연습의 뒷부분에 포함되어 있습니다.
import json
import base64
import time
import boto3
MODEL_ID = "amazon.nova-2-multimodal-embeddings-v1:0"
EMBEDDING_DIMENSION = 3072
# Amazon Bedrock 런타임 클라이언트 초기화
bedrock_runtime = boto3.client("bedrock-runtime", region_name="us-east-1")
print(f"Generating text embedding with {MODEL_ID} ...")
# 임베드할 텍스트
text = "Amazon Nova is a multimodal foundation model"
# 임베딩 생성
request_body = {
"taskType": "SINGLE_EMBEDDING",
"singleEmbeddingParams": {
"embeddingPurpose": "GENERIC_INDEX",
"embeddingDimension": EMBEDDING_DIMENSION,
"text": {"truncationMode": "END", "value": text},
},
}
response = bedrock_runtime.invoke_model(
body=json.dumps(request_body),
modelId=MODEL_ID,
contentType="application/json",
)
# 임베딩 추출
response_body = json.loads(response["body"].read())
embedding = response_body["embeddings"][0]["embedding"]
print(f"Generated embedding with {len(embedding)} dimensions")이제 스크립트와 같은 폴더에 있는 photo.jpg 파일을 사용하여 동일한 임베딩 공간을 사용하는 시각적 콘텐츠를 처리하겠습니다. 이와 같이 멀티모달리티의 힘을 알 수 있습니다. Nova Multimodal Embeddings는 텍스트와 시각적 컨텍스트를 모두 단일 임베딩으로 캡처하여 문서에 대한 이해를 높입니다.
Nova Multimodal Embeddings는 사용 방식에 최적화된 임베딩을 생성할 수 있습니다. 검색 또는 검색 사용 사례를 위해 인덱싱할 때 embeddingPurpose를 GENERIC_INDEX로 설정하면 됩니다. 쿼리 단계의 경우, 검색할 항목의 유형에 따라 embeddingPurpose를 설정하면 됩니다. 예를 들어, 문서를 검색할 때는 embeddingPurpose를 DOCUMENT_RETRIEVAL로 설정하면 됩니다.
# 이미지 읽기 및 인코딩
print(f"Generating image embedding with {MODEL_ID} ...")
with open("photo.jpg", "rb") as f:
image_bytes = base64.b64encode(f.read()).decode("utf-8")
# 임베딩 생성
request_body = {
"taskType": "SINGLE_EMBEDDING",
"singleEmbeddingParams": {
"embeddingPurpose": "GENERIC_INDEX",
"embeddingDimension": EMBEDDING_DIMENSION,
"image": {
"format": "jpeg",
"source": {"bytes": image_bytes}
},
},
}
response = bedrock_runtime.invoke_model(
body=json.dumps(request_body),
modelId=MODEL_ID,
contentType="application/json",
)
# 임베딩 추출
response_body = json.loads(response["body"].read())
embedding = response_body["embeddings"][0]["embedding"]
print(f"Generated embedding with {len(embedding)} dimensions")비디오 콘텐츠를 처리하기 위해 저는 비동기식 API를 사용합니다. Base64로 인코딩된 경우 25MB보다 큰 비디오에 대한 요구 사항입니다. 먼저 동일한 AWS 리전의 S3 버킷에 로컬 비디오를 업로드합니다.
aws s3 cp presentation.mp4 s3://my-video-bucket/videos/이 예제에서는 비디오 파일의 시각적 구성 요소와 오디오 구성 요소 모두에서 임베딩을 추출하는 방법을 보여줍니다. 분할 특성은 긴 비디오를 관리 가능한 청크로 나누기 때문에 몇 시간 분량의 콘텐츠를 효율적으로 검색할 수 있습니다.
# Amazon S3 클라이언트 초기화
s3 = boto3.client("s3", region_name="us-east-1")
print(f"Generating video embedding with {MODEL_ID} ...")
# Amazon S3 URI
S3_VIDEO_URI = "s3://my-video-bucket/videos/presentation.mp4"
S3_EMBEDDING_DESTINATION_URI = "s3://my-embedding-destination-bucket/embeddings-output/"
# 오디오가 있는 비디오에 대한 비동기 임베딩 작업 생성
model_input = {
"taskType": "SEGMENTED_EMBEDDING",
"segmentedEmbeddingParams": {
"embeddingPurpose": "GENERIC_INDEX",
"embeddingDimension": EMBEDDING_DIMENSION,
"video": {
"format": "mp4",
"embeddingMode": "AUDIO_VIDEO_COMBINED",
"source": {
"s3Location": {"uri": S3_VIDEO_URI}
},
"segmentationConfig": {
"durationSeconds": 15 # 15초 단위로 분할
},
},
},
}
response = bedrock_runtime.start_async_invoke(
modelId=MODEL_ID,
modelInput=model_input,
outputDataConfig={
"s3OutputDataConfig": {
"s3Uri": S3_EMBEDDING_DESTINATION_URI
}
},
)
invocation_arn = response["invocationArn"]
print(f"Async job started: {invocation_arn}")
# 작업 완료까지 풀링
print("\nPolling for job completion...")
while True:
job = bedrock_runtime.get_async_invoke(invocationArn=invocation_arn)
status = job["status"]
print(f"Status: {status}")
if status != "InProgress":
break
time.sleep(15)
# 작업이 성공적으로 완료되었는지 확인
if status == "Completed":
output_s3_uri = job["outputDataConfig"]["s3OutputDataConfig"]["s3Uri"]
print(f"\nSuccess! Embeddings at: {output_s3_uri}")
# S3 URI를 구문 분석하여 버킷과 접두사 추출
s3_uri_parts = output_s3_uri[5:].split("/", 1) # "s3://" 접두사 삭제
bucket = s3_uri_parts[0]
prefix = s3_uri_parts[1] if len(s3_uri_parts) > 1 else ""
# embedding-audio-video.jsonl로 AUDIO_VIDEO_COMBINED 모드 출력
# output_s3_uri에는 이미 작업 ID가 포함되어 있으므로, 파일명만 추가
embeddings_key = f"{prefix}/embedding-audio-video.jsonl".lstrip("/")
print(f"Reading embeddings from: s3://{bucket}/{embeddings_key}")
# JSONL 파일 읽기 및 구문 분석
response = s3.get_object(Bucket=bucket, Key=embeddings_key)
content = response['Body'].read().decode('utf-8')
embeddings = []
for line in content.strip().split('\n'):
if line:
embeddings.append(json.loads(line))
print(f"\nFound {len(embeddings)} video segments:")
for i, segment in enumerate(embeddings):
print(f" Segment {i}: {segment.get('startTime', 0):.1f}s - {segment.get('endTime', 0):.1f}s")
print(f" Embedding dimension: {len(segment.get('embedding', []))}")
else:
print(f"\nJob failed: {job.get('failureMessage', 'Unknown error')}")임베딩이 생성되면 효율적으로 저장하고 검색할 곳이 필요합니다. 이 예제는 대규모 유사성 검색에 필요한 인프라를 제공하는 Amazon S3 Vectors를 사용하여 벡터 저장소를 설정하는 방법을 보여줍니다. 의미상 유사한 콘텐츠가 자연스럽게 클러스터를 구축하여 검색 가능한 인덱스를 만든다고 생각하면 됩니다. 인덱스에 임베딩을 추가할 때 저는 메타데이터를 사용하여 원래 형식과 인덱싱되는 콘텐츠를 지정합니다.
# Amazon S3 Vectors 클라이언트 초기화
s3vectors = boto3.client("s3vectors", region_name="us-east-1")
# 구성
VECTOR_BUCKET = "my-vector-store"
INDEX_NAME = "embeddings"
# 벡터 버킷 및 인덱스 생성 (존재하지 않을 경우)
try:
s3vectors.get_vector_bucket(vectorBucketName=VECTOR_BUCKET)
print(f"Vector bucket {VECTOR_BUCKET} already exists")
except s3vectors.exceptions.NotFoundException:
s3vectors.create_vector_bucket(vectorBucketName=VECTOR_BUCKET)
print(f"Created vector bucket: {VECTOR_BUCKET}")
try:
s3vectors.get_index(vectorBucketName=VECTOR_BUCKET, indexName=INDEX_NAME)
print(f"Vector index {INDEX_NAME} already exists")
except s3vectors.exceptions.NotFoundException:
s3vectors.create_index(
vectorBucketName=VECTOR_BUCKET,
indexName=INDEX_NAME,
dimension=EMBEDDING_DIMENSION,
dataType="float32",
distanceMetric="cosine"
)
print(f"Created index: {INDEX_NAME}")
texts = [
"Machine learning on AWS",
"Amazon Bedrock provides foundation models",
"S3 Vectors enables semantic search"
]
print(f"\nGenerating embeddings for {len(texts)} texts...")
# 각 텍스트에 Amazon Nova를 사용하여 임베딩 생성
vectors = []
for text in texts:
response = bedrock_runtime.invoke_model(
body=json.dumps({
"taskType": "SINGLE_EMBEDDING",
"singleEmbeddingParams": {
"embeddingDimension": EMBEDDING_DIMENSION,
"text": {"truncationMode": "END", "value": text}
}
}),
modelId=MODEL_ID,
accept="application/json",
contentType="application/json"
)
response_body = json.loads(response["body"].read())
embedding = response_body["embeddings"][0]["embedding"]
vectors.append({
"key": f"text:{text[:50]}", # 고유 식별자
"data": {"float32": embedding},
"metadata": {"type": "text", "content": text}
})
print(f" ✓ Generated embedding for: {text}")
# 한 번의 호출로 저장할 모든 벡터 추가
s3vectors.put_vectors(
vectorBucketName=VECTOR_BUCKET,
indexName=INDEX_NAME,
vectors=vectors
)
print(f"\nSuccessfully added {len(vectors)} vectors to the store in one put_vectors call!")마지막 예제에서는 단일 쿼리로 다양한 콘텐츠 유형을 검색하여 텍스트, 이미지, 비디오, 오디오 등 출처에 관계없이 가장 유사한 콘텐츠를 찾는 기능을 보여줍니다. 거리 점수는 결과가 원래 검색어와 얼마나 밀접하게 관련되어 있는지 이해하는 데 도움이 됩니다.
# 쿼리할 텍스트
query_text = "foundation models"
print(f"\nGenerating embeddings for query '{query_text}' ...")
# 임베딩 생성
response = bedrock_runtime.invoke_model(
body=json.dumps({
"taskType": "SINGLE_EMBEDDING",
"singleEmbeddingParams": {
"embeddingPurpose": "GENERIC_RETRIEVAL",
"embeddingDimension": EMBEDDING_DIMENSION,
"text": {"truncationMode": "END", "value": query_text}
}
}),
modelId=MODEL_ID,
accept="application/json",
contentType="application/json"
)
response_body = json.loads(response["body"].read())
query_embedding = response_body["embeddings"][0]["embedding"]
print(f"Searching for similar embeddings...\n")
# 가장 유사한 벡터 상위 5개 검색
response = s3vectors.query_vectors(
vectorBucketName=VECTOR_BUCKET,
indexName=INDEX_NAME,
queryVector={"float32": query_embedding},
topK=5,
returnDistance=True,
returnMetadata=True
)
# 결과 표시
print(f"Found {len(response['vectors'])} results:\n")
for i, result in enumerate(response["vectors"], 1):
print(f"{i}. {result['key']}")
print(f" Distance: {result['distance']:.4f}")
if result.get("metadata"):
print(f" Metadata: {result['metadata']}")
print()크로스모달 검색은 멀티모달 임베딩의 주요 이점 중 하나입니다. 크로스모달 검색을 사용하면 텍스트로 쿼리하고 관련 이미지를 찾을 수 있습니다. 텍스트 설명을 사용하여 비디오를 검색하거나 특정 주제와 일치하는 오디오 클립을 찾거나 시각 콘텐츠 및 텍스트 콘텐츠를 기반으로 문서를 검색할 수도 있습니다. 참고로 이전 예제를 모두 병합한 전체 스크립트는 다음과 같습니다.
import json
import base64
import time
import boto3
MODEL_ID = "amazon.nova-2-multimodal-embeddings-v1:0"
EMBEDDING_DIMENSION = 3072
# Amazon Bedrock 런타임 클라이언트 초기화
bedrock_runtime = boto3.client("bedrock-runtime", region_name="us-east-1")
print(f"Generating text embedding with {MODEL_ID} ...")
# 임베드할 텍스트
text = "Amazon Nova is a multimodal foundation model"
# 임베딩 생성
request_body = {
"taskType": "SINGLE_EMBEDDING",
"singleEmbeddingParams": {
"embeddingPurpose": "GENERIC_INDEX",
"embeddingDimension": EMBEDDING_DIMENSION,
"text": {"truncationMode": "END", "value": text},
},
}
response = bedrock_runtime.invoke_model(
body=json.dumps(request_body),
modelId=MODEL_ID,
contentType="application/json",
)
# 임베딩 추출
response_body = json.loads(response["body"].read())
embedding = response_body["embeddings"][0]["embedding"]
print(f"Generated embedding with {len(embedding)} dimensions")
# 이미지 읽기 및 인코딩
print(f"Generating image embedding with {MODEL_ID} ...")
with open("photo.jpg", "rb") as f:
image_bytes = base64.b64encode(f.read()).decode("utf-8")
# 임베딩 생성
request_body = {
"taskType": "SINGLE_EMBEDDING",
"singleEmbeddingParams": {
"embeddingPurpose": "GENERIC_INDEX",
"embeddingDimension": EMBEDDING_DIMENSION,
"image": {
"format": "jpeg",
"source": {"bytes": image_bytes}
},
},
}
response = bedrock_runtime.invoke_model(
body=json.dumps(request_body),
modelId=MODEL_ID,
contentType="application/json",
)
# 임베딩 추출
response_body = json.loads(response["body"].read())
embedding = response_body["embeddings"][0]["embedding"]
print(f"Generated embedding with {len(embedding)} dimensions")
# Amazon S3 클라이언트 초기화
s3 = boto3.client("s3", region_name="us-east-1")
print(f"Generating video embedding with {MODEL_ID} ...")
# Amazon S3 URI
S3_VIDEO_URI = "s3://my-video-bucket/videos/presentation.mp4"
# Amazon S3 출력 버킷 및 위치
S3_EMBEDDING_DESTINATION_URI = "s3://my-video-bucket/embeddings-output/"
# 오디오가 있는 비디오에 대한 비동기 임베딩 작업 생성
model_input = {
"taskType": "SEGMENTED_EMBEDDING",
"segmentedEmbeddingParams": {
"embeddingPurpose": "GENERIC_INDEX",
"embeddingDimension": EMBEDDING_DIMENSION,
"video": {
"format": "mp4",
"embeddingMode": "AUDIO_VIDEO_COMBINED",
"source": {
"s3Location": {"uri": S3_VIDEO_URI}
},
"segmentationConfig": {
"durationSeconds": 15 # 15초 단위로 분할
},
},
},
}
response = bedrock_runtime.start_async_invoke(
modelId=MODEL_ID,
modelInput=model_input,
outputDataConfig={
"s3OutputDataConfig": {
"s3Uri": S3_EMBEDDING_DESTINATION_URI
}
},
)
invocation_arn = response["invocationArn"]
print(f"Async job started: {invocation_arn}")
# 작업 완료까지 풀링
print("\nPolling for job completion...")
while True:
job = bedrock_runtime.get_async_invoke(invocationArn=invocation_arn)
status = job["status"]
print(f"Status: {status}")
if status != "InProgress":
break
time.sleep(15)
# 작업이 성공적으로 완료되었는지 확인
if status == "Completed":
output_s3_uri = job["outputDataConfig"]["s3OutputDataConfig"]["s3Uri"]
print(f"\nSuccess! Embeddings at: {output_s3_uri}")
# S3 URI를 구문 분석하여 버킷과 접두사 추출
s3_uri_parts = output_s3_uri[5:].split("/", 1) # "s3://" 접두사 삭제
bucket = s3_uri_parts[0]
prefix = s3_uri_parts[1] if len(s3_uri_parts) > 1 else ""
# embedding-audio-video.jsonl로 AUDIO_VIDEO_COMBINED 모드 출력
# output_s3_uri에는 이미 작업 ID가 포함되어 있으므로, 파일명만 추가
embeddings_key = f"{prefix}/embedding-audio-video.jsonl".lstrip("/")
print(f"Reading embeddings from: s3://{bucket}/{embeddings_key}")
# JSONL 파일 읽기 및 구문 분석
response = s3.get_object(Bucket=bucket, Key=embeddings_key)
content = response['Body'].read().decode('utf-8')
embeddings = []
for line in content.strip().split('\n'):
if line:
embeddings.append(json.loads(line))
print(f"\nFound {len(embeddings)} video segments:")
for i, segment in enumerate(embeddings):
print(f" Segment {i}: {segment.get('startTime', 0):.1f}s - {segment.get('endTime', 0):.1f}s")
print(f" Embedding dimension: {len(segment.get('embedding', []))}")
else:
print(f"\nJob failed: {job.get('failureMessage', 'Unknown error')}")
# Amazon S3 Vectors 클라이언트 초기화
s3vectors = boto3.client("s3vectors", region_name="us-east-1")
# 구성
VECTOR_BUCKET = "my-vector-store"
INDEX_NAME = "embeddings"
# 벡터 버킷 및 인덱스 생성 (존재하지 않을 경우)
try:
s3vectors.get_vector_bucket(vectorBucketName=VECTOR_BUCKET)
print(f"Vector bucket {VECTOR_BUCKET} already exists")
except s3vectors.exceptions.NotFoundException:
s3vectors.create_vector_bucket(vectorBucketName=VECTOR_BUCKET)
print(f"Created vector bucket: {VECTOR_BUCKET}")
try:
s3vectors.get_index(vectorBucketName=VECTOR_BUCKET, indexName=INDEX_NAME)
print(f"Vector index {INDEX_NAME} already exists")
except s3vectors.exceptions.NotFoundException:
s3vectors.create_index(
vectorBucketName=VECTOR_BUCKET,
indexName=INDEX_NAME,
dimension=EMBEDDING_DIMENSION,
dataType="float32",
distanceMetric="cosine"
)
print(f"Created index: {INDEX_NAME}")
texts = [
"Machine learning on AWS",
"Amazon Bedrock provides foundation models",
"S3 Vectors enables semantic search"
]
print(f"\nGenerating embeddings for {len(texts)} texts...")
# 각 텍스트에 Amazon Nova를 사용하여 임베딩 생성
vectors = []
for text in texts:
response = bedrock_runtime.invoke_model(
body=json.dumps({
"taskType": "SINGLE_EMBEDDING",
"singleEmbeddingParams": {
"embeddingPurpose": "GENERIC_INDEX",
"embeddingDimension": EMBEDDING_DIMENSION,
"text": {"truncationMode": "END", "value": text}
}
}),
modelId=MODEL_ID,
accept="application/json",
contentType="application/json"
)
response_body = json.loads(response["body"].read())
embedding = response_body["embeddings"][0]["embedding"]
vectors.append({
"key": f"text:{text[:50]}", # 고유 식별자
"data": {"float32": embedding},
"metadata": {"type": "text", "content": text}
})
print(f" ✓ Generated embedding for: {text}")
# 한 번의 호출로 저장할 모든 벡터 추가
s3vectors.put_vectors(
vectorBucketName=VECTOR_BUCKET,
indexName=INDEX_NAME,
vectors=vectors
)
print(f"\nSuccessfully added {len(vectors)} vectors to the store in one put_vectors call!")
# 쿼리할 텍스트
query_text = "foundation models"
print(f"\nGenerating embeddings for query '{query_text}' ...")
# 임베딩 생성
response = bedrock_runtime.invoke_model(
body=json.dumps({
"taskType": "SINGLE_EMBEDDING",
"singleEmbeddingParams": {
"embeddingPurpose": "GENERIC_RETRIEVAL",
"embeddingDimension": EMBEDDING_DIMENSION,
"text": {"truncationMode": "END", "value": query_text}
}
}),
modelId=MODEL_ID,
accept="application/json",
contentType="application/json"
)
response_body = json.loads(response["body"].read())
query_embedding = response_body["embeddings"][0]["embedding"]
print(f"Searching for similar embeddings...\n")
# 가장 유사한 벡터 상위 5개 검색
response = s3vectors.query_vectors(
vectorBucketName=VECTOR_BUCKET,
indexName=INDEX_NAME,
queryVector={"float32": query_embedding},
topK=5,
returnDistance=True,
returnMetadata=True
)
# 결과 표시
print(f"Found {len(response['vectors'])} results:\n")
for i, result in enumerate(response["vectors"], 1):
print(f"{i}. {result['key']}")
print(f" Distance: {result['distance']:.4f}")
if result.get("metadata"):
print(f" Metadata: {result['metadata']}")
print()프로덕션 애플리케이션의 경우 모든 벡터 데이터베이스에 임베딩을 저장할 수 있습니다. Amazon OpenSearch Service는 출시할 때 Nova Multimodal Embeddings와 기본 통합을 제공하므로 확장 가능한 검색 애플리케이션을 쉽게 구축할 수 있습니다. 이전 예시에서 본 것처럼 Amazon S3 Vectors는 애플리케이션 데이터와 함께 임베딩을 저장하고 쿼리하는 간단한 방법을 제공합니다.
알아야 할 사항
Nova Multimodal Embeddings는 3,072, 1,024, 384, 256의 4개의 출력 차원 옵션을 제공합니다. 차원이 클수록 더 자세한 표현이 가능하지만 더 많은 저장 공간과 컴퓨팅이 필요합니다. 차원이 작은 경우 검색 성능과 리소스 효율성 사이에서 실용적인 균형을 제공합니다. 이러한 유연성은 각각의 애플리케이션과 비용 요구 사항에 맞게 최적화하는 데 도움이 됩니다.
이 모델은 상당한 길이의 컨텍스트를 처리합니다. 텍스트 입력의 경우 한 번에 최대 8,192개의 토큰을 처리할 수 있습니다. 비디오 및 오디오 입력은 최대 30초의 세그먼트를 지원하며, 더 긴 파일은 모델이 분할할 수 있습니다. 이 분할 기능은 대용량 미디어 파일을 관리할 때 특히 유용합니다. 이 모델은 파일을 관리 가능한 조각으로 나누고 각 세그먼트의 임베딩을 생성합니다.
이 모델에는 Amazon Bedrock에 내장된 책임 있는 AI 특성이 포함되어 있습니다. 임베딩을 위해 제출된 콘텐츠는 Amazon Bedrock 콘텐츠 안전 필터를 거치며, 편향을 줄이기 위한 공정성 조치가 모델에 포함됩니다.
코드 예제에 설명된 대로 동기식과 비동기식 API를 통해 모델을 간접 호출할 수 있습니다. 동기식 API는 검색 인터페이스에서 사용자 쿼리를 처리하는 등 즉각적인 응답이 필요한 실시간 애플리케이션에 적합합니다. 비동기식 API는 지연 시간에 구애 받지 않는 워크로드를 더 효율적으로 처리하므로 비디오 같은 대용량 콘텐츠를 처리하는 데 적합합니다.
가용성 및 요금
Amazon Nova Multimodal Embeddings는 현재 미국 동부(버지니아 북부) AWS 리전의 Amazon Bedrock에서 사용할 수 있습니다. 자세한 요금 정보는 Amazon Bedrock 요금 페이지를 참조하세요.
자세히 알아보려면 Amazon Nova 사용 설명서의 포괄적인 설명서와 GitHub의 Amazon Nova 모델 쿡북의 실용적인 코드 예제를 참조하세요.
Amazon Q Developer 또는 Kiro 같은 AI 기반 소프트웨어 개발 어시스턴트를 사용하는 경우 AI 어시스턴트가 AWS 서비스 및 리소스와 상호 작용하도록 지원하는 AWS API MCP 서버와 함께 최신 설명서, 코드 샘플, AWS API 및 CloudFormation 리소스의 지역별 가용성에 대한 정보를 제공하는 AWS Knowledge MCP 서버를 설정하면 됩니다.
지금 바로 Nova Multimodal Embeddings로 멀티모달 AI 기반 애플리케이션 구축을 시작하고 AWS re:Post for Amazon Bedrock 또는 기존 AWS Support 담당자를 통해 피드백을 공유하세요.
– Danilo