Amazon Web Services 한국 블로그
Amazon S3 annotations 기능 소개: 쿼리 가능한 리치 컨텍스트를 객체에 직접 첨부 가능
오늘은 Amazon Simple Storage Service(Amazon S3)를 위한 새로운 메타데이터 기능인 S3 annotations (이하, 주석)을 발표합니다. 이 기능을 사용하면 풍부한 대규모 비즈니스 컨텍스트를 객체에 직접 첨부할 수 있습니다. JSON, XML, YAML 또는 일반 텍스트와 같은 유연한 형식으로, 각 객체당 최대 1MB 크기의 명명된 주석을 최대 1,000개까지 저장할 수 있습니다. 객체를 다시 작성하지 않고도 언제든지 주석을 수정하거나 삭제할 수 있으므로, 손쉽게 객체 컨텍스트를 최신 상태로 유지할 수 있습니다.
조직들은 수작업 없이 데이터를 찾고 이해하고 그에 따라 조치를 취하는 AI 에이전트와 자율 워크플로를 구축하고 있습니다. 이러한 에이전틱 워크플로를 지원하려면 데이터와 함께 진화하고, 페타바이트 규모의 객체로 확장하고, 비용이 많이 드는 검색 없이 쿼리 가능한 상태를 유지할 수 있는 메타데이터가 필요합니다.
S3 주석을 사용하면 AI로 생성된 스크립트, 콘텐츠 등급, 기술 사양 등의 컨텍스트를 객체와 함께 직접 저장할 수 있습니다. 컨텍스트는 복사, 복제 및 리전 간 전송 시에 객체와 함께 자동으로 이동하며, 객체를 삭제하면 S3에서 제거됩니다. S3 메타데이터를 활성화하면 Amazon Athena와 기타 분석 엔진으로 쿼리할 수 있는 완전관리형 주석 테이블로 주석이 자동으로 전달됩니다.
일반적인 사용 사례
주석은 여러 산업의 복잡한 메타데이터 문제를 해결합니다.
- 미디어 및 엔터테인먼트: 스크립트, 콘텐츠 조정 결과, 자막 파일 및 라이선스 메타데이터를 비디오 자산에 대한 별도의 주석으로서 추적하므로, 여러 미디어 자산 관리 시스템에 걸쳐 메타데이터를 동기화할 필요가 없습니다.
- 금융 서비스: AI로 생성된 투자 요약 및 감정 분석을 연구 문서에 첨부하여 자율 연구 에이전트가 별도의 메타데이터 데이터베이스를 유지하지 않고도 자연어 쿼리를 통해 관련 데이터 세트를 검색할 수 있도록 합니다.
- 생명 과학: 임상 시험 데이터에 규제 상태, 환자 집단 세부 정보 및 승인 체인을 주석으로 첨부하여, 규정 준수 감사를 가속화하는 동시에 검색 비용 없이 Amazon S3 Glacier 스토리지 클래스의 아카이빙 데이터에 대한 전체 컨텍스트에 액세스할 수 있게 합니다.
주석으로 메타데이터 문제 해결
Amazon S3는 객체를 설명하는 여러 가지 방법을 이미 지원합니다. 시스템 정의 메타데이터는 크기, 스토리지 클래스 등의 속성을 캡처합니다. 객체 태그는 액세스 제어 및 수명 주기 관리와 같은 운영 작업을 지원합니다. 사용자 정의 메타데이터를 통해서는 업로드 시 소량의 사용자 지정 정보를 추가할 수 있습니다.
이러한 기능은 원래 용도로는 잘 작동하지만, 별도의 메타데이터 시스템을 구축 및 유지 관리하지 않고 훨씬 더 풍부한 컨텍스트를 첨부해야 하는 경우에는 한계가 있습니다. 주석은 차원이 다른 규모와 유연성으로 메타데이터 기능을 제공합니다. 즉, 10개의 변경 불가능한 태그나 2KB의 헤더가 아니라, 변경 가능하고 쿼리 가능한 객체별 컨텍스트를 제공함으로써 이러한 니즈를 해결합니다.
| 용량 | 최대 크기 | 변경 가능 여부 | 최적 용도 |
| 시스템 정의 메타데이터 | 고정 | 불가 | 객체 속성(크기, 스토리지 클래스, 생성 시간) |
| 사용자 정의 메타데이터 | 2KB | 불가(업로드 시 설정) | 작은 사용자 지정 키-값 페어 |
| 객체 태그 | 태그 10개, 키/값당 128/256자 | 가능 | 액세스 제어, 수명 주기 규칙, 비용 할당 |
| 주석 | 1GB(1,000×1MB) | 가능 | 리치 비즈니스 컨텍스트(JSON, XML, YAML, 일반 텍스트) |
오늘날 S3 객체를 설명하는 메타데이터는 별도의 데이터베이스나 사이드카 파일에 저장되는 경우가 많아, 데이터 스토리지 비용을 초과할 수 있는 복잡한 동기화 워크플로를 필요로 합니다. S3 메타데이터 주석 테이블을 활성화하면 Amazon Athena를 통해 이 컨텍스트를 대규모로 쿼리할 수 있습니다. AI 에이전트는 AI 모델이 주석을 쿼리하는 데 사용할 표준화된 인터페이스를 제공하는 S3 Tables MCP 서버를 통해 자연어로 데이터를 검색할 수 있습니다. 객체를 복원하거나 검색 요금을 지불하지 않고도 모든 스토리지 클래스의 객체에 대한 주석을 쿼리할 수 있습니다.
주석 사용 시작하기
주석 사용을 시작하려면 AWS Identity and Access Management(AWS IAM) 정책 또는 버킷 정책에서 s3:PutObjectAnnotation 작업과 s3:GetObjectAnnotation 작업에 대한 권한을 부여하는지 확인합니다. 그런 다음 PutObjectAnnotation API를 사용하여 기존 S3 객체나 새 S3 객체에 주석을 추가할 수 있습니다.
예를 들어 미디어 회사는 AWS Command Line Interface(AWS CLI)를 사용하여 비디오 자산에 기술 사양과 AI로 작성된 요약을 첨부할 수 있습니다.
# Create a JSON file with technical metadata
cat > mediainfo.json << 'EOF'
{"codec":"H.265","resolution":"3840x2160","audio_tracks":8,"frame_rate":29.97}
EOF
# 주석으로 첨부
aws s3api put-object-annotation \
--bucket my-media-bucket \
--key videos/documentary-2026.mp4 \
--annotation-name mediainfo \
--annotation-payload ./mediainfo.json
# AI로 생성된 일반 텍스트 요약을 별도의 주석으로 첨부
echo "A 90-minute nature documentary covering wildlife migration patterns across three continents, featuring aerial footage and underwater sequences. Languages: English, Spanish, Portuguese." > ai_summary.txt
aws s3api put-object-annotation \
--bucket my-media-bucket \
--key videos/documentary-2026.mp4 \
--annotation-name ai_summary \
--annotation-payload ./ai_summary.txt
이 명령은 동일한 비디오 객체에 두 가지 개별 주석을 첨부합니다. mediainfo 주석은 구조화된 기술 사양을 JSON으로 저장하고 ai_summary 주석은 텍스트 설명을 저장합니다. 각 주석은 고유한 이름으로 식별되며 각각 개별적으로 읽고 수정할 수 있습니다. 각 주석에 고유한 이름을 지정하면 서로 다른 주석을 사용하여 여러 개의 동시 강화 워크플로를 지원할 수 있습니다. 예를 들어 한 팀은 기술 메타데이터를 추가하고 다른 팀은 콘텐츠 분류를 추가하면서 서로 방해가 되지 않도록 할 수 있습니다.
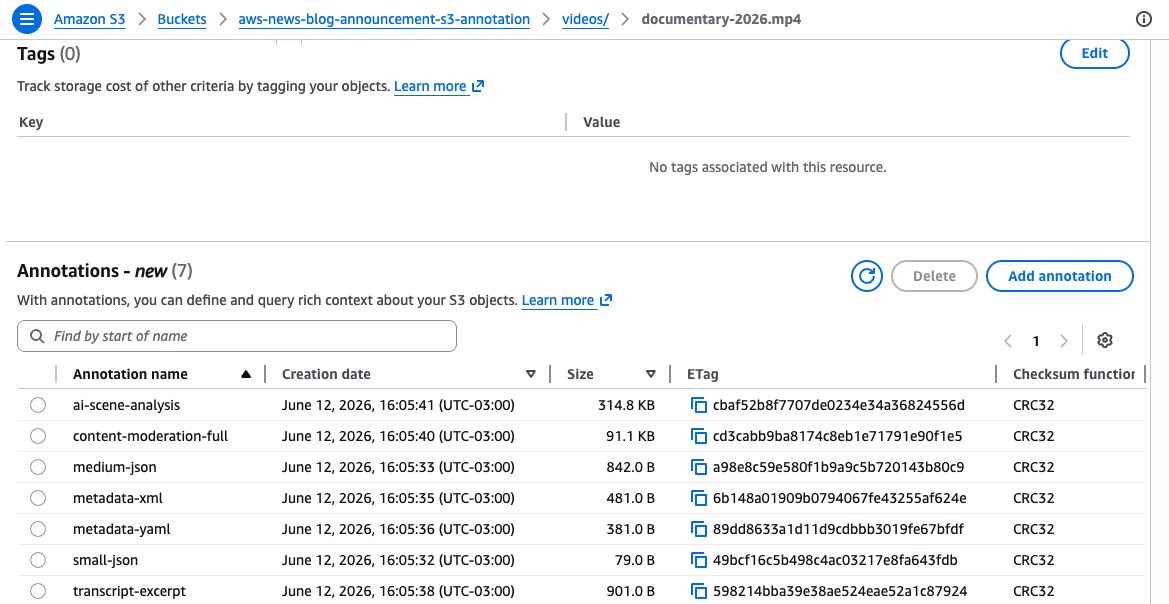
GetObjectAnnotation API를 사용하여 특정 주석을 검색합니다.
aws s3api get-object-annotation \
--bucket my-media-bucket \
--key videos/documentary-2026.mp4 \
--annotation-name mediainfo \
./mediainfo-output.json
객체에 첨부된 모든 주석을 보려면 ListObjectAnnotations API를 사용합니다.
aws s3api list-object-annotations \
--bucket my-media-bucket \
--key videos/documentary-2026.mp4
특정 주석이 더 이상 필요하지 않은 경우 DeleteObjectAnnotation API를 사용하여 해당 주석을 제거합니다.
aws s3api delete-object-annotation \
--bucket my-media-bucket \
--key videos/documentary-2026.mp4 \
--annotation-name mediainfo
동일한 주석 이름으로 PutObjectAnnotation 다시 직접 호출하여 언제든지 기존 주석을 업데이트할 수 있습니다. 멀티파트 업로드를 사용하여 업로드한 큰 객체의 경우, 멀티파트 업로드를 완료한 후 PutObjectAnnotation API를 사용하여 주석을 첨부합니다.
S3 메타데이터 테이블을 사용하여 대규모로 주석 쿼리
개별 객체에 주석을 첨부하는 기능도 유용하지만, 모든 주석을 대규모로 쿼리할 때 훨씬 더 유용합니다. 버킷에서 S3 메타데이터 주석 테이블을 활성화하면 S3는 주석 테이블이라는 완전관리형 Apache Iceberg 테이블에 주석을 자동으로 인덱싱합니다. Amazon Athena 또는 모든 Iceberg 호환 엔진으로 이 주석 테이블을 쿼리할 수 있습니다.
주석 테이블을 활성화하려면 S3 콘솔 또는 CreateBucketMetadataConfiguration API를 사용합니다. 다음 예에서는 변경 내용 추적을 위한 저널 테이블을 유지하고 라이브 인벤토리 테이블을 비활성화한 상태로, 주석 테이블이 활성화된 새 메타데이터 구성을 생성합니다.
{
"JournalTableConfiguration": {
"RecordExpiration": { "Expiration": "DISABLED" }
},
"InventoryTableConfiguration": { "ConfigurationState": "DISABLED" },
"AnnotationTableConfiguration": {
"ConfigurationState": "ENABLED",
"Role": "arn:aws:iam::123456789012:role/S3MetadataAnnotationRole"
}
}
이 구성은 쿼리 가능한 테이블의 모든 주석을 자동으로 캡처하도록 S3에 지시합니다. 적용되면 이 버킷의 객체에 첨부한 모든 주석이 약 1시간 내에 테이블에 표시됩니다.
버킷에 이미 메타데이터 구성이 있는 경우 UpdateBucketMetadataAnnotationTableConfiguration API를 사용합니다.
aws s3api update-bucket-metadata-annotation-table-configuration \
--bucket my-media-bucket \
--annotation-table-configuration '{"ConfigurationState":"ENABLED","Role":"arn:aws:iam::123456789012:role/S3MetadataAnnotationRole"}'
활성화하면 주석이 자동으로 주석 테이블로 이동합니다. 저널 테이블은 거의 실시간으로 업데이트되며, 주석 테이블은 한 시간 내에 새로 고쳐집니다. 사전 정의된 스키마가 필요한 기존 메타데이터 테이블과 달리, 주석 테이블은 사용자가 작성하는 모든 JSON, XML 또는 YAML 구조에 맞게 자동으로 조정됩니다. 각 주석은 text_value 열에 내용이 저장되는 테이블의 행이 되므로, 스키마 마이그레이션 없이 모든 주석을 쿼리할 수 있습니다.
이미 주석이 달린 객체가 있는 버킷에서 주석 테이블을 활성화하면, S3는 테이블에 기존 주석을 자동으로 채웁니다. 이 백필 프로세스는 백그라운드에서 실행되며, 객체 수에 따라 몇 시간에서 며칠이 걸릴 수 있습니다.
예를 들어 Amazon Athena를 사용하여 전체 버킷에서 오디오 트랙이 8개 이상인 모든 비디오 자산을 찾으려면:
SELECT DISTINCT bucket, object_key
FROM "s3tablescatalog/aws-s3"."b_my_media_bucket"."annotation"
WHERE name = 'mediainfo'
AND CAST(json_extract_scalar(text_value, '$.audio_tracks') AS INTEGER) > 8
이 쿼리는 주석 테이블에서 mediainfo라는 주석을 모두 검색하고, JSON 콘텐츠에서 audio_tracks 필드를 추출하고, 개수가 8을 초과하는 객체를 반환합니다.
또는 저널 테이블을 통해 지난 24시간 동안 새 주석을 수신한 객체를 모두 찾으려면:
SELECT bucket, key, version_id, record_timestamp, annotation.name
FROM "s3tablescatalog/aws-s3"."b_my_media_bucket"."journal"
WHERE record_timestamp >= (current_date - interval '1' day)
AND annotation.name IS NOT NULL
AND record_type IN ('CREATE_ANNOTATION', 'DELETE_ANNOTATION')
이 쿼리는 저널 테이블을 사용하여 주석 변경 사항을 거의 실시간으로 추적하므로, 새 주석이나 삭제된 주석에 반응하는 이벤트 기반 워크플로를 구축하는 데 적합합니다.
또한 Amazon SageMaker Unified Studio의 에이전트 또는 S3 Tables MCP 서버가 설치된 모든 IDE를 사용하여, 해당 주석을 기준으로 객체를 자연어로 검색할 수 있습니다. 예를 들어 “2023년에 개봉한 스페인어 자막이 있는 모든 PG 등급 영화를 찾아줘”라고 요청하면 서로 단절된 여러 시스템을 쿼리하는 데 시간을 허비하지 않고 몇 초 만에 결과가 반환됩니다.
지금 시작하기
지금 바로 AWS 중국 리전을 포함한 모든 AWS 리전에서 Amazon S3 주석을 사용할 수 있습니다. 주석 테이블은 S3 메타데이터가 지원되는 모든 AWS 리전에서 사용할 수 있습니다.
데이터를 자율적으로 검색해야 하는 AI 에이전트를 구축하든, 복잡한 메타데이터로 페타바이트급의 미디어 자산을 관리하든, 보관된 데이터 세트의 규정 준수 컨텍스트를 추적하든, 어떤 경우든 주석을 사용하면 별도의 시스템을 관리하지 않고도 리치 메타데이터를 객체에 직접 첨부할 수 있는 확장성과 유연성을 실현할 수 있습니다.
주석 스토리지의 비용은 상위 객체가 S3 Glacier 또는 다른 스토리지 클래스에 있더라도 항상 S3 표준 요금으로 청구됩니다. 자세한 요금 정보는 Amazon S3 요금 페이지를 참조하세요.
자세히 알아보고 시작하려면 Amazon S3 Metadata 개요 페이지와 Amazon S3 설명서를 참조하세요. AWS re:Post for S3 또는 AWS Support 담당자를 통해 피드백을 보내 주세요.
Daniel Abib