AWS 기술 블로그
NVIDIA와 함께 AWS에서 자율주행 3.0을 위한 End-to-End Physical AI 데이터 파이프라인 구축하기
본 블로그는 Olivier Sutter, Geoff Van Natter, Mikhail Yurasov, Amrith Prabhu, Steven DeVries, Wonsik Han이 작성한 Building an End-to-End Physical AI Data Pipeline for Autonomous Vehicle 3.0 on AWS with NVIDIA를 번역, 편집하였으며, 이해를 돕기 위해 Note를 추가했습니다.
도입
자율주행(AV) 개발은 아키텍처 관점에서 명확한 세대 전환이 진행 중입니다.
- AV 1.0: 인지(Perception), 예측(Prediction), 계획(Planning), 제어(Control)로 이어지는 전통적인 모듈형 스택으로, 각 모듈 간 인터페이스를 엔지니어가 수작업으로 설계합니다.
- AV 2.0: 멀티모달 LLM 기반의 E2E(end-to-end) 학습 스택으로, 모듈 간 경계를 줄이고, 데이터 규모에 비례하여 성능을 향상시키는 접근법입니다.
- AV 3.0: E2E Reasoning VLA(Vision–Language–Action) 시스템으로, 인지·추론·행동을 하나의 통합 정책(unified policy)으로 수행합니다. 실제 주행 데이터에 기반하며, closed-loop 시뮬레이션으로 검증합니다.
이러한 VLA 모델은 방대한 양의 실세계 및 합성 센서 데이터를 필요로 합니다. 카메라 피드, LiDAR 포인트 클라우드(point cloud), radar 반사 신호(return), 차량 텔레메트리(telemetry) 등 실제 주행 중 수집되는 모든 데이터가 대상입니다. 이 데이터를 수집하고, 큐레이션하고, 검증하는 작업은 비용이 높고, 시간이 오래 걸리며, 안전에 민감한(safety-critical) 영역입니다.
이 글에서는 AWS와 NVIDIA가 공동으로 설계한 AV 3.0 데이터 파이프라인의 참조 아키텍처를 제시합니다. 차량의 원시 센서 데이터 수집(ingestion)부터, AI 기반 비디오 큐레이션(curation), 신경망 기반 3D 장면 복원(neural 3D scene reconstruction), Reasoning VLA 모델 학습, 그리고 closed-loop 시뮬레이션 검증까지 전 과정을 다룹니다.
이 아키텍처는 아래 테이블과 같이 오픈소스 및 상용 NVIDIA 소프트웨어의 조합으로 구성됩니다:
| NVIDIA 기술 | 역할 |
| Cosmos 파운데이션 모델 | 비디오 이해 및 생성의 기반 모델군 |
| Cosmos Curator | 데이터 큐레이션 파이프라인 |
| Cosmos Dataset Search (CDS) | 시맨틱 기반 데이터셋 검색 |
| Omniverse NuRec | 신경망 기반 3D 장면 복원 |
| Alpamayo | Reasoning VLA 파운데이션 모델 |
이들은 AWS 관리형 인프라 위에서 운영되며, 고객이 인프라 관리가 아닌 혁신에 엔지니어링 리소스를 집중할 수 있도록 글로벌 스케일링을 지원합니다.
차세대 AV 3.0 데이터 플랫폼을 신규 구축하든 기존 인프라를 현대화하든, 이 아키텍처를 각 개발 단계의 참조 가이드로 활용할 수 있습니다 — 특히 확장 가능한 AI 기반 데이터 수집, 검색 중심의 데이터셋 조립, 그리고 빠른 closed-loop 검증에 초점을 맞추었습니다.
아키텍처 개요
AV 3.0 개발은 4개 페이즈(Phase), 8개 단계로 구성됩니다.
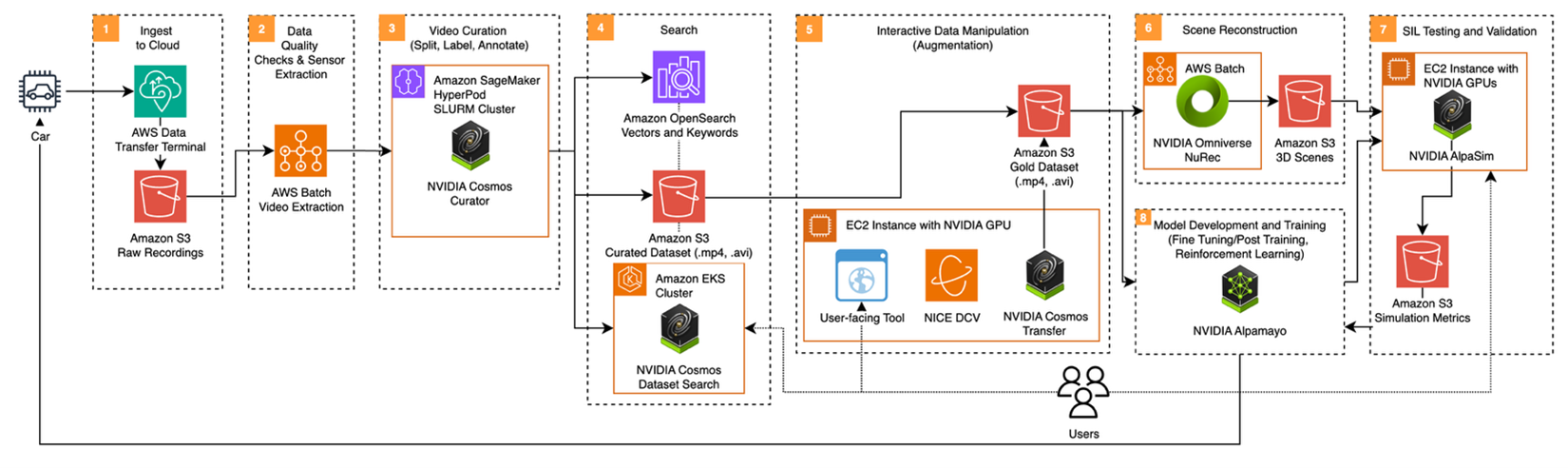
그림 1. AWS와 NVIDIA 기술을 활용한 AV 3.0 개발을 위한 End-to-End Physical AI 파이프라인
이하 각 단계를 상세히 기술합니다.
단계 1: 데이터 수집 (Ingest to Cloud)
각 차량의 데이터 수집 장치(recording unit)는 카메라, LiDAR, radar, IMU(Inertial Measurement Unit, 관성 측정 장치), GNSS(Global Navigation Satellite System, 위성 항법 시스템) 등의 센서 데이터를 연속으로 수집하여 업계 표준 컨테이너 포맷으로 패키징합니다:
- ROS bags (.bag) — 로보틱스 분야의 de facto 표준 녹화 포맷
- MCAP (.mcap) — ROS bag의 차세대 후속 포맷으로, 성능과 확장성이 개선되었습니다
- ASAM MDF4 (.mf4) — 유럽 OEM 중심의 계측 데이터 포맷
원시 녹화 데이터(recording)는 Amazon S3에 저장됩니다. PB 규모의 센서 데이터도 문제없이 수용하며, Amazon S3 Intelligent-Tiering을 설정하면 활성 추출 기간이 지난 오래된 녹화 데이터를 자동으로 저비용 스토리지 클래스로 전환합니다.
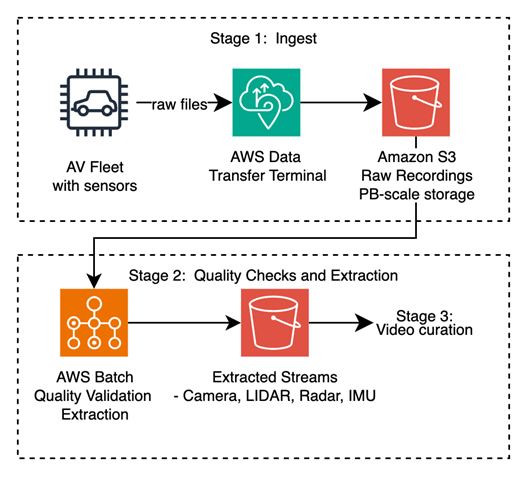
단계 2: 데이터 품질 검증 및 센서 추출 (Data Quality & Sensor Extraction)
AI 처리에 앞서, 원시 녹화 데이터는 품질 게이트(quality gate)를 통과하고 개별 센서 스트림으로 분리(unpacking)되어야 합니다.
품질 검증 (Quality Validation)
각 녹화 데이터는 독립적으로 처리할 수 있으므로, 이 단계에는 AWS Batch가 적합합니다. AWS Batch가 병렬 검증 작업을 오케스트레이션합니다. 고객이 정의하는 검사 항목은 다음과 같습니다:
- 누락된 센서 채널
- 센서 모달리티(modality) 간 타임스탬프(timestamp) 비동기화 (예: radar 10.2Hz vs. 카메라 30.1Hz)
- 파일 손상(corruption)
검증에 실패한 녹화 데이터는 진단 메타데이터와 함께 격리되고, 유효한 녹화 데이터만 다음 단계로 진행됩니다.
센서 추출 (Sensor Extraction)
검증을 통과한 주행 로그(drive log) 컨테이너는 센서 유형별 스트림으로 디코딩됩니다:
| 센서 유형 | 포맷 | 설명 |
| 비디오 | .mp4, .avi | 차량당 다수의 카메라 시점 |
| LiDAR 포인트 클라우드 | .laz | 주행 환경의 3D 공간 측정 |
| radar 반사 신호 | .pcd | 속도 정보 포함 감지 데이터 (4D imaging radar에서 중요성 증가) |
| 텔레메트리 | .csv, .parquet, .json | CAN bus 신호, IMU 측정값, GNSS 위치, 보정된 자차 포즈(calibrated ego pose) |
추출된 스트림은 Amazon S3에 저장되어 이후 데이터 처리 단계에서 활용됩니다.
단계 3: 데이터 큐레이션 (Data Curation)
원시 주행 비디오는 연속적이고, 레이블이 없으며, 대부분 평범합니다(고속도로 순항 등). AV 3.0 학습에는 시나리오 밀도가 높고, 시맨틱으로 검색 가능한 클립이 필요하며, 이를 발견하고 목적에 맞는 데이터셋으로 재조립할 수 있어야 합니다. 이 단계에서는 NVIDIA Cosmos 파운데이션 모델을 사용하여 원시 영상을 큐레이션되고 시맨틱이 풍부한 데이터셋으로 변환합니다.
사용 기술: SLURM (Simple Linux Utility for Resource Management) 스케줄링을 사용하는 Amazon SageMaker HyperPod에서 실행되는 NVIDIA Cosmos Curator. Cosmos Curator는 아래 4개 하위 단계를 상시 운영 GPU 클러스터에서 오케스트레이션하는 통합 데이터 큐레이션 파이프라인입니다.
3-1. 디코딩 및 분할 (Decoding and Splitting)
원본 mp4에서 비디오 프레임을 디코딩하고, 고정 간격(fixed stride) 기반 분할 알고리즘으로 비디오를 개별 클립으로 분할합니다.
3-2. 트랜스코딩 (Transcoding)
각 클립을 동일한 인코딩(예: H.264)으로 개별 mp4 파일로 인코딩합니다.
3-3. 캡셔닝 (Captioning)
NVIDIA Cosmos Reason VLM(Vision-Language Model)이 각 클립을 분석하여 AV에 특화된 고밀도 텍스트 설명을 생성합니다. 일반적인 비디오 캡셔닝과 달리, Cosmos Reason은 안전 관련 이벤트, 교통 법규 위반, 보행자 충돌 상황, 차선 동태(lane dynamics), 악천후 조건 등을 AV 엔지니어링이 요구하는 수준의 구체성으로 식별합니다. Cosmos Reason은 AWS Marketplace에서도 사용 가능합니다.
3-4. 임베딩 (Embedding)
NVIDIA Cosmos Embed가 각 클립에 대해 비디오-텍스트 통합 임베딩(joint video-text embedding)을 생성합니다. 장면 구성, 모션 패턴, 조명 조건, 객체 관계 등의 시각적·시간적 특성을 검색, 중복 제거, 제로샷 분류(zero-shot classification)에 적합한 벡터 표현으로 인코딩합니다.
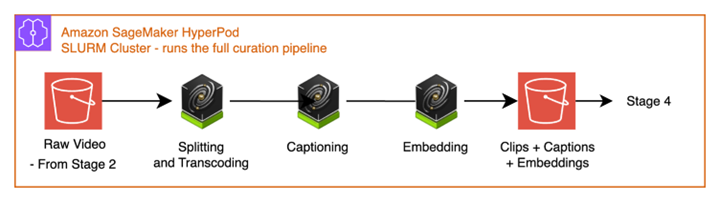
그림 3. Cosmos Curator 큐레이션 파이프라인 — 분할, 캡셔닝, 임베딩
출력: Amazon S3에 저장된 큐레이션된 데이터셋 — 클립별 캡션(caption) 메타데이터(.json)와 인덱싱 준비가 된 벡터 임베딩.
Cosmos Curator가 생성한 벡터 임베딩은 외부 검색 인덱스(단계 4)로 내보내거나, NVIDIA Cosmos Dataset Search (CDS)를 통해 직접 사용할 수 있어, 기존 인프라에 맞는 통합 경로를 유연하게 선택할 수 있습니다.
단계 4: 검색 및 인덱싱 (Search and Indexing)
수천에서 수백만 개의 큐레이션된 클립에서 엔지니어는 특정 주행 시나리오를 빠르게 찾아야 합니다. AV 3.0 개발의 핵심은 검색(retrieval)입니다. 고객은 모델의 약점을 타겟으로 하는 데이터셋을 지속적으로 마이닝하고, 조립하고, 갱신합니다. 이 단계에서는 두 가지 상호 보완적인 검색 경로를 제공합니다.
경로 A: Amazon OpenSearch Service + NVIDIA GPU 가속
Cosmos Curator의 임베딩과 캡션이 Amazon OpenSearch Service에 인덱싱됩니다. NVIDIA cuVS를 통한 GPU 가속으로 대규모 벡터 유사도 검색을 수행합니다.
Amazon OpenSearch Service는 하이브리드 쿼리(hybrid query)를 지원합니다:
- 자연어 텍스트 검색: “Find all unprotected left turns in rain”
- 벡터 유사도 검색: “Find clips that look like this near-miss scenario”
이를 통해 AV 개발이 요구하는 시나리오별 데이터 마이닝이 가능해집니다.
이 경로는 기존 검색 인프라를 보유한 조직이나, 주행 데이터 탐색을 더 넓은 데이터 플랫폼 및 커스텀 도구에 통합하려는 팀에 적합합니다.
경로 B: NVIDIA Cosmos Dataset Search (CDS)
NVIDIA Cosmos Dataset Search(CDS)는 Amazon EKS에서 실행되며, 멀티모달 주행 데이터에 특화된 프로덕션 수준의 검색 경험을 제공합니다. 시각적 UI, 임베딩 기반 검색, 데이터셋 조립 워크플로우, GPU 가속 검색을 포함합니다. 별도 검색 인프라 없이 바로 시나리오 마이닝이 가능한 경로입니다.
Cosmos Curator가 생성한 벡터 임베딩, 캡션, 메타데이터 파일을 CDS에 직접 수집할 수 있습니다. CDS는 메타데이터를 활용하여 학습된 임베딩과 고품질 참조(ground-truth) 신호(캡션, 이벤트, 태그)를 결합한 시맨틱 검색을 제공하며, 보다 정확한 시나리오 마이닝을 가능하게 합니다.
이 경로는 최소한의 통합 노력으로 프로덕션 수준의 검색 경험을 확보하면서, 기존 검색 아키텍처를 완전히 교체하지 않고 CDS의 필요한 컴포넌트만 선택적으로 도입하려는 팀에 적합합니다.
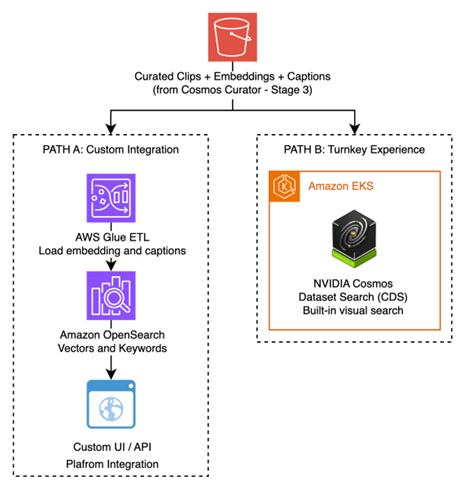
그림 4. 두 가지 검색 경로 — Amazon OpenSearch Service(커스텀 통합) vs. NVIDIA Cosmos Dataset Search(턴키)
두 경로 모두 동일한 후속(downstream) 목표를 지향합니다: 엔지니어링 팀이 Reasoning VLA 모델 학습과 시뮬레이션을 위한 타겟팅된 고품질 데이터셋을 조립하는 것입니다.
단계 5: 데이터 증강 (Data Augmentation)
엔지니어는 검색 도구를 통해 해당 활용 사례(use case)에 중요한 주행 시나리오(우천, 횡단보도, 비보호 좌회전 등)를 데이터에서 탐색합니다. 필요한 장면이 부족한 경우, 생성형 AI로 새로운 테스트 케이스를 생성하여 고품질 데이터를 확보합니다. 이렇게 선별한 데이터는 후속 ML 워크로드에 활용됩니다.
사용 기술: NVIDIA GPU 탑재 Amazon EC2 인스턴스, NICE DCV를 통한 저지연 원격 데스크톱 스트리밍. 기존 클립에서 새로운 장면을 생성하기 위해 NVIDIA Cosmos Transfer는 약 65GB의 GPU 메모리가 필요하며 — Amazon EC2 G7e 인스턴스(96GB GPU 메모리의 NVIDIA RTX PRO 6000 Blackwell Server Edition GPU 탑재)가 적합한 선택입니다.
워크플로우는 세 가지 구성 요소로 이루어집니다:
5-1. 시나리오 탐색 (Scenario Discovery)
엔지니어가 단계 4의 검색 인덱스에 접근하여, 시나리오 유형, 기상 조건, 교통 복잡도, 시각적 유사도별로 큐레이션된 클립을 탐색 및 필터링하여 학습 후보를 조립합니다. 이 과정은 CDS UI 또는 고객 자체 UI를 통해 수행할 수 있으며, 단계 4에서 기술한 검색 경로를 활용합니다.
5-2. 생성형 증강 (Generative Augmentation)
Cosmos Transfer가 선택된 클립의 사실적인 합성 변형을 생성합니다:
- 날씨 변환: sunny, rain, fog, snow 등
- 시간대 변환: sunrise, daytime, sunset, night 등
- 환경 변환: urban, highway, desert, mountain 등
Cosmos Transfer는 원본 장면의 기하학적 구조와 시맨틱 콘텐츠를 보존하면서 물리적으로 타당한 시각적 변형을 생성합니다 — 실제 도로에서 수집하기에 비용이 높거나 위험한 조건에 대한 사실적인 학습 데이터를 만들어냅니다.
단계 6: 신경망 기반 3D 장면 복원 (Neural Reconstruction)
AV 3.0은 카메라 입력에 크게 의존합니다. 이 의존성 때문에 고충실도 센서 시뮬레이션이 필수적입니다: 현실과 괴리가 큰 합성 환경은 모델이 실세계에 대해 보유한 가정을 무너뜨리는 분포 이동(distribution shift)을 유발합니다. 신경망 기반 3D 장면 복원은 실세계 센서 녹화 데이터를 사실적이고 주행 가능한 3D 장면으로 직접 변환하여 이 격차를 줄입니다 — AV 스택이 테스트할 수 있는 환경을 생성하는 것입니다.
사용 기술: AWS Batch에서 GPU 가속 컨테이너로 실행되는 NVIDIA Omniverse NuRec(Neural Reconstruction).
복원 이전에, 멀티모달 센서 입력(보정된 멀티카메라 비디오, LiDAR 포인트 클라우드, 골드 데이터셋의 자차 포즈)이 NVIDIA의 표준 데이터 수집 포맷인 NCore로 변환됩니다.
NuRec는 이 NCore 데이터를 기반으로 Gaussian Splat 방식의 사실적인 3D 장면 표현(scene representation)을 복원합니다. 이 복원 결과는 다음을 캡처합니다:
- 정적 장면 기하 구조(scene geometry) — 도로, 건물, 식생, 표지판
- 장면 외관(scene appearance) — 조명, 텍스처, 재질
- 동적 행위자(actor) — 차량, 보행자 → 독립적으로 제어 가능한 장면 그래프 요소로 분리
동적 에셋(asset)을 처리하기 위해, NuRec는 NVIDIA Asset Harvester에 의존합니다. Asset Harvester는 실제 주행 센서 녹화 데이터에서 특정 객체를 인식 및 추출하는 AI 모델로, 가려지거나 보이지 않는 부분을 생성형 AI로 보완하여 3D 에셋으로 복원합니다. NVIDIA Fixer는 single-step image diffusion model로, 복원 루프 중 출력의 충실도(fidelity)와 새로운 시점(novel view)의 일반화 성능을 향상시키는 데 활용할 수 있습니다.
출력: Amazon S3에 저장되어 시뮬레이션 환경으로 가져올 준비가 완료된 OpenUSD 형식의 재구성된 3D 장면들. 이는 수작업으로 모델링한 근사치가 아니라, 실제 주행 녹화 데이터로부터 도출된 사실적인 디지털 복제본이며, 실제 도로에서 기록된 환경에서의 테스트를 가능하게 합니다.
단계 7: 모델 학습 (Model Training)
큐레이션된 골드 데이터셋과 복원된 3D 장면이 준비되면, 파이프라인은 핵심 과제인 AV 3.0 E2E Reasoning VLA 모델의 학습으로 넘어갑니다.
사용 기술: NVIDIA Alpamayo는 자율주행을 위한 Reasoning VLA(Vision-Language-Action) 파운데이션 모델입니다 — 센서 입력으로 주행 장면을 인지하고, 언어 기반 이해를 통해 추론하며, 궤적 예측(trajectory prediction)을 출력하는 단일 신경망입니다.
AV 1.0의 모듈형 스택을 넘어 통합 정책(unified policy)을 학습하고, AV 2.0을 넘어 추론에 기반한 행동을 강조하는 접근입니다.
학습 워크플로우는 세 단계로 구성됩니다:
- Fine-tuning: 단계 5의 골드 데이터셋을 사용하여 사전 학습된(pre-trained) Alpamayo 모델을 목표 ODD(Operational Design Domain)에 적응시킵니다.
- 강화 학습(Reinforcement Learning): 월드 모델 롤아웃을 사용하여 보상(reward) 기반 학습으로 주행 정책(driving policy)을 대규모로 최적화합니다.
- 최적화(Optimization): 증류(distillation)와 양자화(quantization)로 모델을 엣지 배포(edge deployment)에 준비시켜, 유의미한 정확도 손실 없이 추론 지연(inference latency)을 줄입니다.
모델 개발은 반복적입니다 — 각 학습 주기는 후보 모델을 생성하고, 이 모델은 시뮬레이션(단계 8)에서 평가됩니다. 결과 인사이트가 다음 라운드의 타겟팅된 데이터 큐레이션과 재학습에 반영됩니다.
단계 8: SIL 테스트 (Software-in-the-Loop Testing)
마지막 단계에서 루프가 완성됩니다. 후보 모델이 배포로 진행되기 전에, 이미 복원한 실세계 시나리오를 활용한 closed-loop 시뮬레이션 환경에서 안전 및 성능 메트릭을 정량화하는 엄격한 검증을 거쳐야 합니다.
사용 기술: NVIDIA GPU 탑재 Amazon EC2 인스턴스에서 NVIDIA AlpaSim 실행. AlpaSim은 오픈소스이며, 설정 가능하고 모듈화된 AV 시뮬레이션 프레임워크로, 고충실도 신경망 센서 렌더링을 제공하여 확장 가능한 closed-loop 테스트를 지원합니다. 수백~수천 개 시나리오에 대한 프로덕션 규모의 검증을 위해, AlpaSim은 AWS Batch multi-container job으로 오케스트레이션할 수 있습니다. AlpaSim Renderer는 NVIDIA Omniverse NuRec를 사용하여 새로운 시점을 생성합니다.
시뮬레이션 루프 구성
- 장면 로딩 (Scene Loading): 단계 6의 복원된 3D 장면을 AlpaSim에 로드합니다. AlpaSim은 실제 센서 구성(sensor suite)이 장면을 통과하며 주행하는 것처럼 사실적인 센서 피드를 합성합니다.
- 모델 실행 (Model Execution): 단계 7에서 학습된 Alpamayo 모델이 자차 제어기(ego-vehicle controller)로 배포됩니다. 합성된 센서 입력을 수신하고 실시간으로 주행 명령을 출력합니다.
- 물리 시뮬레이션 (Physics Simulation): AlpaSim이 전체 물리 시뮬레이션을 실행합니다 — 자차가 복원된 세계를 통과하고, 교통 에이전트가 반응하며, 모델의 판단에 따라 시뮬레이션 결과가 달라집니다. 단순 데이터 재생이 아니라, 모델의 행동이 결과를 바꾸는 인터랙티브 시뮬레이션입니다.
- 메트릭 수집 (Metrics Collection): 시뮬레이션된 차량 행동(충돌률, 도로 이탈 등), 신뢰성 메트릭(사고 간 평균 시간 등), 그리고 상위 수준 메트릭(예: 차선 유지)에 걸쳐 성능이 측정됩니다.
출력: Amazon S3에 저장된 구조화된 시뮬레이션 메트릭. 이 인사이트는 단계 5로 직접 피드백됩니다 — 모델이 야간 도심 교차로에서 성능 저하를 보이면, 팀은 야간 데이터를 추가 큐레이션하고, 야간 장면을 추가 복원하며, 해당 시나리오에 대해 fine-tune해야 한다는 것을 파악할 수 있습니다.
전체 조합: 데이터 기반 반복 루프
위 8개 단계는 일회성 선형 파이프라인이 아닙니다. 이 아키텍처의 핵심 가치는 단계 5~8 사이의 반복 피드백 루프에서 나옵니다 — AV 3.0 개발을 확장하는 핵심 메커니즘입니다:
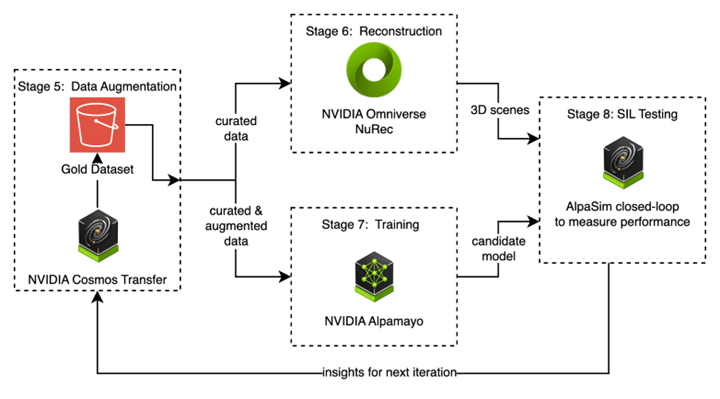
그림 5. 데이터 기반 반복 루프 — 큐레이션 → 복원 → 학습 → 시뮬레이션 → 반복
- 큐레이션 (단계 5): 파악된 모델 약점 기반으로 타겟 시나리오를 선별 및 증강
- 복원 (단계 6): 증강된 센서 데이터를 3D 시뮬레이션 환경으로 변환
- 학습 (단계 7): 타겟팅된 데이터로 주행 모델을 fine-tune
- 검증 (단계 8): 복원된 시나리오에서 모델을 평가하고 성능 점수화
- 반복: 시뮬레이션 인사이트가 실패 모드를 드러내고, 다음 큐레이션 주기를 안내
이 루프는 빠른 가설 검증을 가능하게 하여 개발을 가속합니다 — 예를 들어, “Cosmos Transfer로 학습 데이터를 증강하고 재학습하면 모델이 우천 상황을 더 잘 처리하는가?” — 실세계 데이터 수집에 수 주가 걸리는 질문에 수 시간 내에 답을 얻을 수 있습니다.
이 내부 루프는 더 큰 주기의 일부입니다: 모델이 차량 Fleet에 배포되면 새로운 실세계 데이터를 생성하지만, 훨씬 적은 양입니다. 도로에서 마주친 가장 까다로운 롱테일(long-tail) 시나리오가 단계 1로 피드백되어, 원래보다 훨씬 작고 타겟팅된 데이터셋으로 새로운 반복을 촉발합니다. 각 배포 주기는 점진적으로 더 적은 원시 데이터를 요구하면서, 점점 더 희귀한 실패 모드를 타겟팅하게 됩니다.
시작하기
이 아키텍처에서 기술한 AWS 및 NVIDIA 기술은 현재 사용 가능합니다:
| 구성 요소 | 제공처 |
| NVIDIA Cosmos Curator | GitHub (open source) |
| NVIDIA Cosmos Reason NIM | AWS Marketplace |
| NVIDIA Cosmos Transfer | Hugging Face (NVIDIA Open Model) |
| NVIDIA Cosmos Dataset Search | NVIDIA AI Enterprise on AWS |
| NVIDIA NCore | GitHub (Apache 2.0) |
| NVIDIA Omniverse NuRec | NVIDIA NGC |
| NVIDIA AlpaSim | GitHub (Apache 2.0) |
| NVIDIA Alpamayo | GitHub (open source) |
| NVIDIA Fixer | Hugging Face (NVIDIA Open Model) |
| NVIDIA Asset Harvester | Hugging Face (NVIDIA Open Model) |
| Amazon SageMaker HyperPod | Amazon SageMaker HyperPod |
| Amazon OpenSearch Service | Amazon OpenSearch Service |
| Amazon EC2 G7e Instances | Amazon EC2 G7e |
| AWS Batch | AWS Batch |
AWS에서 Cosmos 파운데이션 모델을 배포하는 방법은 Running NVIDIA Cosmos world foundation models on AWS 블로그를 참조합니다.
결론
AV 3.0 — E2E Reasoning VLA — 은 결국 데이터 품질과 반복 속도와의 싸움입니다. 고객에게 일반적으로 필요한 역량은 다음과 같습니다:
- Fleet 규모의 멀티모달 센서 데이터 수집
- 시나리오 타겟팅된 데이터셋의 큐레이션 및 검색
- 물리적으로 타당한 증강을 통한 커버리지 확대
- 실제 장면을 주행 가능한 3D 환경으로 복원
- AWS 기반 closed-loop 시뮬레이션으로 후보 모델 검증 — 빠르게, 반복적으로, 대규모로
AWS 관리형 서비스(Amazon S3, AWS Batch, Amazon SageMaker HyperPod, Amazon EKS, Amazon OpenSearch Service, Amazon EC2 + Amazon DCV)와 NVIDIA AV 기술(Cosmos Curator, Cosmos Dataset Search, Omniverse NuRec, Alpamayo)을 결합하여, 고객은 원시 Fleet 데이터에서 검증된 주행 모델까지의 End-to-End 파이프라인을 구축할 수 있습니다.
이 아키텍처는 모듈형입니다: 각 단계를 독립적으로 도입하고 기존 시스템과 통합할 수 있습니다. 기존 주행 데이터에서 가치를 추출하기 위해 수집과 큐레이션부터 시작하고, 프로그램이 성숙함에 따라 검색, 증강, 복원, 시뮬레이션을 점진적으로 추가하면 됩니다.
자율주행 개발에 대한 추가 정보는 AWS Automotive 페이지를, NVIDIA Physical AI 플랫폼은 NVIDIA Alpamayo를 참조합니다.
원문 저자 소개
- Olivier Sutter — AWS Vehicle Technology Lead Solutions Architect. 자율주행 및 Software-Defined Vehicle(SDV) 워크로드에 주력하며, 전 세계 자동차 고객이 클라우드 규모의 컴퓨팅, ML, 합성 데이터 생성을 활용한 End-to-End 파이프라인을 구축하도록 지원합니다. Agentic AI와 이를 통한 엔지니어링 워크플로우 가속에도 관심이 깊습니다.
- Geoff Van Natter — NVIDIA Automotive Business Development 리더. 클라우드 제공사와의 GTM 및 파트너십에 주력하며, Physical AI, Industrial AI, Enterprise AI 분야에서 소프트웨어 정의 지능형 차량으로의 전환을 가속하는 전략적 이니셔티브를 주도합니다.
- Mikhail Yurasov — NVIDIA Senior Solutions Architect. 2018년부터 자동차 및 로보틱스 기업을 지원해왔으며, 복잡한 ML 워크로드와 AI 추론 모델을 전문으로 합니다. 고객의 자율주행 개발 가속과 소프트웨어 정의 시스템의 효율적 확장을 돕고 있습니다.
- Amrith Prabhu — AWS Solutions Architect. 엔터프라이즈 고객의 온프레미스 워크로드를 AWS로 마이그레이션하는 복잡한 과제를 해결하는 데 주력합니다. 데이터 및 스토리지 분야의 깊은 배경을 바탕으로 지난 6년간 고객의 클라우드 도입을 지원해왔습니다.
- Steven DeVries — AWS Principal Solutions Architect. Automotive 및 Manufacturing 고객 대상 데이터 및 AI 이니셔티브를 리드합니다. 에이전틱 워크플로우 배포, ML 파이프라인 구축, 생성형 AI 애플리케이션 아키텍처 설계를 통해 신기술을 비즈니스 가치로 전환합니다.
- Wonsik Han — NVIDIA Autonomous Vehicle Group Senior Product Manager. 글로벌 OEM 및 자율주행 스타트업에서 전략, 사업 개발, 제품 관리 분야에 걸쳐 10년 이상의 경력을 보유하고 있습니다.