AWS 기술 블로그
VAMS에서 NVIDIA Isaac Lab을 활용한 GPU 가속 로봇 시뮬레이션 훈련
본 게시글은 AWS Spatial Compute Blog에 작성된 “GPU-Accelerated Robotic Simulation Training with NVIDIA Isaac Lab in VAMS” 블로그를 번역했습니다.
오픈소스 Visual Asset Management System(VAMS)이 이제 NVIDIA Isaac Lab과의 통합을 통해 로봇 자산에 대한 GPU 가속 강화학습(RL)을 지원합니다. 이 파이프라인을 통해 팀은 자산 관리 워크플로우에서 직접 RL 정책을 훈련하고 평가할 수 있으며, 확장 가능한 GPU 컴퓨팅을 위해 AWS Batch를 활용합니다.
Physical AI 및 로봇 개발을 위한 Isaac Lab

그림 1: NVIDIA Isaac Lab에서 훈련된 ANYmal 시뮬레이션
세계는 자율 경제(Autonomous Economy)로 나아가고 있습니다. 이 혁신적인 모델은 AI, 로봇공학, 시뮬레이션, 엣지 컴퓨팅을 결합하여 최소한의 인간 개입으로 작동하는 시스템을 가능하게 합니다. 이러한 변화의 핵심은 물리적 세계를 인식하고, 이해하고, 추론하고, 행동할 수 있는 시스템을 포괄하는 Physical AI입니다.
실제 세계에서 로봇을 훈련하는 것은 느리고, 비용이 많이 들며, 잠재적으로 위험합니다. 보행을 배우는 사족 로봇은 이동 기술을 마스터하기 전에 수천 번 넘어질 수 있습니다. 각 낙하는 수만 달러의 하드웨어 손상 위험을 수반합니다. 시뮬레이션은 이 방정식을 완전히 바꿉니다.
NVIDIA Isaac Lab은 GPU 가속 로봇 시뮬레이션의 최첨단 기술을 대표합니다. Isaac Sim의 고충실도 물리 엔진을 기반으로 구축되어, 정책 복잡도와 GPU 사양에 따라 단일 GPU에서 수천 개의 로봇 인스턴스를 병렬로 실행할 수 있습니다. 실제 세계에서 몇 달이 걸릴 훈련이 몇 시간의 시뮬레이션 시간으로 압축됩니다.
주요 이점:
- 빠른 반복 주기: 새로운 보상 함수, 로봇 설계 또는 제어 전략을 몇 주가 아닌 몇 시간 만에 테스트
- 안전한 탐색: 하드웨어 손상 없이 공격적인 기동을 학습하고 실패에서 복구
- 재현성: 알고리즘 비교 및 개선 추적을 위한 결정론적 환경 제공
- 확장성: 수백 개의 실험을 병렬로 실행하여 체계적인 하이퍼파라미터 검색 가능
그러나 이러한 기능에 접근하려면 전통적으로 상당한 인프라 전문 지식이 필요했습니다. 팀은 GPU 인스턴스를 프로비저닝하고, NVIDIA 드라이버를 구성하고, 컨테이너 이미지를 관리하고, 훈련 인프라와 자산 저장소 간 데이터 이동 파이프라인을 구축해야 했습니다.
VAMS에 Isaac Lab 도입
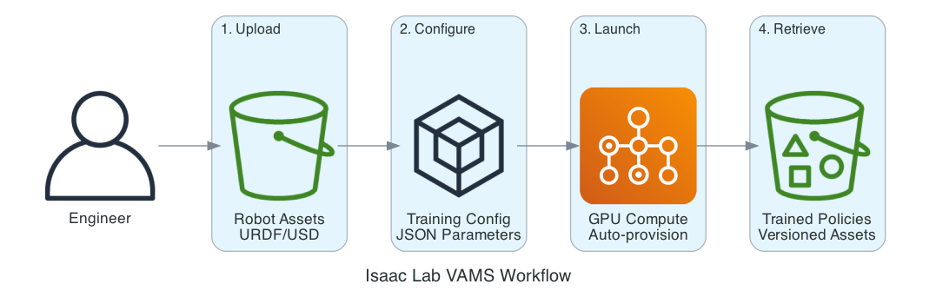
그림 2: Isaac Lab VAMS 워크플로우
VAMS의 Isaac Lab 파이프라인 애드온은 이러한 인프라 부담을 제거합니다. 자산 관리 시스템과 직접 통합하여 로봇 모델에서 훈련된 정책까지 원활한 경로를 만듭니다:
- 로봇 URDF/USD 파일과 사용자 정의 환경을 VAMS에 업로드
- VAMS에 자산으로 업로드된 간단한 JSON 파일을 통해 훈련 매개변수 구성
- GPU 컴퓨팅을 자동으로 프로비저닝하는 작업 시작
- 전체 계보 추적이 포함된 버전 관리 자산으로 훈련된 정책 검색
GPU 인스턴스 관리, 컨테이너 오케스트레이션, 수동 데이터 전송이 필요 없습니다. 파이프라인이 프로비저닝, 실행 및 정리를 자동으로 처리합니다. 이 통합은 시뮬레이션 훈련이 필요하지만 전담 MLOps 리소스가 부족한 팀에게 특히 가치가 있습니다. 로보틱스 엔지니어들은 인프라와 씨름하는 대신 더 나은 로봇과 보상 함수를 설계하는 데 집중할 수 있습니다. 한편, 조직은 VAMS의 자산 추적 기능을 통해 훈련 실험에 대한 중앙 집중식 가시성을 얻습니다.
도전 과제: 자산 관리와 시뮬레이션 연결하기
로봇 자산을 관리하는 조직들은 공통적인 도전 과제에 직면합니다: 그들의 3D 모델, USD 파일, 시뮬레이션 환경은 한 시스템에 있고, 훈련 인프라는 다른 시스템에 존재합니다. 데이터 과학자들은 시스템 간에 자산을 이동하고, 컴퓨팅 리소스를 구성하고, 어떤 정책이 어떤 자산에서 훈련되었는지 추적하는 데 상당한 시간을 소비합니다.
VAMS의 Isaac Lab 파이프라인은 GPU 가속 시뮬레이션 훈련을 자산 관리 워크플로우에 직접 가져옴으로써 이 문제를 해결합니다. 사용자는 VAMS를 떠나지 않고 로봇 자산을 선택하고, 훈련 매개변수를 구성하고, 작업을 시작할 수 있습니다.
아키텍처 개요
파이프라인은 여러 AWS 서비스를 조율하여 원활한 훈련 경험을 제공합니다:
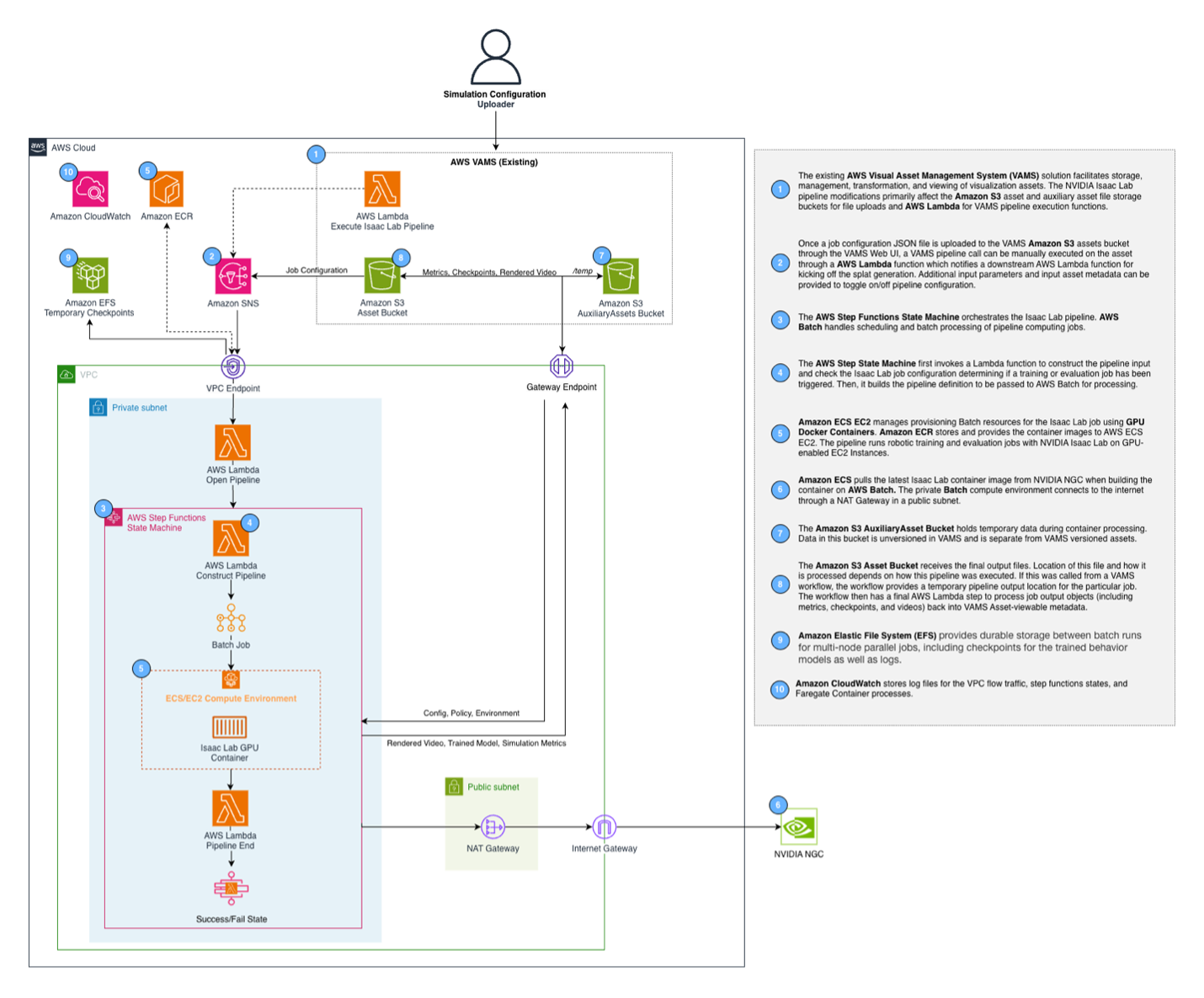
사용자가 훈련 작업을 제출하면 요청은 Amazon API Gateway를 통해 AWS Step Functions 워크플로우를 시작하는 AWS Lambda 함수로 전달됩니다. 이 워크플로우는 작업 구성을 구성하고 AWS Batch에 제출하며 비동기 콜백 패턴을 통해 완료를 기다립니다.
주요 인프라 구성 요소:
- AWS Batch 컴퓨팅 환경: GPU 인스턴스(g6.2xlarge ~ g6e.12xlarge)에서 자동 확장되는 컨테이너화된 환경
- Amazon EFS: 다중 노드 작업 간 훈련 체크포인트를 위한 공유 스토리지
- Amazon ECR: AWS Cloud Development Kit CDK 배포 중 자동으로 빌드되는 Isaac Lab 컨테이너 이미지 호스팅
- AWS Step Functions: 적절한 오류 처리 및 타임아웃으로 워크플로우 조율
- Container Insights: 모니터링 및 관찰 가능성을 위해 Amazon Elastic Container Service (Amazon ECS) 클러스터에서 활성화
컨테이너 자체는 NVIDIA의 공식 Isaac Lab 이미지(nvcr.io/nvidia/isaac-lab:2.3.0)를 기반으로 구축되어 있으며, 최신 시뮬레이션 기능과의 호환성을 보장합니다.
이중 모드 작동: 훈련 및 평가
파이프라인은 두 가지 별개의 모드를 지원하며, RL 개발 수명 주기의 서로 다른 단계를 다룹니다.
훈련 모드
훈련 모드는 처음부터 새로운 정책을 생성합니다. 사용자는 시뮬레이션 작업, 병렬 환경 수, 훈련 반복 횟수를 지정합니다. 파이프라인은 그 외 모든 것을 처리합니다: VAMS에서 사용자 정의 환경을 다운로드하고, 훈련 루프를 실행하고, 체크포인트를 저장하고, 훈련된 정책을 VAMS에 다시 업로드합니다.
일반적인 훈련 구성 예시:
{
"name": "Ant Training Job",
"description": "Train a PPO policy for the Isaac-Ant-Direct-v0 environment",
"trainingConfig": {
"mode": "train",
"task": "Isaac-Ant-Direct-v0",
"numEnvs": 4096,
"maxIterations": 1000,
"rlLibrary": "rsl_rl"
},
"computeConfig": {
"numNodes": 1
}
}numEnvs 매개변수는 GPU 활용을 제어합니다. Isaac Lab은 단일 GPU에서 수천 개의 시뮬레이션 인스턴스를 병렬로 실행합니다. 사족 보행 작업의 경우, 4096개의 환경이 일반적으로 좋은 GPU 포화를 달성합니다.
훈련 출력물은 쉬운 식별을 위해 작업 UUID 아래에 구성됩니다:
- {uuid}/checkpoints/model_.pt – 정기적인 간격의 모델 체크포인트
- {uuid}/metrics.csv – TensorBoard에서 내보낸 훈련 메트릭
- {uuid}/training-config.json – 입력 구성의 사본
- {uuid}/.txt – 로그 파일
평가 모드
훈련된 정책이 있으면 평가 모드를 통해 성능을 평가할 수 있습니다. 이 모드는 기존 정책을 로드하고 지정된 에피소드 수만큼 실행하여 메트릭을 수집하고 비디오를 녹화합니다.
평가 구성 예시:
{
"name": "Ant Evaluation Job",
"description": "Evaluate a trained PPO policy",
"trainingConfig": {
"mode": "evaluate",
"task": "Isaac-Ant-Direct-v0",
"checkpointPath": "checkpoints/model_1000.pt",
"numEnvs": 4,
"numEpisodes": 5,
"stepsPerEpisode": 900,
"rlLibrary": "rsl_rl"
}
}평가는 더 적은 병렬 환경을 사용합니다 (4 대 4096), 목표가 훈련 처리량이 아닌 평가이기 때문입니다.
평가 출력물은 다음을 포함합니다:
- {uuid}/videos/*.mp4 – 녹화된 평가 비디오
- {uuid}/metrics.csv – 평가 메트릭
- {uuid}/evaluation-config.json – 입력 구성의 사본
비디오는 평가 중에 항상 생성됩니다. —video 플래그가 Isaac Lab의 play 스크립트가 적절히 종료되는 데 필요하기 때문입니다.

그림 4: 훈련된 정책의 비디오 평가 출력
체크포인트 발견
파이프라인은 평가를 위한 체크포인트 파일을 지정하는 세 가지 방법을 지원합니다:
- 상대 경로 (권장): 동일한 자산 내의 체크포인트를 참조하기 위해 checkpointPath를 사용합니다, 예: “checkpointsmodel_300.pt”
- 전체 S3 URI: 교차 자산 또는 외부 체크포인트를 위해 policyS3Uri를 사용합니다, 예: “s3://bucket/path/model.pt”
- 자동 발견: 평가 구성과 동일한 디렉토리에 .pt 파일을 배치합니다 (레거시, 하위 호환성을 위해)
VAMS를 통한 작업 실행
VAMS를 통해 Isaac Lab 훈련 작업을 실행하기 전에, VAMS 솔루션과 데이터베이스를 배포하고 설정하기 위해 VAMS 설치 및 시작하기 지침을 따르십시오.
VAMS가 준비되면, 훈련 작업을 실행하는 가장 간단한 접근 방식은 VAMS 웹 애플리케이션을 호출하는 것입니다:
- 실행하려는 작업 유형(예: 훈련 또는 평가)에 대한 구성 JSON을 생성합니다. 다음은 예시 훈련 구성 JSON입니다:
{ "name": "ANYmal Training Job", "description": "Train a PPO policy for the Isaac-Velocity-Rough-Anymal-D-v0 environment", "trainingConfig": { "mode": "train", "task": " Isaac-Velocity-Rough-Anymal-D-v0", "numEnvs": 2048, "maxIterations": 3000, "rlLibrary": "rsl_rl" }, "computeConfig": { "numNodes": 1 } } - 웹 UI를 사용하여 훈련 구성 JSON 파일을 VAMS에 업로드합니다:
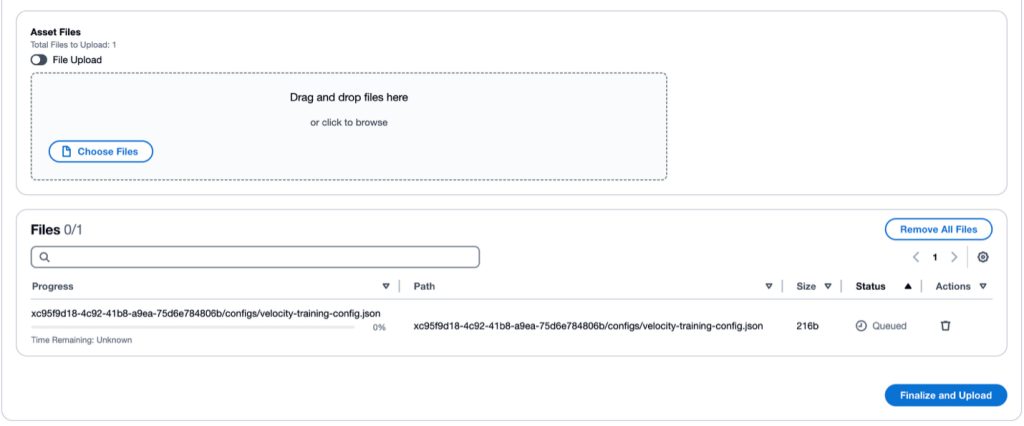 그림 5: 웹 UI를 통해 파일 드래그 앤 드롭하기
그림 5: 웹 UI를 통해 파일 드래그 앤 드롭하기 - Workflows로 이동하여 Isaac Lab Training 또는 Evaluation 파이프라인을 선택합니다
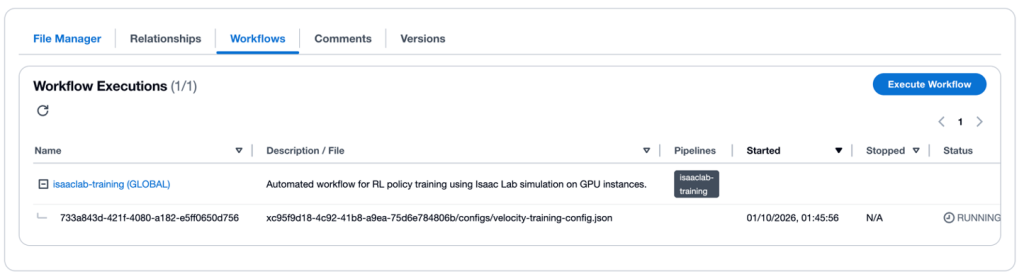 그림 6: VAMS Workflow 탭
그림 6: VAMS Workflow 탭 - Execute Workflow 선택
- 드롭다운에서 isaaclab-training 워크플로우 선택
 그림 7: VAMS Workflow 탭
그림 7: VAMS Workflow 탭 - Select File to Process 드롭다운에서 훈련 구성 JSON 자산 선택
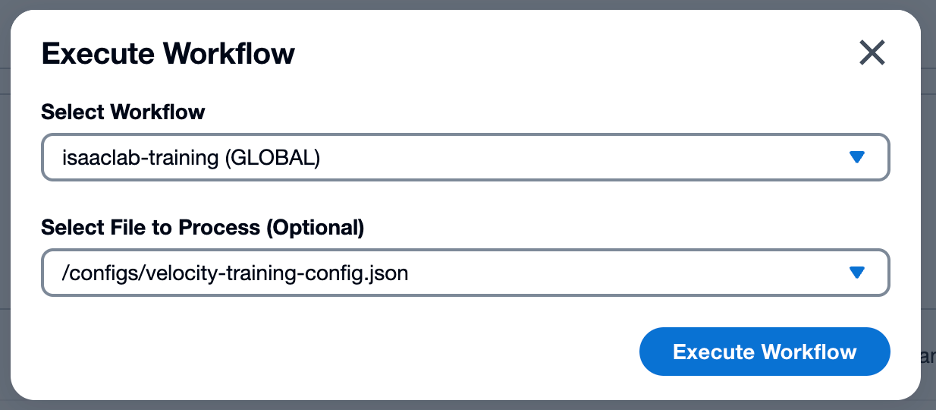 그림 8: VAMS Workflow 파일 선택
그림 8: VAMS Workflow 파일 선택 - Execute Workflow 버튼을 클릭하여 워크플로우 제출
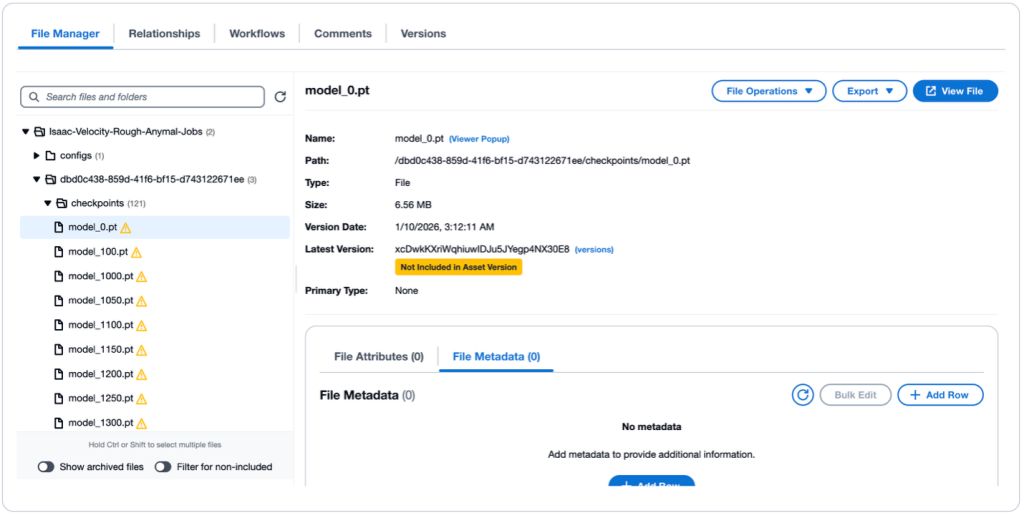 그림 9: Isaac Lab 훈련 작업을 위해 구성된 VAMS Workflow 모달
그림 9: Isaac Lab 훈련 작업을 위해 구성된 VAMS Workflow 모달
VAMS는 실행 상태를 실시간으로 추적합니다. 완료되면, 훈련된 정책은 원래 로봇 자산에 연결된 새로운 자산 버전으로 나타나며, 전체 계보를 유지합니다. 훈련 작업에 대한 전체 세부 정보를 위해, 관리자는 Amazon CloudWatch에서 훈련 출력 로그를 검토할 수 있습니다.
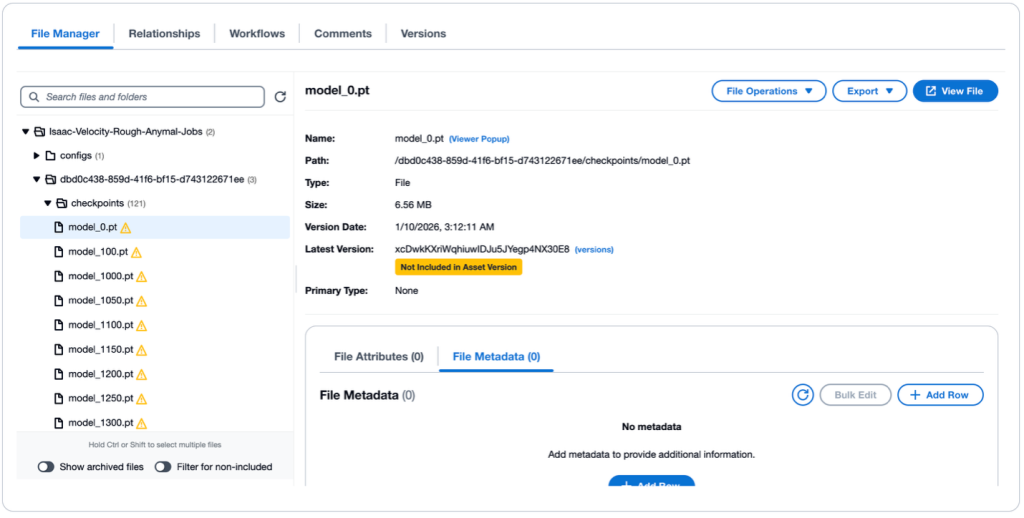
그림 10: VAMS 파일 관리자에서 훈련된 정책 자산
사용자 정의 환경 작업
Isaac Lab에는 40개 이상의 사전 구축된 환경이 포함되어 있지만 많은 프로젝트에는 사용자 정의 작업이 필요합니다. VAMS는 간단한 패키징 워크플로우를 통해 이를 지원합니다.
먼저, Isaac Lab의 템플릿 구조를 따라 사용자 정의 환경을 생성합니다:
my_custom_env/
├── setup.py
├── my_custom_env/
│ ├── init.py # gym.register() 호출 포함
│ ├── my_env.py # 환경 구현
│ └── my_env_cfg.py # 구성요소 클래스들
└── agents/
└── rsl_rl_ppo_cfg.pytarball로 패키징하고 VAMS에 자산으로 업로드합니다:
tar -czf my_custom_env.tar.gz my_custom_env/
# VAMS 웹 UI 또는 API 로 업로드훈련 작업을 제출할 때, 사용자 정의 환경 자산을 참조합니다. 파이프라인은 훈련이 시작되기 전에 자동으로 다운로드하고 설치합니다:
{
"trainingConfig": {
"task": "MyCustom-Robot-v0",
"numEnvs": 4096,
"maxIterations": 5000
},
"customEnvironmentPath": "environments/my_custom_env.tar.gz"
}성능 고려사항
인스턴스 선택
파이프라인은 자동 선택 기능이 있는 여러 GPU 인스턴스 유형을 지원합니다:
 BEST_FIT_PROGRESSIVE 할당 전략을 사용하여 최고의 가격/성능을 위해 G6 인스턴스(L4 GPU)를 우선시하고, 그 다음 G6E(L40S), G5(A10G)를 대체로 사용합니다.
BEST_FIT_PROGRESSIVE 할당 전략을 사용하여 최고의 가격/성능을 위해 G6 인스턴스(L4 GPU)를 우선시하고, 그 다음 G6E(L40S), G5(A10G)를 대체로 사용합니다.
다중 노드 훈련
가장 큰 실험의 경우 파이프라인은 PyTorch의 분산 훈련(torchrun)을 통한 다중 노드 병렬 훈련을 지원합니다. 컴퓨팅 구성에서 numNodes > 1 을 설정하면 됩니다.
{
"computeConfig": {
"numNodes": 4
}
}파이프라인은 AWS Batch의 다중 노드 병렬 작업 기능을 통해 노드 통신을 자동으로 구성합니다. 체크포인트는 Amazon Elastic File System(Amazon EFS)을 통해 공유되며, 모든 노드가 동기화된 상태를 유지하도록 보장합니다.
Isaac Lab과 함께 AWS Batch 다중 노드 훈련을 시작하는 심층 가이드를 위해, AWS의 이 블로그를 참조하십시오.
파이프라인 활성화
Isaac Lab 파이프라인은 VAMS에서 VPC 모드가 활성화되어 있어야 합니다. VAMS 구성 옵션에 대한 전체 세부 정보를 위해, 설정 가이드를 검토하십시오. 다음 위치에 있는 VAMS 구성 파일을 업데이트하십시오: /infra/config/config.json:
{
"app": {
"useGlobalVpc": {
"enabled": true,
"addVpcEndpoints": true
},
"pipelines": {
"useIsaacLabTraining": {
"enabled": true,
"acceptNvidiaEula": true,
"autoRegisterWithVAMS": true,
"keepWarmInstance": false
}
}
}
}중요: NVIDIA 소프트웨어 라이선스 계약을 승인하기 위해 acceptNvidiaEula: true를 설정해야 합니다. 이것이 설정되지 않으면 배포가 실패합니다.

Isaac Lab 매개변수를 포함하도록 구성 파일이 업데이트되면, Isaac Lab 애드온이 포함된 VAMS 솔루션은 표준 VAMS 지침에 따라 배포할 수 있습니다.
배포는 자동으로 Isaac Lab 컨테이너를 빌드하고 Amazon Elastic Container Registry(Amazon ECR)에 푸시합니다. 첫 번째 Batch 작업은 약 10GB 컨테이너 이미지를 가져오는 데 5-10분이 걸릴 수 있습니다; 이후 작업은 인스턴스 캐싱으로 인해 더 빠르게 시작됩니다.
컨테이너 풀 시간 최적화
더 빠른 작업 시작을 위해:
- 웜 인스턴스 유지: 인스턴스를 계속 실행하도록 keepWarmInstance: true를 설정합니다 (최소 8 vCPU). 인스턴스를 웜 상태로 유지하면 파이프라인 실행 비용이 증가합니다. 이 설정은 지정된 수의 EC2 vCPU를 계속 실행합니다.
- AMI 사전 베이크: 컨테이너 이미지가 사전 캐시된 사용자 정의 AMI를 생성합니다
- 더 큰 EBS 볼륨: 파이프라인은 Docker 레이어 캐싱이 있는 100GB GP3 EBS 볼륨을 사용합니다
다음 단계
Isaac Lab 통합은 로봇 자산 워크플로우에 대한 새로운 가능성을 엽니다. GPU 가속 시뮬레이션 훈련을 VAMS로 가져옴으로써, 팀은 자산, 훈련 실행, 배포된 정책 간의 전체 추적성을 유지하면서 로봇 행동에 대해 더 빠르게 반복할 수 있습니다. Isaac Lab의 고충실도 물리 시뮬레이션과 VAMS의 자산 관리 기능의 결합은 로봇 AI 개발을 위한 강력한 플랫폼을 생성합니다.
시작하기
Isaac Lab 파이프라인은 VAMS 2.4.0에서 사용할 수 있습니다. 전체 소스 코드, 상세 문서, 비용 추정 및 문제 해결 가이드는 VAMS GitHub 저장소에서 확인할 수 있습니다.