AWS 기술 블로그
분산 트레이닝 관점에서의 AWS 인터커넥트 기술 소개 – 분산 트레이닝을 위해 알아야 할 GPU 간 고속 통신 기술
대규모 분산 훈련에서 GPU 간 통신 성능은 전체 훈련 효율을 좌우하는 핵심 요소입니다. 수백 대의 GPU가 그래디언트(gradient, 모델이 실수를 고치는 방향 지시서)를 주고받아야 하는 환경에서, 데이터가 GPU 메모리에서 네트워크를 거쳐 원격 노드의 GPU 메모리에 도달하기까지의 경로를 얼마나 효율적으로 설계하느냐가 곧 성능의 차이로 이어집니다.
이번 블로그는 이 시리즈의 마지막 편으로, AWS 인스턴스에서 활용되는 GPU 간 고속 통신 기술의 발전 과정을 데이터 경로와 제어 경로의 관점에서 살펴보겠습니다. GPUDirect RDMA에서 시작하여 GPUDirect Async(IBGDA), NVSHMEM까지 CPU 개입이 단계적으로 제거되어 온 흐름을 짚고, 특히 최근 많은 각광을 받고 있는 MoE(Mixture-of-Experts) 모델의 Expert Parallelism 통신 최적화 관점에서 인피니밴드(InfiniBand) 진영의 DeepEP와 AWS EFA 진영의 PPLX-kernels가 어떻게 다른 접근법을 취하는지 살펴보겠습니다. 이를 통해 하드웨어 스펙보다 네트워크 인터커넥트의 설계 사상을 이해하고 그에 맞는 최적화를 적용하는 것이 왜 중요한지 이해할 수 있기를 기대합니다.
시리즈 블로그 보기
- 분산 트레이닝 관점에서의 AWS 인터커넥트 기술 소개 – AWS는 왜 인터커넥트 기술로 EFA를 사용하는가?
- 분산 트레이닝 관점에서의 AWS 인터커넥트 기술 소개 – AWS의 인터커넥트 기반 기술, ENI 소개
- 분산 트레이닝 관점에서의 AWS 인터커넥트 기술 소개 – AWS 환경에서 NCCL을 이용한 GPU 간 통신
- 분산 트레이닝 관점에서의 AWS 인터커넥트 기술 소개 – 분산 트레이닝을 위해 알아야 할 GPU 간 고속 통신 기술
전송경로에서 CPU를 우회하는 GPUDirect RDMA
직전 블로그에서도 NCCL을 이용하여 GPU 간 통신을 설명하기 위해 GPUDirect RDMA를 여러 차례 언급한 적이 있습니다.
전통적인 GPU 간 노드 간 통신에서는 데이터가 GPU 메모리에서 CPU 메모리로 복사된 후, CPU가 네트워크 카드를 통해 원격 노드로 전송하는 방식을 사용했습니다. 이 과정에서 GPU 메모리와 CPU 메모리 간의 PCIe 복사가 송신단과 수신단에서 각각 한 번씩 총 두 번 발생하고, CPU가 전송 과정 전반을 관리해야 하므로 레이턴시가 증가하고 CPU 자원이 낭비됩니다.
GPUDirect RDMA(GDR)는 NVIDIA가 개발한 기술로, 이 문제를 데이터 경로 측면에서 해결합니다. 전통적인 방식에서는 GPU 메모리의 데이터가 CPU 메모리를 거쳐 NIC으로 전달되었지만, GPUDirect RDMA는 NIC이 PCIe를 통해 GPU 메모리에 직접 접근하여 데이터를 읽을 수 있게 합니다. 정확히는, GPU 드라이버가 전송에 사용할 GPU 메모리 영역의 물리 주소를 고정(pin)하여 NIC에 등록해두면, 이후 NIC이 해당 물리 주소로 DMA를 수행하는 방식입니다. 이를 통해 노드 내부에서 CPU 메모리를 경유하는 복사가 제거되어 전송 레이턴시가 크게 줄어듭니다.
AWS에서는 p4d.24xlarge 인스턴스(2020년 출시)부터 GPUDirect RDMA를 지원하기 시작했습니다. 여기에 EFA(Elastic Fabric Adapter)가 결합되면 두 가지 최적화가 함께 적용됩니다. GPUDirect RDMA는 노드 내부에서 CPU 메모리 경유를 제거하고, EFA의 커널 바이패스 구조는 노드 간 전송 시 OS 네트워크 스택 경유를 제거합니다. 두 기술의 결합으로 GPU 메모리에서 원격 노드의 GPU 메모리까지 CPU와 OS 스택을 모두 우회하는 직접 전송 경로가 완성됩니다.
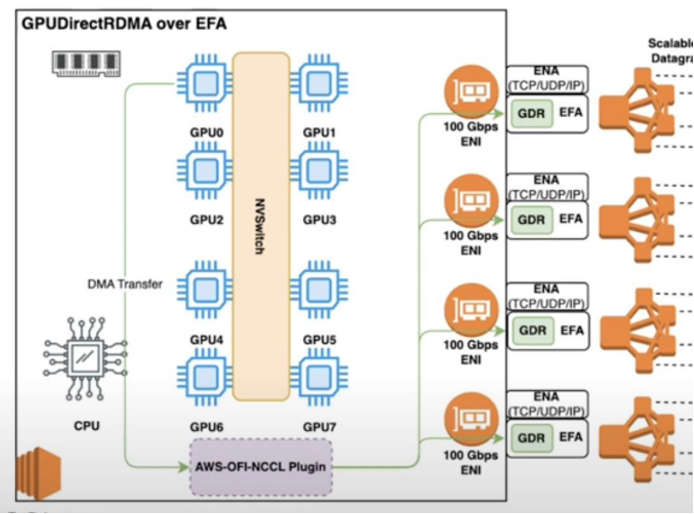
<그림1. GPUDirect RDMA의 기본 개념>
그림1은 p4d.24xlarge(EFA 총 대역폭 400Gbps, 4 × 100Gbps EFA) 기준의 GPUDirect RDMA over EFA 구조를 보여줍니다. 8개의 GPU가 NVSwitch를 중심으로 연결되어 있고, 각 EFA NIC에는 GPUDirect RDMA 기능이 활성화되어 있습니다. CPU는 그림 왼쪽에 별도로 표시되어 있는데, 데이터 전송 경로에서 CPU가 배제되어 있음을 시각적으로 나타냅니다. GPU와 EFA NIC 사이의 통신은 지난 블로그에서 소개한 AWS-OFI-NCCL 플러그인이 중개하며, 이를 통해 NCCL 기반의 집합 통신(AllReduce 등)이 EFA 위에서 효율적으로 동작합니다.
그러나 기본적인 GPUDirect RDMA 구현에는 한 가지 한계가 있습니다. 데이터 자체는 CPU를 거치지 않지만, 전송 명령(Work Request)을 NIC에 전달하는 과정에는 CPU가 여전히 개입합니다. 이 오버헤드는 수 마이크로초 수준이지만, 작은 메시지를 빈번하게 주고받는 워크로드에서는 이 지연이 누적되어 병목이 될 수 있습니다. 이를 해결하기 위해 GPU가 CPU를 거치지 않고 직접 NIC에 전송 명령을 내리는 GPUDirect Async 기술이 등장했으며, 이에 대해서는 다음 섹션에서 다룹니다.
데이터 전송 제어 경로에서 CPU 개입을 제거하는 GPUDirect Async
GPUDirect Async는 이 제어 경로의 CPU 개입마저 제거합니다. GPU 커널이 네트워크 카드의 명령 큐에 직접 쓰기를 수행하여, CPU를 거치지 않고 즉시 DMA 전송을 시작할 수 있습니다. NVIDIA의 IBGDA(InfiniBand GPUDirect Async) 기술을 활용하면, GPU의 Streaming Multiprocessor(CUDA 코어들을 묶은 연산 단위)가 네트워크 카드와 직접 통신하여 제어 경로의 레이턴시를 크게 줄일 수 있습니다. NVIDIA 공식 벤치마크에 따르면, IBGDA는 1KB 미만의 소규모 메시지에서 기존 대비 최대 9.5배의 처리량 향상을 달성했습니다.
이러한 기술의 발전을 정리하면, 데이터 경로와 제어 경로에서 CPU 개입이 단계적으로 제거되어 온 과정으로 이해할 수 있습니다. 전통적인 방식에서는 데이터 경로와 제어 경로 모두 CPU가 관여했고, GPUDirect RDMA에서는 데이터 경로의 CPU를 제거했으며, GPUDirect Async에서는 제어 경로의 CPU까지 제거하여 GPU와 네트워크 카드 간의 직접 통신을 실현했습니다.
이해를 돕기 위해 고속도로에 비유해 보겠습니다. GPUDirect RDMA만 있을 때는, 고속도로(직접 데이터 경로)는 뚫려 있지만 데이터를 보낼 때마다 CPU라는 교통 관제소에 “지금 출발해도 되나요?”라고 물어보고 허락을 받아야 했습니다. CPU가 대답해 줄 때까지 GPU는 잠시 대기해야 했습니다. GPUDirect Async가 추가되면, GPU가 CPU의 허락 없이도 “데이터 준비됐으니 내가 바로 보낸다”하고는 스스로 출발합니다. 교통 관제소를 호출하는 시간조차 아끼게 되어, GPU가 쉬지 않고 계속 일할 수 있습니다.
GPUDirect RDMA가 GPU 사이의 전용 차선을 만든 것이라면, GPUDirect Async는 그 차선 위에서 CPU라는 신호등마저 제거한 기술입니다.
현재 AWS의 P4d, P5, P5en 인스턴스는 GPUDirect RDMA를 EFA 네트워크와 결합하여 데이터 경로에서의 CPU 개입을 제거하고 있습니다. 다만 GPUDirect Async(IBGDA)는 NVIDIA InfiniBand verbs 기반 기술로, SRD 프로토콜 기반인 AWS EFA에서는 직접 지원되지 않습니다.
실전 사례: DeepEP는 왜 AWS에서 느려지는가?
이러한 GPUDirect RDMA와 GPUDirect Async의 차이가 실제 워크로드에서 어떤 영향을 미치는지 보여주는 대표적인 사례가 DeepEP입니다. DeepEP는 DeepSeek에서 개발한 MoE(Mixture-of-Experts) 모델 전용 고성능 통신 라이브러리로, Expert Parallelism에서 발생하는 AlltoAll 토큰 라우팅 통신(각 GPU가 라우팅 결과에 따라 서로 다른 expert로 토큰을 보내는 불균등 집합 통신으로, 모든 GPU가 동일한 양을 주고받는 AllReduce와는 통신 패턴이 다릅니다)을 최적화하기 위해 설계되었습니다. DeepEP V1은 NVSHMEM을 기반으로 하며, 인피니밴드 환경에서는 IBGDA를 활용하여 GPU가 CPU 개입 없이 NIC에 직접 전송 명령을 내리는 방식으로 극도로 낮은 레이턴시를 달성합니다. 이 설계는 인피니밴드 생태계에 강하게 결합되어 있어, 다른 네트워크 환경으로의 이식이 어렵다는 구조적 한계를 가지고 있습니다.
문제는 DeepEP V1을 온프레미스 인피니밴드 환경에서 AWS EFA 환경으로 가져올 때 발생합니다. EFA는 GPUDirect Async를 지원하지 않기 때문에, DeepEP V1이 의존하는 IBGDA 기반 GPU-initiated 통신이 동작하지 않습니다. 대신 GPU와 NIC 사이에 중간 역할을 하는 CPU 프록시(GPU와 NIC 사이를 중개하는 CPU 측 전용 스레드)가 GPU와 NIC 사이를 중개해야 하며, 이 과정에서 추가적인 PCIe 트랜잭션과 수 마이크로초의 오버헤드가 발생합니다. MoE 라우팅에서는 소규모 메시지가 빈번하게 오가기 때문에, 이 오버헤드가 누적되어 체감 성능이 크게 저하됩니다.
이 문제를 해결하기 위해 Perplexity AI는 PPLX-kernels라는 오픈소스 라이브러리를 개발했습니다. 핵심 아이디어는 단순합니다. EFA 환경에서 CPU 프록시를 완전히 없앨 수는 없으니, 대신 CPU가 NIC에게 “보낼 데이터가 있다”고 알리는 횟수 자체를 줄이자는 것입니다. 기존 방식은 GPU가 각 expert로 보낼 데이터를 개별적으로 CPU에게 전달했습니다. PPLX-kernels는 GPU가 먼저 보낼 데이터들을 하나의 버퍼에 모두 모아 놓고, CPU에게는 단 한 번 “이 버퍼 전체를 저쪽으로 보내줘”라고 요청합니다. CPU와 NIC 사이의 대화 횟수가 크게 줄어드는 것입니다.
Perplexity의 벤치마크에 따르면, PPLX-kernels는 ConnectX-7(널리 사용되는 인피니밴드 어댑터 중 하나) 인피니밴드 환경에서 dispatch+combine 합산 레이턴시(토큰을 expert로 보내고 결과를 돌려받는 전체 통신 왕복 시간) 기준으로 DeepEP를 포함한 모든 IBGDA 기반 구현을 상회하는 성능을 달성했으며, AWS EFA 환경에서도 EP16 기준(16개 GPU에 expert를 분산 배치한 구성, 2노드) dispatch+combine 합산 459μs의 레이턴시를 기록하여 1조 파라미터 규모의 MoE 모델 서빙을 가능하게 했습니다. 이는 IBGDA 없이도 전송 패턴을 최적화하면 EFA 환경에서 충분히 경쟁력 있는 성능을 달성할 수 있음을 보여줍니다.
이 사례는 앞서 설명한 GPUDirect RDMA와 GPUDirect Async의 차이가 단순한 이론이 아니라, 실제 프로덕션 워크로드의 성능에 직접적인 영향을 미친다는 것을 잘 보여줍니다. 동시에, 하드웨어 기능의 부재를 소프트웨어 최적화로 극복할 수 있다는 가능성도 시사합니다.
다만 이 사례를 근거로 AWS EFA 기반 인터커넥트 기술이 인피니밴드 보다 열등하다고 결론짓는 것은 적절하지 않습니다. 두 기술은 이 블로그 시리즈의 첫 번째에서 언급한 것처럼, 설계 사상 자체가 다릅니다. 인피니밴드는 NVIDIA가 하드웨어(ConnectX NIC)부터 소프트웨어(NVSHMEM, NCCL, IBGDA)까지 수직 통합한 생태계로, 자사 기술 스택에 최적화된 워크로드에서 뛰어난 성능을 발휘합니다. 반면 AWS EFA는 SRD 프로토콜 기반의 멀티패스 전송, OS-바이패스, 수천 노드 규모의 확장성을 목표로 설계된 클라우드 네이티브 인터커넥트입니다.
DeepEP가 EFA에서 성능이 저하되는 것은 EFA의 한계라기보다, 인피니밴드 전용 기능(IBGDA)에 강하게 결합된 라이브러리를 다른 설계 사상의 네트워크에서 실행했기 때문입니다. 인텔 컴파일러로 최적화한 코드를 AMD 클러스터에서 실행하면 성능이 잘 나오지 않는 것과 같은 이치입니다. 도구가 나쁜 것이 아니라, 네트워크 환경에 맞는 도구를 선택해야 하는 것입니다.
Perplexity의 PPLX-kernels가 이를 증명합니다. EFA의 특성에 맞게 GDRCopy, Unified Memory, 벌크 RDMA write 등을 활용하여 처음부터 설계한 결과, dispatch+combine 합산 레이턴시 기준으로 ConnectX-7 환경의 DeepEP를 포함한 모든 IBGDA 기반 구현을 상회하는 성능까지 달성했습니다. 이는 각 네트워크 인터커넥트의 설계 접근 방식을 이해하고 그에 맞는 최적화를 적용하는 것이 하드웨어 스펙 자체보다 더 중요하다는 것을 보여줍니다.
MoE 최적화의 두 갈래: DeepEP vs PPLX-kernels
앞서 DeepEP 사례를 언급한 김에 Expert Parallelism의 현황에 대해 잠깐 언급하도록 하겠습니다. MoE 모델의 Expert Parallelism 최적화는 하드웨어 환경에 따라 서로 다른 방향으로 발전하고 있습니다. NVIDIA/온프레미스 진영에서는 DeepSeek가 개발한 DeepEP가 인피니밴드 + IBGDA에 최적화된 솔루션으로 자리잡고 있고, AWS 클라우드 환경에서는 Perplexity AI가 개발한 PPLX-kernels가 EFA에 최적화된 솔루션으로 등장했습니다. 어떤 땅(하드웨어)에 빌딩을 짓느냐에 따라 사용하는 중장비(엔진)가 달라지는 것과 같습니다. Perplexity는 추론 워크로드에 AWS 클라우드를 활용하고 있기 때문에, EFA 환경의 특성에 맞는 최적화를 위해 specialized CPU proxy + GDRCopy + TransferEngine 기반의 새로운 아키텍처를 능동적으로 개발한 것입니다.
GDRCopy: IBGDA 없이 CPU-GPU 동기화 병목을 줄이는 법
여기서 PPLX-kernels의 핵심 기술 중 하나이며 AWS에서도 제공되는 GDRCopy에 대해 좀 더 깊이 살펴보겠습니다. EFA 환경에서 MoE 워크로드를 운영할 계획이라면 GDRCopy 설치는 필수 전제 조건입니다. 오픈 소스 기반의 HPC 클러스터 생성 및 관리 도구인 AWS ParallelCluster에는 GDRCopy가 기본 포함되어 있습니다(3.15.0 기준 버전 2.5.2). 단, 이전 버전을 사용하거나 별도 커스텀 AMI를 구성하는 경우에는 Custom Bootstrap Actions(OnNodeConfigured) 기능을 활용하여 설치할 수 있습니다.
GDRCopy가 필요한 이유는 CPU 프록시 구조에서 발생하는 동기화 병목에 있습니다. CPU 프록시 기반 구조에서 핵심 병목은 CPU와 GPU 메모리 사이를 오가는 작은 신호들입니다. 송신 버퍼 패킹 완료 플래그, CPU 프록시가 전송 완료를 GPU에 알리는 전송 완료 알림, 라우팅 메타데이터 — 이런 몇 바이트짜리 정보들을 CPU가 GPU 메모리에서 읽거나 써야 할 때마다 cudaMemcpy를 통해야 합니다.
문제는 CPU가 GPU 메모리를 읽는 방법에 있습니다. CPU에서 GPU 메모리를 읽으려면 PCIe를 통해야 하는데, 이를 위해 cudaMemcpy라는 함수를 사용합니다. 이 함수는 원래 수백 MB 규모의 대용량 데이터를 CPU와 GPU 사이에서 옮기기 위해 설계된 것으로, CPU 프록시가 단 몇 바이트짜리 신호 값 하나를 읽는 데도 약 7μs의 대기 시간이 발생합니다. CPU 프록시가 GPU 상태를 수시로 확인해야 하는 구조에서는 이 7μs가 계속 누적됩니다. cudaMemcpy는 CPU가 GPU 메모리를 직접 읽는 것이 아니라, GPU 내부의 복사 엔진이 데이터를 CPU 메모리로 옮겨주는 방식입니다. CPU는 이 복사가 끝날 때까지 기다려야 하고, 그 준비 시간이 약 7μs입니다.
GDRCopy는 이 문제를 다른 방식으로 해결합니다. GDRCopy는 CPU가 GPU 메모리를 자신의 메모리처럼 직접 읽을 수 있도록 미리 매핑해 두어, CPU가 마치 자기 메모리를 읽듯 GPU 메모리를 직접 읽을 수 있게 합니다. 복사 엔진을 거치지 않으니 대기 시간이 사라지고, 신호 하나를 읽는 데 걸리는 시간이 1μs 미만으로 줄어듭니다.
PPLX-kernels에서 GDRCopy는 CPU 프록시와 GPU 커널 사이의 동기화를 최대한 빠르게 처리하기 위해 활용됩니다. 앞서 언급한 패킹 완료 플래그, 전송 완료 알림, 라우팅 메타데이터 등 몇 바이트짜리 신호들이 모두 GDRCopy를 통해 수 마이크로초 안에 오갑니다.
결국 DeepEP와 PPLX-kernels의 차이는 여기서 명확해집니다. DeepEP는 IBGDA를 통해 GPU가 NIC에 직접 명령을 내리므로 CPU-GPU 간 동기화 자체가 거의 필요 없습니다. PPLX-kernels는 CPU 프록시가 네트워크 제어를 담당하는 구조이므로 동기화가 불가피한데, GDRCopy가 그 동기화의 레이턴시를 극도로 낮춰 IBGDA 부재의 성능 격차를 메우는 역할을 합니다.
필요에 따라 GDRCopy를 사전 포함한 Custom AMI를 생성하는 방법도 있지만, 아래에서 설명하는 이유로 유지보수 부담이 있습니다.
Custom AMI 방식의 한계는 AWS ParallelCluster 버전과의 결합에 있습니다. AWS ParallelCluster는 버전마다 고유한 기본 AMI를 사용하며, Custom AMI는 반드시 해당 버전의 기본 AMI를 베이스로 만들어야 합니다. 예를 들어 AWS ParallelCluster 3.14의 기본 AMI(예시: ami-aaa111)에 GDRCopy를 설치해서 ami-custom-3.14를 만들었다면, 이후 3.16으로 업그레이드할 때 기본 AMI가 새 이미지(예시: ami-bbb222)로 바뀌기 때문에 기존 ami-custom-3.14는 사용할 수 없습니다. 새 버전의 기본 AMI를 베이스로 GDRCopy를 다시 설치해서 ami-custom-3.16을 새로 빌드해야 하며, AWS ParallelCluster 버전을 올릴 때마다 이 과정을 반복해야 합니다.
NCCL의 한계를 극복한 NVSHMEM
NCCL은 현재 대부분의 딥러닝 프레임워크의 기본 통신 백엔드입니다. AllReduce, AllGather 같은 집합 통신(collective)에 최적화돼 있어, Llama 3 70B 같은 Dense Transformer 모델에서는 완벽하게 작동합니다. 이 방식은 기본적으로 모든 GPU가 비슷한 크기의 데이터를 같은 패턴으로 주고받는다는 전제 위에 설계돼 있습니다.
그러나 MoE(Mixture-of-Experts) 모델은 다릅니다. MoE의 Expert Parallelism에서는 각 토큰이 라우팅 결과에 따라 서로 다른 GPU(전문가)로 흩어지는 All-to-All 통신이 일어납니다. 문제는 어떤 전문가는 토큰을 많이 받고 어떤 전문가는 적게 받는 불균등한 구조라는 점입니다. 게다가 어느 토큰이 어디로 갈지는 연산 도중에 동적으로 정해집니다. “모두 같은 양, 정해진 패턴”을 전제로 한 집합 통신으로는 이 불규칙함을 효율적으로 담기 어렵고, 빈 자리를 패딩으로 채우다 보니 대역폭이 낭비됩니다.
이런 통신을 더 잘 다루기 위해 등장한 것이 NVSHMEM입니다. NVSHMEM은 PGAS(Partitioned Global Address Space) 모델을 쓰는 통신 라이브러리로, 여러 노드에 흩어진 GPU 메모리를 하나의 큰 주소 공간처럼 다룹니다. 덕분에 A 서버의 GPU가 B 서버의 GPU 메모리에 데이터를 직접 써넣는 One-sided 통신(Put/Get)이 가능합니다. 받는 쪽이 받을 준비(recv)를 미리 걸어 둘 필요 없이, 보내는 쪽이 원격 메모리에 직접 가져다 놓는 방식입니다(택배를 문 앞에 바로 두는 것처럼). 모든 참여자가 보조를 맞춰야 하는 집합 통신과 달리, MoE의 들쭉날쭉한 라우팅을 자연스럽게 처리합니다.
또 하나의 핵심 차이는 통신을 누가, 언제 시작하느냐입니다. NCCL에서는 통신을 보통 CPU가 시작합니다. CPU가 “이 데이터를 AllReduce 해라”라고 명령을 큐에 넣으면 GPU가 실행하는 구조입니다. 다만 NCCL이 어려워하는 상황이 있습니다.
MoE에서는 GPU가 연산을 하던 도중에 “이 토큰은 3번 전문가로, 저 토큰은 7번 전문가로 보내야겠다”고 목적지를 그 자리에서 정하게 됩니다. 그러나 NCCL은 “누가, 누구에게, 얼마나 보낼지”를 통신을 시작하기 전에 미리 정해 둬야 합니다. 그런데 MoE에서는 그 목적지가 연산 도중에야 정해집니다. 그래서 “연산 중 판단 → 즉시 전송”이 한 번에 이어지지 못하는 것이 NCCL의 근본적인 한계입니다.
NVSHMEM은 여기서 다릅니다. GPU가 커널 실행 도중에 nvshmem_put()을 직접 호출해, CPU를 거치지 않고 원격 GPU 메모리에 바로 데이터를 씁니다. 연산 결과가 나오는 즉시, GPU가 그 자리에서 정한 목적지로 통신이 시작되는 것입니다. 목적지와 타이밍을 GPU가 런타임에 동적으로 결정할 수 있다는 점 — 이것이 MoE의 불균등한 라우팅에서 NVSHMEM이 유리한 본질적 이유입니다.
NVSHMEM의 성능은 하위 전송 계층에 따라 크게 달라집니다. 인피니밴드 환경에서 IBGDA(GPUDirect Async)를 사용하면, GPU의 Streaming Multiprocessor가 CPU 개입 없이 NIC에 직접 명령을 전달하여 극도의 저지연 통신이 가능하다고 앞서 언급하였습니다. 반면 AWS EFA 환경에서는 IBGDA가 지원되지 않으므로, CPU 프록시 스레드가 GPU와 NIC 사이를 중개해야 하며 이 과정에서 레이턴시가 증가합니다.
DeepEP V1은 바로 이 NVSHMEM + IBGDA 조합 위에 구축된 라이브러리입니다. 이후 출시된 DeepEP V2는 NVSHMEM 백엔드에서 NCCL GIN(GPU-Initiated Networking) 백엔드로 전환하여 더 가볍고 높은 성능을 달성했습니다. NCCL GIN은 NCCL 2.28부터 도입된 기능으로, 인피니밴드 외 다양한 네트워크 환경을 지원하는 방향으로 설계되었습니다. 다만 EFA 환경에서의 DeepEP V2 성능은 별도 검증이 필요합니다.
지금까지 설명한 다양한 통신 방식에 대한 관계를 공장 비유로 정리하면 이해가 쉽습니다. 다소 역할이 많아 복잡해 보이긴 합니다만, GPU는 공장, GPU SM은 공장 작업자, NIC은 트럭, CPU 메모리는 창고, CPU 프록시는 사무실 직원이라고 가정하겠습니다.
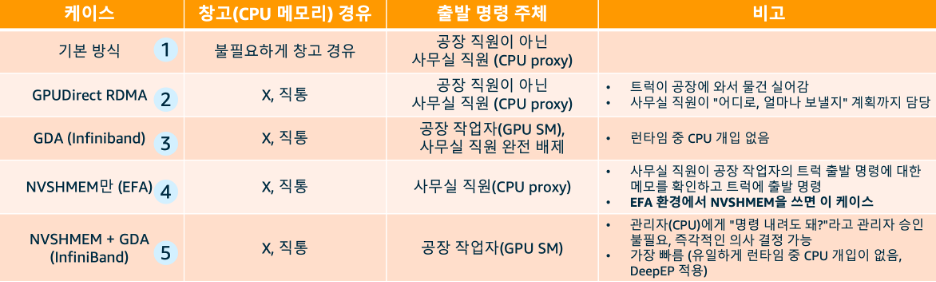
<표1. GPU 노드 간 통신 방식 비교: CPU 개입 단계별 진화 >
표1의 전통적인 기본 방식에서는 공장의 물건을 굳이 창고에 옮긴 뒤, 사무실 직원이 트럭에 싣고 출발 명령을 내립니다. 물건을 받는 목적지 공장에서도 마찬가지로, 트럭이 창고에 물건을 내려놓으면 사무실 직원이 다시 공장 안으로 옮겨야 합니다. 송신과 수신 양쪽에서 창고를 거치는 불필요한 이동이 발생하는 셈입니다.
GPUDirect RDMA(표1의 두번째 방식)에서는 창고를 거치는 단계가 사라집니다. 트럭이 공장에 직접 와서 물건을 싣습니다. 하지만 출발 명령은 현장의 공장 작업자가 아닌 여전히 사무실 직원이 내립니다. 사무실 직원이 “어디로, 얼마나 보낼지”를 결정하고 트럭을 출발시키는 구조입니다.
GPUDirect Async(IBGDA, 표1의 세번째 방식)가 추가되면, 공장 작업자(GPU SM)가 직접 트럭에 출발 명령을 내릴 수 있게 됩니다. 사무실 직원의 개입이 완전히 제거되어 대기 시간이 사라집니다.
AWS EFA 환경에서 NVSHMEM을 사용하는 경우(표1의 네번째 방식)는 조금 다릅니다. 창고를 거치지 않고 트럭이 공장에 직접 오는 것은 GPUDirect RDMA와 같습니다. 하지만 결정적인 차이가 있습니다. GPUDirect RDMA에서는 사무실 직원이 통신의 두뇌 역할을 합니다. 송신 측 공장 작업자(GPU)가 “이 물건은 저쪽 공장으로 보내야 해”라는 결정을 사무실 직원에게 알려주면, 사무실 직원이 “어느 공장으로, 얼마나, 어떤 트럭으로 보낼지”를 직접 계획하고 트럭을 출발시킵니다. 그러나 EFA 환경에서의 NVSHMEM에서는 이 계획 자체를 공장 작업자(GPU)가 직접 세웁니다. 사무실 직원은 그 계획을 받아 트럭에 출발 신호만 전달하는 단순 중계자로 역할이 줄어듭니다.
이 차이가 MoE 같은 워크로드에서 특히 중요합니다. MoE에서는 게이팅 네트워크(Gating Network)가 “이 토큰은 Expert 3번과 7번으로 가야 한다”는 라우팅 결과를 런타임에 동적으로 계산합니다. 이 계산은 GPU에서 일어납니다. GPUDirect RDMA 방식에서는 이 결과를 CPU가 넘겨받아 “Expert 3번이 있는 노드 B의 GPU 2번으로, Expert 7번이 있는 노드 D의 GPU 5번으로 보내야겠다”고 전송 계획을 세우고 NIC에 등록합니다. NVSHMEM에서는 GPU가 원격 메모리 주소를 직접 알고 있어서, 라우팅 결과가 나오는 즉시 GPU가 직접 목적지를 결정하고 필요한 만큼만 데이터를 전송 요청합니다. CPU는 전송 계획 수립에서 빠지므로 CPU 병목이 줄어들고, 불균등한 라우팅 패턴에서도 패딩 없이 실제 데이터만큼만 전송할 수 있습니다.
NVSHMEM과 IBGDA를 함께 사용하는 경우(인피니밴드 환경, 표1의 다섯 번째 방식)가 높은 성능을 제공하는 구조입니다. GPU가 목적지 결정부터 전송 명령까지 모두 직접 처리하며, CPU는 완전히 통신 루프 밖으로 빠져나옵니다. MoE의 불균등한 라우팅 패턴에 가장 최적화된 케이스입니다.
DeepEP가 AWS EFA 환경에서 성능이 저하되는 이유가 바로 여기에 있습니다. DeepEP V1은 처음부터 이 다섯 번째 방식, 즉 IBGDA를 전제로 설계되었습니다. EFA는 IBGDA를 지원하지 않기 때문에 GPU가 직접 전송 명령을 내릴 수 없고, CPU 프록시가 개입하는 구조로 동작하게 됩니다. 이 대기 시간이 고스란히 레이턴시로 쌓입니다.
여기서 한 가지 오해하기 쉬운 부분이 있습니다. NVSHMEM이 MoE의 Expert Parallelism 통신에 유리하다고 해서, NCCL을 완전히 대체하는 것은 아닙니다. MoE 모델이라도 Attention 레이어의 텐서 병렬 통신이나 레이어 간 그래디언트 동기화는 여전히 AllReduce, AllGather 같은 집합 통신으로 처리됩니다. 이 구간은 모든 GPU가 동일한 크기의 데이터를 주고받는 균등한 패턴이므로 NCCL이 여전히 최적입니다. NVSHMEM이 빛을 발하는 구간은 오직 토큰이 각 Expert로 흩어지는 dispatch와 결과를 돌려받는 combine, 즉 불균등한 AlltoAll 통신이 발생하는 MoE 레이어뿐입니다. 결국 하나의 MoE 모델 훈련 안에서도 NCCL과 NVSHMEM은 각자의 역할을 나눠 함께 동작합니다. 경쟁 관계가 아니라 상호 보완 관계인 것입니다. 그리고 AWS EFA 환경에서 MoE 통신을 최적화하려면, 인피니밴드 전용 기능에 의존하는 DeepEP V1 대신 EFA의 특성에 맞게 설계된 PPLX-kernels(현재는 pplx-garden으로 발전) 같은 라이브러리를 활용하는 것이 현실적인 선택입니다.
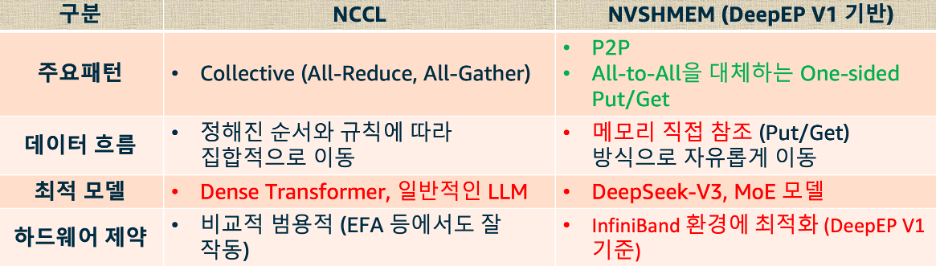
<표2. NCCL과 NVSHMEM의 비교>
맺음말
지금까지 4편에 걸친 시리즈를 통해 AWS 인터커넥트 기술의 전체 그림을 살펴보았습니다.
1편에서는 AWS가 인피니밴드 대신 EFA를 선택한 이유와 두 기술의 철학적 차이를 다루었습니다. 2편에서는 EFA를 실제 인스턴스에 연결하는 메커니즘인 ENI의 구조와 할당 규칙, 그리고 p5.48xlarge와 p6-B300의 실제 구성 방법을 살펴보았습니다. 3편에서는 EFA 네트워크 위에서 GPU 간 통신을 조율하는 NCCL의 동작 원리와 AWS 환경에서의 최적화 방법을 다루었습니다. 그리고 이번 4편에서는 GPUDirect RDMA, GPUDirect Async, NVSHMEM으로 이어지는 GPU 고속 통신 기술의 발전 과정과, MoE 워크로드에서 네트워크 환경에 맞는 최적화가 얼마나 중요한지를 살펴보았습니다.
이 시리즈 전체를 관통하는 핵심 메시지는 하나입니다. 기술의 우열을 따지기보다, 자신이 운영하는 환경의 설계 사상을 이해하고 그에 맞는 도구를 선택하는 것이 성능의 차이를 만든다는 것입니다. 인피니밴드는 전용 환경에서 수직 통합된 생태계의 힘을 발휘하고, EFA는 클라우드 규모의 확장성과 유연성을 바탕으로 그에 맞는 최적화 경로를 제공합니다. DeepEP와 PPLX-kernels의 사례가 보여주듯, 하드웨어 스펙 자체보다 인프라의 특성을 깊이 이해하고 그에 맞게 설계된 소프트웨어가 실제 성능을 결정합니다.
실제 구축을 앞두고 있다면 다음 기준으로 판단하시기 바랍니다. 모든 파라미터가 항상 작동하는 Dense 모델(Llama, Mistral 등) 위주의 훈련이라면 NCCL + EFA 조합으로 충분합니다. 필요한 파라미터만 선택적으로 활성화되는 MoE 모델(DeepSeek-V3, Kimi-K2 등)을 여러 노드에 걸쳐 Expert Parallelism으로 서빙하는 환경이라면 pplx-garden 도입과 GDRCopy 설치를 검토하시기 바랍니다.
AWS 환경에서 대규모 분산 학습을 구축하고 운영하는 분들께 이 시리즈가 인터커넥트 기술에 대한 이해의 폭을 넓히는 데 조금이나마 도움이 되었기를 바랍니다.
마지막으로 AWS AI 인프라 전체를 처음 파악하려는 ML 엔지니어 분이 계시다면 “Building Blocks for Foundation Model Training and Inference on AWS”를 적극 추천 드립니다.