AWS 기술 블로그
Amazon RDS 및 Amazon Aurora와 Amazon OpenSearch Ingestion 통합하기
본 게시글은 AWS Bigdata Blog에 게시된 Integrating Amazon OpenSearch Ingestion with Amazon RDS and Amazon Aurora를 한국어 번역 및 편집하였습니다.
수백만 개의 항목에 대한 강력한 검색 기능은 높은 관련성을 유지하면서 빠르고 정확하며 손쉽게 제공되어야 합니다. 관계형 데이터베이스는 구조화된 데이터를 저장하는 데 널리 사용되는 방법이며, 조직에서는 핵심 비즈니스 정보를 저장하기 위해 관계형 데이터베이스를 광범위하게 사용합니다. 관계형 데이터베이스는 구조화된 데이터를 저장하고 검색하는 데 탁월하지만, 대용량의 비구조화된 텍스트를 검색하는 데 어려움을 겪는 경우가 많으며, 성능상의 이유로 일반적으로 모든 열을 인덱싱하지 않습니다.
반면, OpenSearch와 같은 검색 엔진은 모든 필드를 인덱싱하여 시맨틱 검색을 포함한 풍부한 검색 기능과 숫자 데이터를 요약하고 분석하기 위한 강력한 집계 기능을 제공합니다. 전통적으로 조직은 검색 인덱스를 데이터베이스와 최신 상태로 유지하기 위해 ETL(Extract, Transform, Load) 파이프라인을 포함한 복잡하고 비효율적이며 비용이 많이 드는 데이터 동기화 프로세스를 관리해 왔습니다. 고급 검색 기능으로 애플리케이션을 향상시키려는 조직은 사용자 지정 데이터 동기화 프로세스를 관리하는 오버헤드 없이 데이터베이스와 검색 인덱스 동기화를 유지할 수 있는 더 간단한 솔루션이 필요합니다.
Amazon OpenSearch Service와 Amazon Relational Database Service (Amazon RDS) 및 Amazon Aurora의 통합이 정식 출시되었음을 발표하게 되어 기쁩니다. 이 새로운 통합은 복잡한 데이터 파이프라인을 제거하고 Amazon Aurora(Amazon Aurora MySQL 호환 에디션 및 Amazon Aurora PostgreSQL 호환 에디션 포함)와 Amazon RDS 데이터베이스(Amazon RDS for MySQL 및 Amazon RDS for PostgreSQL 포함), 그리고 Amazon OpenSearch Service 간의 준실시간 데이터 동기화를 가능하게 하여 트랜잭션 데이터베이스에서 하이브리드 검색, 순위가 매겨진 결과, 패싯 검색과 같은 고급 검색 기능을 제공합니다. 이제는 데이터 동기화를 관리하는 대신 뛰어난 고객 경험을 만드는 데 집중하면서 짧은 지연 시간, 높은 처리량의 검색 결과, 실시간 재고 업데이트, 개인화된 추천을 고객에게 제공할 수 있습니다. 이 통합은 복잡한 ETL 파이프라인을 유지관리하는 운영 부담을 줄여 비용을 절감하는 동시에 검색 작업을 위한 즉각적인 데이터 가용성을 제공합니다.
Amazon OpenSearch Ingestion은 Amazon Aurora 또는 Amazon RDS와 OpenSearch Service 간의 준실시간 데이터 동기화를 제공합니다. Aurora 또는 RDS 데이터베이스를 선택하면 OpenSearch Ingestion이 나머지를 처리하며, Aurora MySQL 또는 RDS for MySQL(8.0 이상)과 Aurora PostgreSQL 또는 RDS for PostgreSQL(16 이상)을 모두 지원합니다.
솔루션 개요
다음은 이러한 서비스가 함께 작동하는 방식입니다
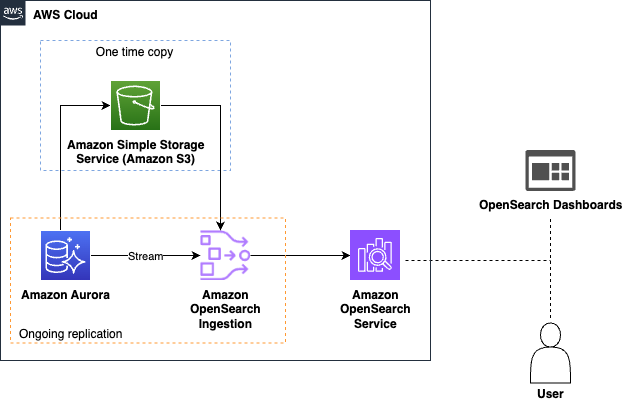
- 데이터 수집 – OpenSearch Ingestion은 먼저 Aurora 또는 Amazon RDS가 초기 데이터를 내보낸 Amazon Simple Storage Service (Amazon S3)에서 데이터베이스 스냅샷을 로드합니다. 그런 다음 Aurora 또는 Amazon RDS의 CDC(Change Data Capture) 스트림을 사용하여 추가 변경 사항을 거의 실시간으로 복제하고 OpenSearch Service에 인덱싱합니다. 이 자동화된 프로세스는 수동 개입 없이 OpenSearch에서 데이터를 지속적으로 최신 상태로 유지하여 검색 및 분석에 즉시 사용할 수 있도록 합니다.
- 실시간 쿼리 – OpenSearch Service는 데이터에 대한 복잡한 검색 및 집계를 수행할 수 있는 강력한 쿼리 기능을 제공합니다. 추세 분석, 이상 징후 감지 또는 애플리케이션에 대한 관련 결과를 반환하는 검색 쿼리 수행이 필요한 경우, OpenSearch Service는 필요한 도구를 제공합니다.
다음 다이어그램은 Amazon Aurora를 소스로 하는 솔루션 아키텍처를 보여줍니다:
시작하기
데이터베이스 소스 구성
동기화를 설정하기 전에 소스 데이터베이스의 로깅 설정을 구성해야 합니다. Aurora MySQL의 경우 향상된 바이너리 로그 설정으로 클러스터 파라미터 그룹을 구성합니다. Amazon RDS의 경우 인스턴스 파라미터 그룹 설정을 통해 기본 바이너리 로깅 또는 논리적 복제를 활성화합니다. 이러한 로깅 구성을 통해 OpenSearch Ingestion이 데이터베이스에서 데이터 변경 사항을 캡처하고 복제할 수 있습니다.
Aurora MySQL을 사용하는 샘플 HR 데이터베이스는 이 통합이 어떻게 작동하는지 보여주는 좋은 예시입니다.
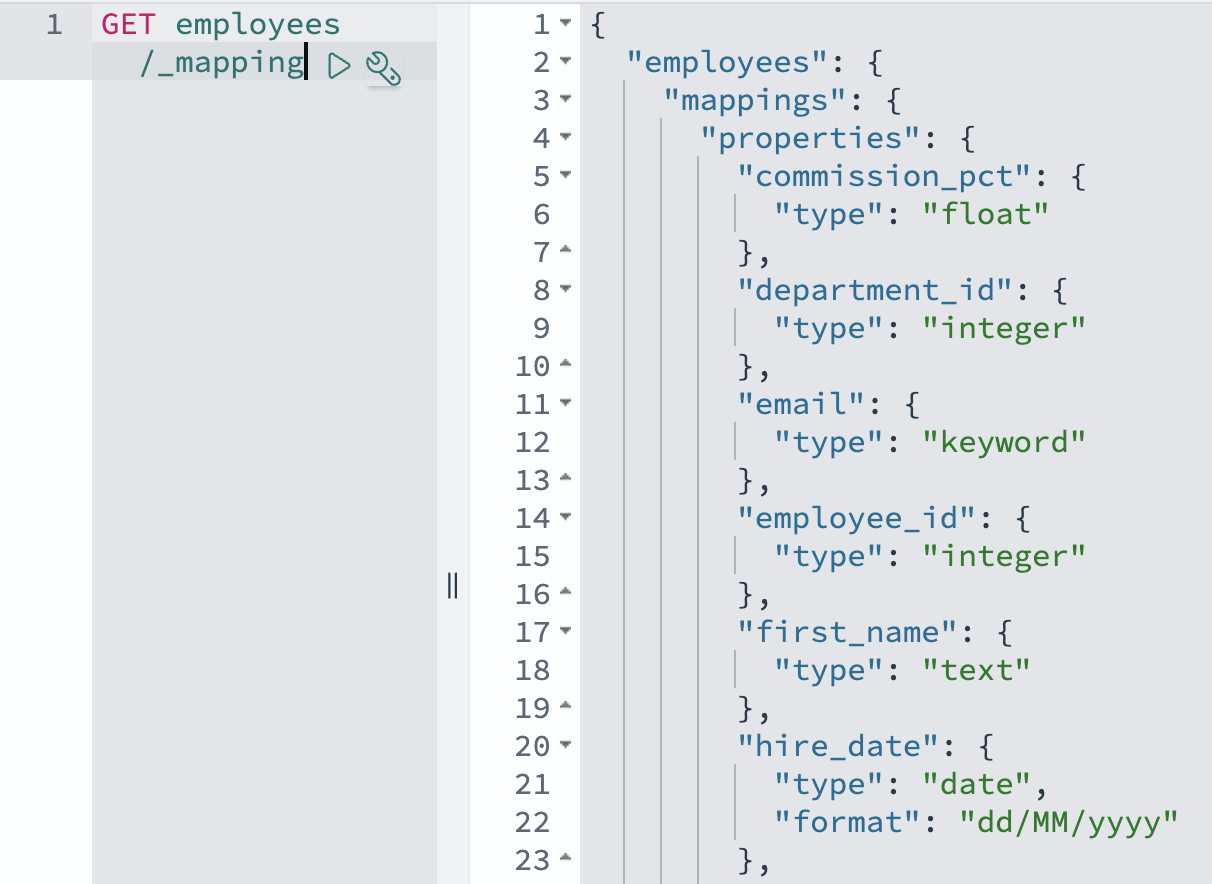
뷰를 생성하기 전에 OpenSearch가 이 데이터를 어떻게 표현하는지 설명하겠습니다. OpenSearch 매핑은 데이터베이스 스키마가 테이블과 열을 정의하는 방식과 유사하게 문서와 해당 필드가 저장되고 인덱싱되는 방법을 정의합니다. OpenSearch Ingestion 파이프라인은 기본적으로 동적 매핑을 사용하여 Aurora 또는 Amazon RDS 데이터 타입을 적절한 OpenSearch 필드 타입으로 자동 변환합니다. 예를 들어, 데이터베이스 DATE 필드는 OpenSearch 날짜 타입이 되고, 숫자 필드는 해당하는 OpenSearch 숫자 타입으로 매핑됩니다. 인덱스 템플릿을 사용하여 이러한 매핑을 사용자 지정할 수 있지만, 기본 매핑은 일반적으로 날짜, 숫자, 텍스트 필드를 포함한 일반적인 데이터 타입을 올바르게 처리합니다.
GET employees/_mapping
통합의 복잡한 데이터 관계 처리 기능을 보여주기 위해 이제 OpenSearch Ingestion이 조인된 데이터를 어떻게 처리하는지 살펴보겠습니다. 샘플 HR 데이터베이스에서 여러 관련 테이블의 정보를 OpenSearch의 단일 검색 가능한 문서로 결합하는 뷰를 생성합니다. 이 접근 방식은 정규화된 데이터베이스 구조를 검색 작업에 최적화된 비정규화된 문서로 변환하는 방법을 보여줍니다.
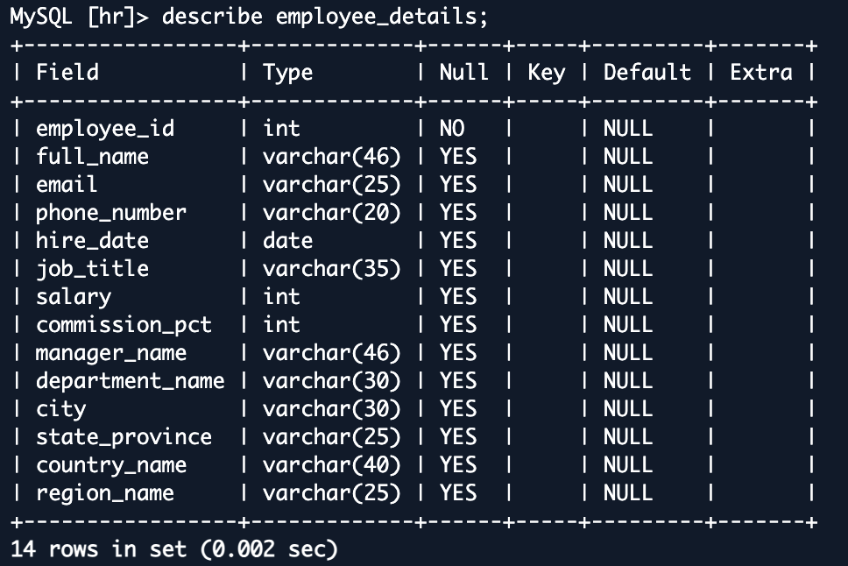
위의 employee_details 뷰는 여러 테이블의 데이터를 결합하여 직원 정보의 풍부하고 비정규화된 표현을 생성합니다. OpenSearch에 복제되면 이 뷰는 각 직원에 대한 단일의 포괄적인 문서가 됩니다. 이러한 구조는 검색 작업에 이상적이며, 원래 별도의 테이블이었던 것에 대해 빠르고 복잡한 쿼리를 허용합니다. 예를 들어, 특정 부서와 국가의 직원을 쉽게 검색하거나 지역별 급여 분포를 분석할 수 있습니다. 이는 원래의 정규화된 데이터베이스 구조에서는 더 복잡하고 잠재적으로 느릴 수 있는 쿼리입니다.
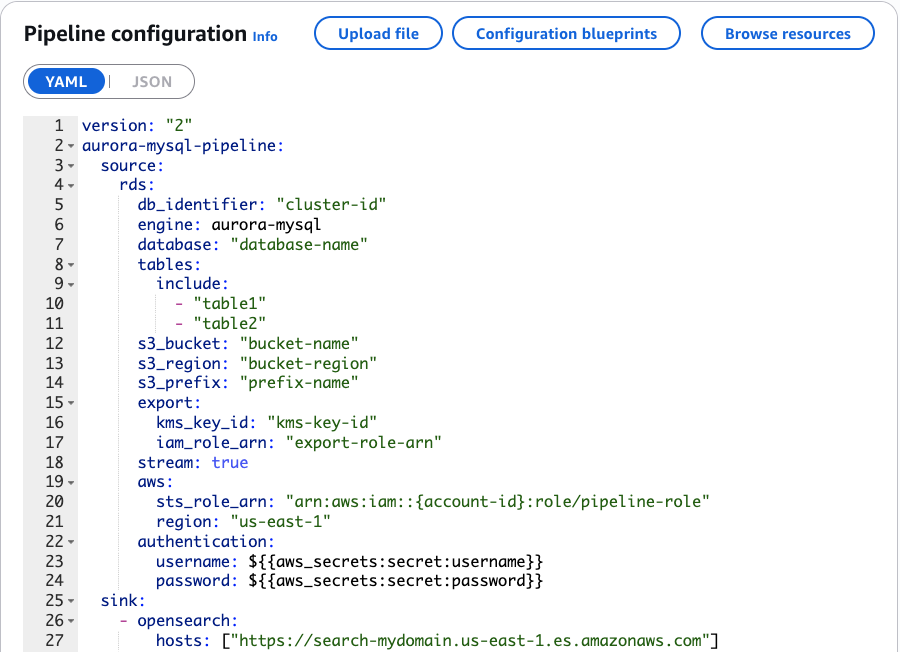
다음 스크린샷에 표시된 파이프라인 구성에서 OpenSearch Ingestion이 HR 데이터베이스에 연결하는 방법을 확인할 수 있습니다. 구성은 소스 데이터베이스와 복제하려는 특정 테이블을 식별합니다. 데이터 관계를 이해하기 위해 뷰를 생성했지만, 파이프라인은 기본 베이스 테이블(직원, 부서, 위치, 지역)의 변경 사항을 추적합니다. OpenSearch Ingestion은 이러한 관계를 자동으로 유지하므로 이러한 테이블의 변경 사항이 OpenSearch 인덱스에 적절히 반영되어 검색 데이터를 소스 데이터베이스와 일관되게 유지합니다.
아래 gif에서 OpenSearch Ingestion의 시각적 편집기를 사용하여 이 통합을 설정하는 데모를 볼 수 있습니다.
또한, 인덱스 매핑 템플릿을 지정하여 Aurora 또는 Amazon RDS 필드를 OpenSearch Service 인덱스의 올바른 필드에 매핑할 수도 있습니다.
파이프라인의 구성 설정에 대한 포괄적인 개요는 OpenSearch Data Prepper 문서를 참조하세요. 파이프라인을 위한 AWS Identity and Access Management (IAM) 역할을 설정해야 합니다. 지침은 파이프라인 역할 구성을 참조하세요.
OpenSearch Ingestion에서 통합을 구성한 후 파이프라인은 OpenSearch Dashboards에서 볼 수 있는 인덱스를 자동으로 생성합니다. OpenSearch Ingestion은 먼저 Aurora 또는 Amazon RDS 데이터베이스의 자동 내보내기를 Amazon S3로 트리거한 다음 S3에서 이 스냅샷 데이터를 OpenSearch 클러스터로 로드하여 초기 인덱스를 생성합니다. 이 초기 로드 후 OpenSearch Ingestion은 MySQL 기반 데이터베이스의 경우 바이너리 로그(binlog)를, PostgreSQL 기반 데이터베이스의 경우 Write-Ahead Log(WAL)를 사용하여 변경 사항을 지속적으로 캡처합니다. 이런 방식으로 OpenSearch 인덱스는 소스 데이터베이스와 거의 실시간으로 동기화된 상태를 유지합니다. 다음을 호출하여 OpenSearch Dashboards에서 인덱스를 볼 수 있습니다:
GET _cat/indices
예시 응답:

준실시간 데이터동기 시연
employees 테이블의 처음 다섯 개 항목을 살펴보겠습니다:

데이터베이스를 변경하면 OpenSearch Ingestion이 변경 데이터로 Amazon OpenSearch Service를 업데이트합니다. 예를 들어, 다음 코드는 직원의 급여를 업데이트합니다:
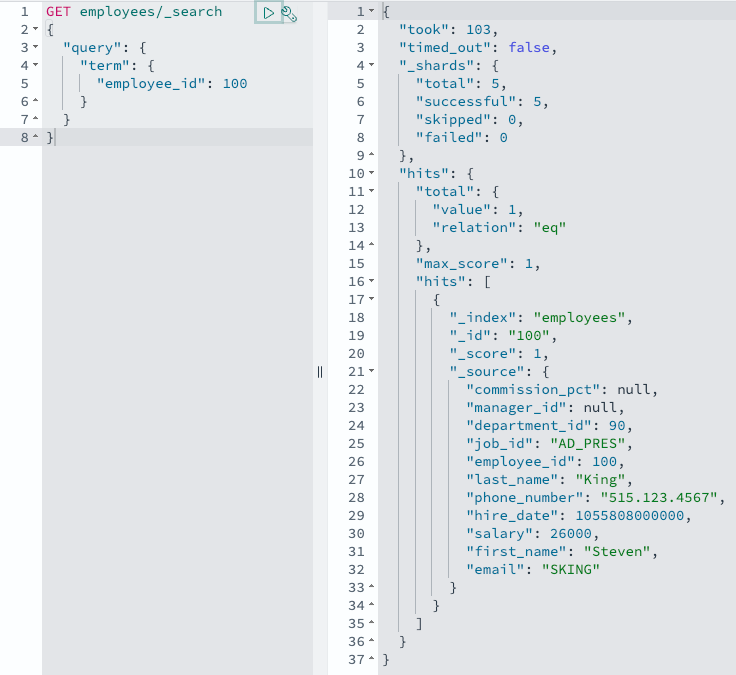
UPDATE hr.employees SET SALARY = 26000 WHERE EMPLOYEE_ID = 100;

Amazon Aurora가 변경 알림을 보내면 OpenSearch Ingestion 파이프라인이 이를 수신하고, OpenSearch Ingestion이 변경된 레코드를 거의 실시간으로 OpenSearch에 전송합니다. OpenSearch 쿼리로 이를 확인할 수 있습니다:
GET employees/_search
이 기능에 대한 중요한 세부 사항:
- 모니터링 – CloudWatch 메트릭과 OpenSearch Ingestion 대시보드를 통해 파이프라인 성능과 데이터 동기화를 추적
- 제한 사항 – 동일 리전 및 동일 계정 배포 필요, 최적 동기화를 위한 기본 키 필요, 현재 DDL(Data Definition Language) 문 지원 없음
결론
Amazon Aurora 또는 Amazon RDS와 Amazon OpenSearch Service의 통합은 이제 OpenSearch Ingestion을 사용할 수 있는 모든 AWS 리전에서 정식 출시되었습니다.
자세한 내용은 Aurora 또는 Amazon RDS와 Amazon OpenSearch Service 통합에 대한 AWS 문서를 참조하세요:
- Amazon Aurora에서 OpenSearch Ingestion 파이프라인 사용 – Amazon OpenSearch Service
- Amazon RDS에서 OpenSearch Ingestion 파이프라인 사용 – Amazon OpenSearch Service