AWS 기술 블로그

Amazon Bedrock 사용량 관리 및 최적화 하기
Amazon Bedrock을 이용하여 다양한 AI 서비스를 구축하고 Poc단계부터 실제 서비스를 런칭하는 단계까지 안정적인 AI 서비스를 구축하는 것은 쉽지 않은 긴 여정입니다. 특히 LLM의 토큰 사용량 관리와 토큰 최적화는 운영서비스를 런칭한 이후 겪게 되는 중요한 문제들이라고 할수 있습니다. AI 서비스를 성공적으로 런칭한 고객들 조차도 LLM 토큰 사용량에 대한 명확한 모니터링, 토큰 최적화, 그리고 리밋 증설하는 부분에서 […]

VAMS에서 NVIDIA Isaac Lab을 활용한 GPU 가속 로봇 시뮬레이션 훈련
본 게시글은 AWS Spatial Compute Blog에 작성된 “GPU-Accelerated Robotic Simulation Training with NVIDIA Isaac Lab in VAMS” 블로그를 번역했습니다. 오픈소스 Visual Asset Management System(VAMS)이 이제 NVIDIA Isaac Lab과의 통합을 통해 로봇 자산에 대한 GPU 가속 강화학습(RL)을 지원합니다. 이 파이프라인을 통해 팀은 자산 관리 워크플로우에서 직접 RL 정책을 훈련하고 평가할 수 있으며, 확장 가능한 GPU 컴퓨팅을 […]

AI-DLC 기반 웅진씽크빅 북큐레이터 AI 에이전트 구축
“2일 만에 AI 에이전트의 MVP를 만들 수 있을까요?” 2025년 12월, 웅진씽크빅과 함께 AWS AI-DLC 워크숍(Unicorn Gym)을 진행하면서 이 질문에 대한 답을 찾았습니다. 결론부터 말하면, 가능했습니다. AI-DLC(AI-Driven Development Life Cycle) 방법론을 적용하여 북큐레이터를 위한 AI 에이전트의 MVP를 단 2일 만에 완성했고, 약 한 달간의 고도화를 거쳐 2026년 1월 베타 서비스를 오픈했습니다. 이 글에서는 AI와 개발자가 협업하는 […]

Kiro Subagent 를 활용한 구조화된 AI 개발 워크플로우 구축
AI 코딩 어시스턴트의 발전으로 개발자들은 이제 자연어로 코드를 생성하고, 복잡한 시스템을 빠르게 구축할 수 있게 되었습니다. 하지만 이러한 편리함 뒤에는 중요한 질문이 남습니다: AI가 생성한 코드의 품질과 보안을 어떻게 체계적으로 보장할 수 있을까요? 이 글에서는 Anthropic의 Multi-agent 연구 결과를 살펴보고, Kiro의 Subagent 기능을 활용하여 코드 리뷰, QA, 문서화가 체계적으로 수행되는 개발 워크플로우를 구축하는 방법을 소개합니다. 본 글에서는 […]

Agentic AI 기반 플랫폼 – 7주만에 기획부터 배포까지, Part1: AI-DLC 방법론과 유용한 도구들
들어가며 최근 저자들은 단 2명이서 7주 만에 Agentic AI 기반 플랫폼을 엔드투엔드로 구축했습니다. 디자이너도 없었고 기획자도 없었습니다. MCP(Model Context Protocol) 생성, AI Agent 생성부터 실시간 테스트 환경까지 갖춘 플랫폼이었고, 단순한 아이디어에서부터 실제 동작하는 웹 애플리케이션까지, 2주의 기획, 2주의 문서작업 및 세부 사항 협의, 3주의 개발 및 배포 기간이 소요되었습니다. 예전의 전통적인 개발 방법으로는 상상도 못할 […]

AWS Transform Custom을 활용한 ASP.NET 모노리스 애플리케이션을 마이크로서비스로 변환하기
클라우드 이전 시대에는 모노리스 아키텍처가 일반적이었습니다. 그러나 클라우드 환경이 도래한 이후 마이크로서비스가 현대적 아키텍처의 주류로 자리잡았습니다. 이러한 측면에서 레거시 애플리케이션을 클라우드 친화적인 애플리케이션으로 마이그레이션 할 경우, 확장성과 가용성 향상을 위해 마이크로서비스 전환을 고려하게 되지만, 실제 구현은 상당한 복잡도를 수반합니다. AWS Microservice Extractor for .NET는 ASP.NET 모노리스 애플리케이션의 마이크로서비스 전환을 지원하는 UI 기반 도구였으나, 신규 사용자에 […]

Amazon EKS에서 Friendli Container로 LLM 추론 최적화하기
FriendliAI는 AI 추론 효율을 크게 개선하는 고성능 서빙 플랫폼을 서비스하는 기업입니다. FriendliAI의 추론 스택은 높은 처리량(Throughput)과 비용 절감 효과를 통해 기업이 생성형 AI 서비스를 효율적으로 운영할 수 있도록 지원합니다. Figure 1: Friendli Container 개념도 Friendli Container Amazon EKS Add-on은 AWS 인프라를 기반으로 AI 추론 효율을 극대화하는 솔루션입니다. 이 Add-on을 활용하면 기존 Amazon EKS 워크플로우에 Friendli […]

LG유플러스, Bedrock AgentCore를 활용한 손쉬운 클라우드 Agent 구현 사례
UCMP 소개 오늘날 대부분의 기업들은 AWS, GCP, Azure 등 다양한 클라우드 환경을 활용해 서비스를 개발하고 있습니다. 하지만 클라우드 사업자마다 계정 구조와 운영 정책이 달라 사용자 입장에서는 환경마다 서로 다른 방식으로 관리해야 하는 불편함이 있습니다. 이러한 문제를 해결하고 일관된 사용자 경험으로 클라우드를 운영할 수 있도록 LG유플러스는 자체 클라우드 관리 플랫폼 UCMP(Uplus Cloud Management Platform)를 구축해 멀티 […]

Amazon SageMaker HyperPod의 오토스케일링 알아보기
이 글은 Artificial Intelligence 블로그에 게시된 글 (Introducing auto scaling on Amazon SageMaker HyperPod)을 한국어로 번역 및 편집하였습니다. 2025년 8월에 Amazon SageMaker HyperPod가 Karpenter를 통한 관리형 노드 오토스케일링 지원하기 시작했습니다. 이를 통해 추론 및 학습 요구 사항에 맞춰 SageMaker HyperPod 클러스터를 효율적으로 확장할 수 있습니다. 실시간 추론 워크로드는 예측 불가능한 트래픽 패턴에 대응하고 서비스 수준 계약(SLA)을 유지하기 […]
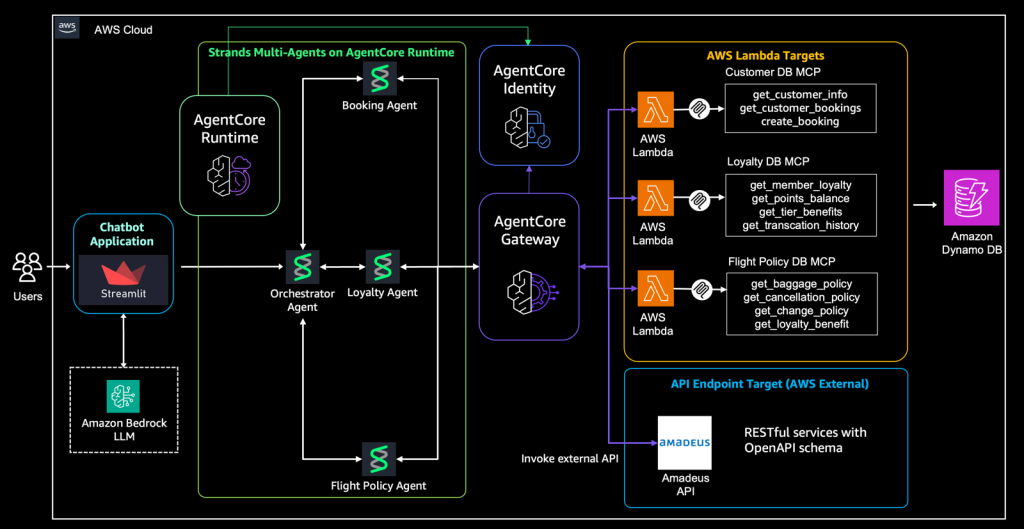
Amazon Bedrock AgentCore를 활용한 멀티에이전트 운영과 접근제어
AI 에이전트를 처음 구축할 때 가장 단순한 접근 방식은 하나의 에이전트가 외부 서비스(API, MCP)를 직접 호출하도록 구성하는 것 입니다. 이러한 구조는 초기 PoC 단계에서는 구현이 간단하고, 빠르게 아이디어를 검증하는 데 효과적입니다. 그러나 에이전트 기반 시스템을 엔터프라이즈 환경으로 확장하기 시작하면, 이러한 접근 방식은 곧 한계에 부딪히게 됩니다. 에이전트의 수가 증가하고 외부 API, MCP 내부 서비스가 지속적으로 […]