AWS 기술 블로그

동원F&B의 Amazon Bedrock AgentCore 기반 AI 쇼핑 어시스턴트로 쇼핑 경험 혁신 여정
동원F&B는 식품 제조를 넘어 건강한 식문화와 라이프스타일 혁신을 선도하며, 대한민국 대표 종합식품기업으로 자리매김하고 있습니다. 축적된 식품 기술력과 디지털 혁신 역량을 바탕으로, 고객의 일상 전반에 새로운 가치를 제공하는 미래형 푸드&라이프 플랫폼 기업으로 도약하고 있습니다. 동원F&B가 운영하는 ‘동원몰’은 동원을 대표하는 식품 전문 이커머스 플랫폼으로, 매일 수많은 고객에게 신선하고 다양한 먹거리를 제공하고 있습니다. 유통·제조업계 전반에 생성형 AI 도입이 […]

Amazon S3 Files, 도입 전 반드시 확인해야 할 3가지 고려사항
소개 2026년 4월 7일 Amazon S3 Files가 정식 출시되면서 “S3 버킷을 파일시스템처럼 다룬다”는 메시지가 빠르게 확산되고 있습니다. 4월 21일에는 AWS Lambda 마운트 지원도 추가되어 Amazon EC2, Amazon Elastic Container Service(ECS) (AWS Fargate / Amazon ECS 관리형 인스턴스), Amazon EKS, AWS Lambda 네 가지 컴퓨팅에서 사용할 수 있습니다. 엔터프라이즈 고객의 도입 검토 과정에서 공식 문서만으로 답하기 […]

Amazon MWAA와 Bedrock AgentCore로 MCP 기반 클라우드 정책 에이전트 구축하기
개요 조직의 클라우드 인프라가 성장하면서 IAM 정책, 보안 그룹, 스토리지 설정, 네트워크 구성 등 수백 개의 정책과 리소스 설정이 여러 계정과 리전에 분산됩니다. DevOps 팀은 인프라 상태를 파악하고, SecOps 팀은 과도한 권한을 찾아내며, Compliance 팀은 규정 준수 여부를 감사하고, FinOps 팀은 리소스 사용 현황을 분석해야 합니다. 그러나 이 모든 팀이 동일한 데이터를 서로 다른 관점에서 […]

에잇퍼센트의 Kiro CLI 기반 Amazon ECS 현대화 여정
이 블로그는 에잇퍼센트와 AWS의 협업으로 작성되었습니다. 현업 운영을 병행하면서 2영업일 만에 레거시 서비스를 Amazon ECS로 전환하고, 월 운영 비용을 약 76% 절감할 수 있을까요? 에잇퍼센트는 AI 코딩 에이전트 Kiro CLI와 오픈소스 AI-Driven Modernization Prompt Sets를 결합해 이를 실현했습니다. 이번 글에서는 에잇퍼센트가 AWS Lift-On 프로그램의 지원을 받아, 소규모 백엔드 팀이 기능 개발과 장애 대응을 병행하면서도 Amazon […]
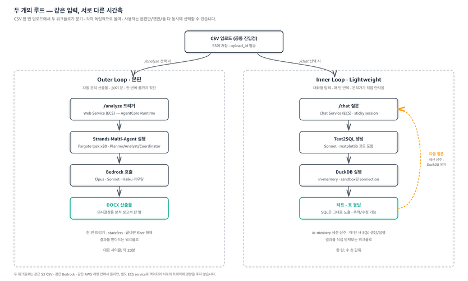
Inner Loop 엔지니어링으로 본 Deep Insight Chatbot – 대화형 분석 챗봇의 4가지 설계 결정
CSV 파일을 LLM에게 전달하고 차트를 생성하는 챗봇은 반나절이면 만듭니다. 하지만 같은 챗봇을 분석가가 매일 쓰게 만들려면 다른 질문에 답해야 합니다. 데이터가 AWS 계정 밖으로 나가지 않도록 어떻게 막을지, group by 하나에 수십 초 이상 걸리지 않게 어떻게 빠르게 답할지, 결과값을 분석가가 못 믿겠으면 어떻게 직접 열어보고 확인하게 할지, 수십 턴짜리 대화의 LLM 비용을 어떻게 줄일지. […]

Amazon Bedrock Vision LLM과 Amazon OpenSearch Service를 활용한 농약 제품 이미지 인식 시스템 구축기
(주)경농 파밍노트 고도화 프로젝트 — 농약 제품 사진 한 장으로 제품 정보를 자동 검색하는 AI 시스템의 설계와 구현 과정을 공유합니다. 경농 소개 ㈜경농은 1957년 설립된 농산업 토털 솔루션 기업으로, 작물보호제∙비료∙종자∙관수자재 등 다양한 농자재를 공급하며 한국 농업 기술 발전을 선도하고 있습니다. 경농 스마트팜사업부문은 복합환경제어기∙양액공급시스템 등 자체 기술과 글로벌 기업과의 협력을 기반으로 국내 최고 수준의 스마트팜 솔루션을 […]

Amazon Bedrock 위에서 Codex와 Claude Code 함께 쓰기: Harness Engineering으로 구현해보기
Codex + Claude Code, 이 조합 가능할까? 2026년 상반기, 터미널에서 도는 AI 코딩 에이전트는 더 이상 신기한 도구가 아니라 매일 쓰는 작업 환경이 되었습니다. 시장은 두 축으로 빠르게 수렴했습니다. 하나는 Anthropic의 Claude Code, 다른 하나는 OpenAI의 Codex입니다. 두 도구는 모두 터미널 CLI를 중심에 두면서 IDE·웹·클라우드·SDK까지 같은 엔진을 공유하고, claude -p와 codex exec 같은 헤드리스 모드로 […]

프롬프트 인젝션 방어: AgentCore 기반 다층 보안 설계 패턴
들어가며 LLM 기반 에이전트를 프로덕션으로 옮기는 순간, 모든 팀이 한 번쯤 마주치는 질문이 있습니다. “에이전트가 다른 사용자의 데이터를 노출하지 않는다는 걸 어떻게 보장할 수 있나요?” 주문 내역, 의료 기록, 사내 문서, 금융 거래 – 도메인이 무엇이든 질문의 본질은 같습니다. 이 문제를 해결하기 위해 많은 팀이 처음에는 시스템 프롬프트로 해결하려고 합니다. 보안 규칙: – 사용자에게 내부 […]

Sim-to-Real과 Real-to-Sim: 유능한 Physical AI를 가능하게 하는 핵심 엔진
이 글은 AWS Blog의 Sim-to-Real and Real-to-Sim: The Engine Behind Capable Physical AI by Dario Macagnano, Ignacio Sánchez, and Quinn Cheong 게시글을 번역한 글 입니다. 서론 Physical AI 시스템, 즉 현실 세계를 인지하고 추론하며 행동하는 로봇은 빠르게 발전하고 있습니다. Sim-to-Real 파이프라인은 이러한 발전의 핵심에 있습니다. 그러나 연구실 밖에서도 안정적으로 작동하는 모델을 만드는 것은 이 분야에서 […]

신한카드, 온톨로지와 소형언어모델로 고효율 AI 챗봇 구축하기
들어가며: 금융 고객 상담의 새로운 패러다임 신한카드는 대한민국 대표 신용카드사로, 수백만 고객에게 종합 금융 서비스를 제공하고 있습니다. 이를 기반으로 보다 진화된 차세대 AI 챗봇을 기획하였고, AWS Generative AI Innovation Center (AWS GenAIIC)와의 협력을 통해 그 토대를 마련하게 되었습니다. 차세대 AI 챗봇이 풀어야 할 문제 금융 고객 상담은 단순한 Q&A가 아닙니다. 고객은 여러 턴에 걸쳐 요청을 […]