AWS 기술 블로그

이커머스 부정 반품 요청, AI로 차단한다: Amazon Nova Fine-tuning으로 산업 특화 가드레일 구성하기
요약: 패션 이커머스에서 급증하는 부정 반품 요청을 사전에 차단하기 위해 Amazon Nova 2 Lite 모델을 미세 조정(Fine-tuning)하여 도메인 특화 Custom Guardrail을 구축한 사례를 소개합니다. Fine-tuning을 통해 부정 의도 탐지 정확도를 73.0%에서 94.6%로 21.6%p 향상시켰으며, 비용 효율적인 소형 모델로도 우수한 성능을 달성했습니다. 서론: 패션 이커머스가 직면한 반품 부정 행위 문제 패션 이커머스 업계는 다른 소매업에 비해 […]

AWS 공간 데이터를 활용한 건물 검사 인텔리전스 구축
이글은 AWS Blog의 “Building Inspection Intelligence with AWS Spatial Data by Michael Prevost, Frantz Lohier, Graeme McHale, Jim Kennedy” 게시글을 번역한 글 입니다. AWS 기반 검사 워크플로를 위한 공간 데이터 관리 실용 가이드 서론 산업 전반에 걸쳐 검사 팀은 자산 상태를 정확하게 문서화하고, 규정 준수 요구사항을 충족하며, 데이터 수집 후 수개월 또는 수년이 지난 후에도 […]

Amazon Braket으로 양자-고전 하이브리드 알고리즘 실행하기 (1편)
고전 컴퓨팅 자원과 양자 컴퓨팅 자원을 결합한 하이브리드 알고리즘은 현재 NISQ (Noisy Intermediate-Scale Quantum) 시대의 양자 컴퓨터 기술 수준에서 실질적인 문제 해결에 접근할 수 있는 효과적인 방법론으로 주목받고 있습니다. 이번 블로그에서는 Amazon Braket을 활용하여 하이브리드 환경을 구성하고 사용할 수 있는 두 가지 방법, 즉 코드 기반 방식과 콘솔 기반 방식을 소개합니다. 이를 통해 독자들은 Amazon […]

AWS와 NVIDIA로 Physical AI 가속화: 시뮬레이션과 실제 학습을 통한 프로덕션 레디 애플리케이션 구축
이 글은 AWS Open Source Blog의 “Accelerating physical AI with AWS and NVIDIA: building production-ready applications with simulation and real-world learning by Srinivas Nidamarthi, Alex Mevec, Ali Shahrokni, Brian Kreitzer, and Raja GT” 게시글을 번역한 글 입니다. 디지털 지능을 넘어 Physical AI를 정의하다 Physical AI는 인공지능의 새로운 진화 방향으로, 순수한 컴퓨팅 시스템을 넘어 물리적 세계를 […]

GloZ의 Amazon OpenSearch Service를 기반으로 한 자연어 이력서 검색 시스템 구축 사례 — Part 2: 하이브리드 검색과 자연어 쿼리 변환
1. Part 1 요약 Part 1: 데이터 파이프라인과 인덱싱에서는 검색 정확도의 기반이 되는 데이터 파이프라인을 다루었습니다. 글로지(GloZ Inc.)는 약 10만 명의 번역가 이력서를 검색 가능한 형태로 구조화하기 위해, 문서 유형별 파싱 → LLM 기반 메타데이터 추출 → 동의어·표기 변형 정규화 → 환각 검증 → 임베딩 입력 전략 최적화로 이어지는 데이터 정제 파이프라인을 구축했습니다. Amazon OpenSearch […]

Amazon EKS에서 NVIDIA OSMO 기반 Physical AI 워크플로 운영하기
Physical AI를 위한 모델 개발 과정은 일반적으로 데이터 수집, 시뮬레이션, 정책 학습, 엣지 배포가 반복되는 긴 라이프사이클을 갖습니다. 또한, 각 단계는 서로 다른 컴퓨팅, 스토리지, 모니터링에 대한 요구사항을 갖습니다. PoC 단계에서는 단일 GPU 인스턴스에서 학습을 실행하는 것만으로도 충분할 수 있지만, 여러 데이터셋과 모델 버전으로 같은 워크플로를 반복 실행하려면 실행 환경, 아티팩트 보존, 관찰 가능성, 보안, […]

AWS Unified Operations: 주요 핵심 워크로드를 위한 복원력 있는 운영 구축
AWS Unified Operations를 통한 대규모 핵심 워크로드의 복원력 확보 – 고가용성, 빠른 마이그레이션, 신속한 인시던트 해결을 위한 AWS 최고 등급 지원 Shift-Left 패러다임: 사후 대응에서 사전 예방으로 주요 핵심 워크로드를 운영하는 조직들은 복원력을 약화시키고, 클라우드 도입을 늦추는 세 가지 중요한 구조적 문제점에 직면해 있습니다. 첫 번째 약점은 역량 부족(Skills gaps)입니다. 클라우드 네이티브 아키텍처 전문 인력은 시장에서 구하기 […]

Amazon GameLift Servers DDoS Protection 기능으로 플레이어 상시 보호
이 글은 AWS for Games Blog에 게시된 Introducing Amazon Gamelift Servers DDOS Protection by Adam Chernick, Dan Green, Liam McCreith, Mark Choi, Michael Morris, and Brian Schuster을 한국어 번역 및 편집하였습니다. 멀티플레이어 게임은 분산 서비스 거부(DDoS) 공격의 가장 주요한 표적 중 하나입니다. e스포츠 대회, 게임 출시 주말, 인기 스트리머의 라이브 방송 등 주목도가 높은 순간을 […]

Amazon SageMaker Unified Studio에서 Cross-Account Amazon Redshift Data Sharing 거버넌스 패턴 검증
도입 배경 소스 컴퓨트를 격리하면서 다른 계정이 Redshift로 쿼리하게 만들 수 있을까요? 한국 대형 리테일 그룹의 데이터 플랫폼 통합 프로젝트에서 맞닥뜨린 질문입니다. 자회사별로 Amazon Redshift와 ML 워크로드가 분리 운영되어 그룹 차원의 통합 분석과 AI/ML 활용에 사일로가 발생하던 환경이었고, SageMaker Unified Studio(이하 SMUS)로 그룹 단위 거버넌스를 통합해야 하지만, 동시에 각 자회사의 데이터 소스 컴퓨트는 다른 자회사 […]
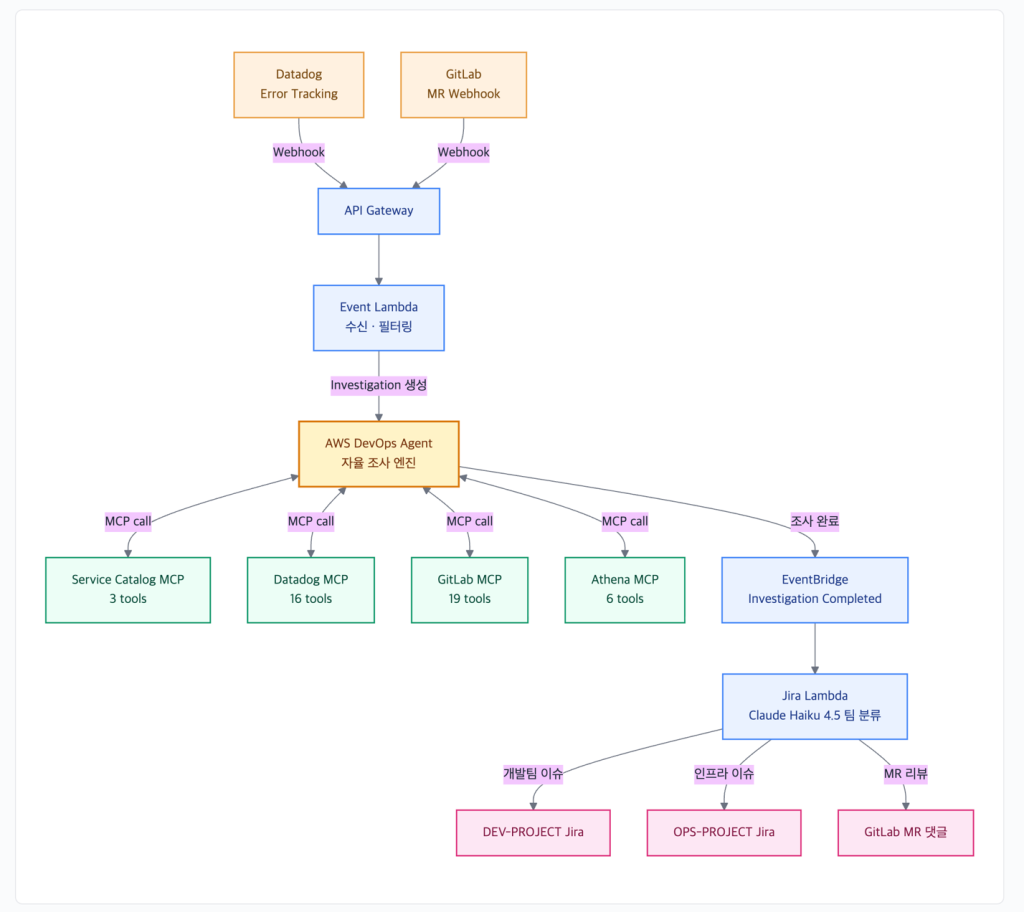
AWS DevOps Agent와 Custom MCP 서버를 활용한 HYBE의 인시던트 자동 조사 체계 구축 사례
1. HYBE 인프라운영팀 소개 하이브(HYBE)는 글로벌 엔터테인먼트 기업으로, 사내 시스템부터 B2C 서비스까지 다양한 워크로드를 AWS 위에서 운영하고 있습니다. 인프라운영팀은 다중 AWS 계정과 EKS 클러스터에 걸쳐 다수의 서비스를 효율적인 인력 구성으로 운영합니다. 모니터링은 Datadog, 소스 코드는 GitLab, 이슈 관리는 Jira를 사용하고 있습니다. 2. 개요 새벽 3시, Slack 알림과 함께 온콜 담당자의 전화가 울립니다. Datadog Error Tracking에서 […]