AWS Partner Network (APN) Blog
How Provectus Built a High-Load Data Quality Pipeline on AWS for Lane Health
By Bogdan Volodarskiy, Data Quality Lead – Provectus
By Aleksei Chumagin, Head of QA – Provectus
By Lenny Blyukher, Chief Technology Officer – Lane Health
 |
| Provectus |
 |
Lane Health is a healthcare lending-as-a-service company that helps employees more easily pay for their medical expenses through the unique Advance line of credit solution, which is issued by WebBank.
Once activated, Advance (issued by WebBank) provides members with swipe-and-go access to a dedicated healthcare line of credit with no credit checks required, giving them greater peace of mind. The ultimate goal of Lane Health is to make healthcare more accessible and affordable to the 60% of Americans who cannot cover an unexpected $1,000 medical expense.
Lane Health was looking to build a robust data platform to help it run a data-driven business, and Provectus participated in this platform’s design, development, and delivery.
Lane Health also wanted to build a separate platform for data analytics to be able to gain business-critical insights from various data sources. It wanted a solution to ensure the quality of data at all levels, to detect and eliminate bad data, reduce the cost of error on the next stage, automate the data processing pipeline, and provide business intelligence (BI) units with clean, accurate dashboards.
Provectus, an AWS Premier Tier Services Partner with the Data and Analytics Competency, has developed a comprehensive data quality assurance (Data QA) solution that it offers customers as a blueprint for assuring data quality. To prepare the solution for integration with Lane Health’s non-homogeneous data platform, the Data QA solution was customized by Provectus.
In this post, we explain how Provectus built a high-load data quality pipeline on Amazon Web Services (AWS) for Lane Health’s data platform, while meeting the requirements for rapid innovation, performance, security, and cost-efficiency.
Solution Overview
Provectus offers a basic data quality solution for new projects. Because the data available at Lane Health was not homogeneous, and the ways to retrieve and read it varied, it was challenging to use the basic data quality solution as-is for designing and building a universal data pipeline that could accommodate high loads.
Provectus takes advantage of AWS serverless services, and the Lane Health project also included appropriate AWS services.
Provectus usually uses the following set of AWS services:
- AWS Step Functions for handling extract, transform, load (ETL) tasks.
- AWS Lambda for running a serverless compute machine.
- Amazon Simple Storage Service (Amazon S3) for storing Data QA configs and reports.
- Amazon DynamoDB for storing metadata.
- Amazon QuickSight for BI and data visualization.
- Amazon Athena for crawling data and connecting the DynamoDB and QuickSight services.
Third-party services:
- Pandas Profiling is an open-source data profiling tool that describes data statistically. Provectus uses the tool to generate test suites by using its rule-based algorithm.
- Great Expectations is an open-source data quality tool used by Provectus as a core engine to run data tests and generate data quality reports.
- Allure is an open-source QA tool for test reporting. It’s widely used in all areas of QA to generate easy-to-use reports, and Provectus uses it as a final test reporting endpoint.

Figure 1 – Basic solution architecture.
Challenges
Here’s how the basic solution works: AWS Step Functions runs with the Map state against all sets of data, meaning the pipeline can be used for each specific data source or table separately. It works with one run per day, per data source, with homogeneous data stored in Amazon S3 as Apache Parquet files.
Originally, Lane Health wanted to transfer its data from PostgreSQL CDC (Change Data Capture is one of the options for extracting record-level change events in real-time) to Amazon S3. Then, after data transformation in Apache Spark, to store it in Apache Hudi.
That plan had several caveats:
- Lane Health would need to run tests for every CDC update. For example, there can be 20+ updates per day per table; there can be from 1-50+ such tables in the system and the tables can be launched up to 100 per day. In total, there can be over 500 pipeline runs per day.
- After completing data transformation, Lane Health would have to repeatedly run tests against the Apache Hudi table.
- It would still be challenging to compare the quality of data sources—there are not any formalized best practices in Data QA yet. The goal was to come up with a unique approach to resolving Lane Health’s challenges.
Let’s have a look at these issues to learn how Provectus resolved them.
PostgreSQL CDC Migration
As part of the CDC migration, Provectus needed to implement a data test for every change. The Data QA solution nearly met those requirements, but some minor customizations were needed.
First, the team needed to edit great_expectations.yml on the fly, to run pipelines as the Map state which is separate for every specific table.
Because any changes in CDC may affect the unique primary key, Provectus needed to filter the source parquet file to identify the latest changes. As data changes over time, the team needed to be able to generate tests on the fly.
Provectus began integration with Data Engineering Airflow dag. As a result, a pipeline like this was received:
- After the updates to CDC are finished, the Airflow dag creates a Payload and triggers the Data QA pipeline.
- AWS Lambda reads the Payload and parses it in a required format, to run a Parallel Map state.
- On Parallel for every table:
- Read Parquet from Amazon S3.
- Change great_expectations config.
- Profile data by Pandas Profiling.
- Generate and save the test suite.
- Run great_expectations test.
- Convert great_expectations reports to Allure results and generate an Allure report.
- Save all reports to Amazon S3.
- Push metadata to Amazon DynamoDB.

Figure 2 – CDC architecture.
Data Transformation on Apache Spark
The Apache Hudi step poses a different problem: all data profiling and data quality services work with the Pandas engine, but Pandas cannot read Apache Hudi as native.
One option is to read the sequences of Apache Hudi Parquet. In doing so, however, the logic of Apache Hudi can be missed. This option will only work for ‘Merge On Read.’ If ‘Copy On Write’ is used, Apache Hudi will have an additional data cache that cannot be read from a simple Parquet file.
It will also create duplicates, and it becomes problematic to know which specific row is needed. In that case, AWS Glue crawlers and Amazon Athena are preferable solutions. They can help create crawl data for a table view and allow us to read necessary tables.
On top of that, while tests do not need to be generated, they have to be run along with the tests on the CDC step.

Figure 3 – Apache Hudi architecture.
The Apache Hudi step of the pipeline does not differ much from the CDC step. The only difference is that data is read from Amazon Athena to get a completed test.
Comparison and Visualization
The last challenge was to find a solution to demonstrate the comparison of data between the CDC migration and Apache Hudi parts.
There is no need to compare every row of datasets, every schema, and the size of every data frame, because tests and results are already available. Tests just need to be run in CDC and Apache Hudi. All data quality metrics should remain the same.
Bug trends per date and run_name on the Amazon QuickSight dashboard can be easily visualized. If any deviations are found or a considerable percentage of failed tests is detected, it’s possible to go through the test reports and find out why that happened.
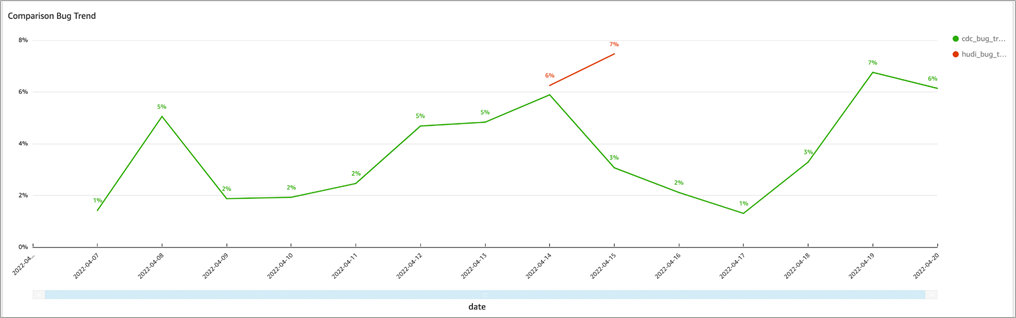
Figure 4 – Bug trends per date.
The bug trends for all data sources are visualized by group and by pipeline name to make it easy to evaluate the quality of every data pipeline step.
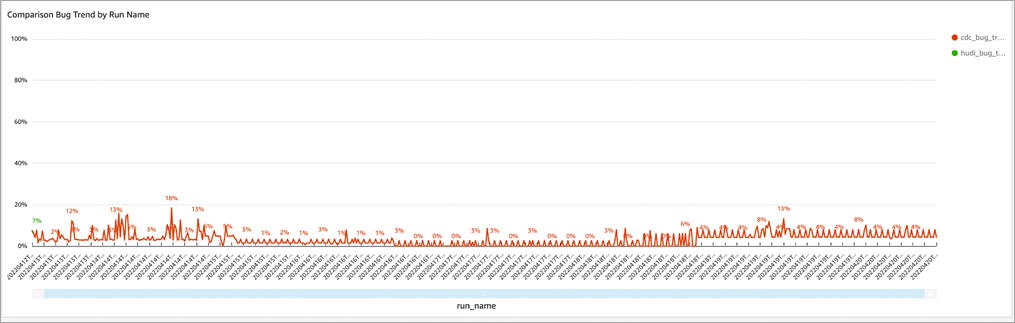
Figure 5 – Bug trends per pipeline run.
The pivot table with test runs metadata is displayed when there’s a need to look into every report by selecting the raw data.
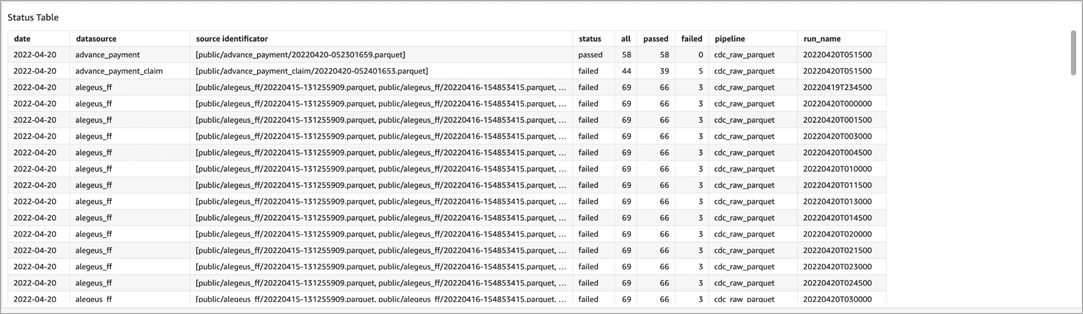
Figure 6 – Pivot table with short run description.
The run trends demonstrates how many test runs per day and per pipeline should be completed to get a clear picture about the increasing or decreasing volumes of data.
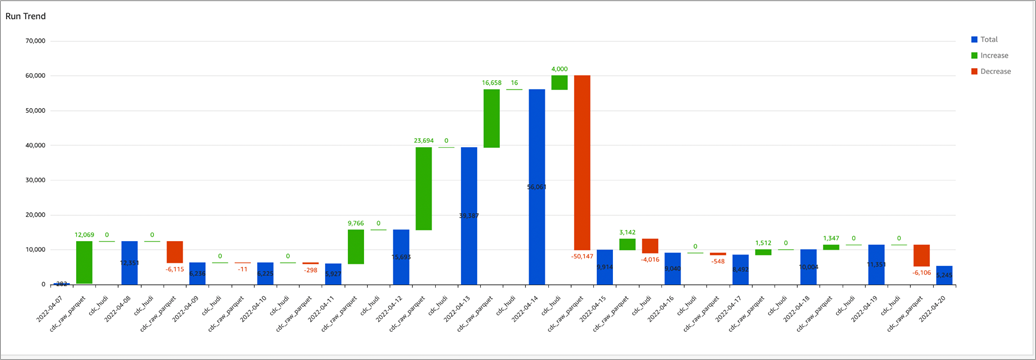
Figure 7 – Run trends for comparison.
Conclusion
In close cooperation with the Lane Health team, Provectus implemented a high-load data quality pipeline that was able to support 500 pipeline runs for 52 tables daily. The pipeline accommodated two data sources in two stages: development and production.
Lane Health gained the ability to track if and when its data deteriorated during transformation and understand the quality of data, and to explore and detect weak spots in data.
By implementing data quality gates, Lane Health increased awareness about bad data and reduced the cost of error on next stages. These improvements were critical for Lane Health because raw data from the data lake was used in data transformations and analytics work, to create and display business-critical dashboards.
The company is now ready to move forward toward its goal of helping make healthcare more accessible and affordable for everyone—even the ones who cannot afford to contribute and save.
To learn more about the Provectus data quality assurance practice, visit the webpage and watch the webinar for more practical advice.
If you are interested in implementing a Data QA solution for your organization, apply for the Serverless Data Lake Acceleration Program to start building a data lake solution with Data QA and data analytics components.
The content and opinions in this blog are those of the third-party author and AWS is not responsible for the content or accuracy of this post.
.

.
Provectus – AWS Partner Spotlight
Provectus is an AWS Data and Analytics Competency Partner and AI-first transformation consultancy and solutions provider helping design, architect, migrate, or build cloud-native applications on AWS.