Bagaimana konten ini?
- Pelajari
- CelerisTx: Penemuan obat untuk penyakit yang tidak dapat disembuhkan dengan ML di AWS
CelerisTx: Penemuan obat untuk penyakit yang tidak dapat disembuhkan dengan ML di AWS
Memanfaatkan penemuan obat secara komputasional pada senyawa penginduksi kedekatan (PIC)
Umat manusia terus mengalami kemajuan dengan solusi terapeutik yang tak terhitung jumlahnya untuk mengobati penyakit. Teknologi terbaru seperti knockout (CRISPR yang bekerja pada tingkat DNA) dan knockdown (RNAi yang bekerja pada tingkat RNA) memiliki keterbatasan yang signifikan. Sebaliknya, Senyawa Penginduksi Kedekatan (PIC) menggabungkan keunggulan unik dari molekul kecil. Fitur yang bermanfaat tersebut termasuk bioavailabilitas oral dan kemudahan pembuatan, bersama dengan teknologi peredam, seperti CRISPR dan RNAi. Berbeda dengan RNAi dan CRISPR, PIC memengaruhi protein sehingga memberikan modalitas terapeutik terobosan untuk menargetkan protein, khususnya yang terkait dengan penyakit. Alternatif yang menargetkan protein meliputi biologis dan inhibitor, dan alternatif ini belum memperluas jangkauan protein patogen yang dapat ditargetkan. Lebih dari 80% protein patogen dikaitkan dengan penyakit yang belum dapat ditangani dengan intervensi farmasi.
Degradasi protein bertarget (TPD) adalah modalitas obat penginduksi kedekatan yang paling populer, pertama kali ditunjukkan pada awal tahun 2000-an. TPD juga menerima Hadiah Nobel Bidang Kimia karena menemukan degradasi protein yang dimediasi ubiquitin pada tahun 2004. Konsep TPD melibatkan degradasi protein selektif dengan membajak mesin seluler internal dalam tubuh manusia. Dibandingkan dengan metode berbasis hunian seperti inhibitor, mekanisme TPD memiliki keuntungan menghilangkan fungsi perancah, sehingga mengatasi akar penyebab masalah daripada hanya mengobati gejala. Secara umum, alat untuk mengeliminasi protein yang salah lipatan dan terdenaturasi di dalam sel diperlukan untuk mempertahankan homeostasis biologis.
Sementara berbagai mesin dapat digunakan secara aktif melalui PIC, seperti lisosom dan autophagy, Celeris Therapeutics berfokus pada sistem ubiquitin-proteasome. Berdasarkan sistem ini, protein yang tidak diinginkan ditandai dengan ubiquitin, yaitu protein pemberi sinyal kecil. Akibatnya, proses ini memulai degradasi protein patogen.
Namun, penilaian untuk TPD dalam pengaturan laboratorium eksperimental berjalan lambat dan mahal. Oleh karena itu, Celeris Therapeutics menerapkan alur kerja komputasi untuk memprediksi degradasi protein secara efektif sehingga mempersingkat dan merampingkan jadwal pengembangan obat.
Senyawa penginduksi kedekatan
Celeris Therapeutics (CelerisTx) memelopori adopsi AI pada PIC, dengan fokus pada Degradasi Protein Bertarget. Dalam hal data, dalam degradasi protein, hal itu menandakan pengidentifikasian beberapa molekul yang saling berinteraksi dengan cara tertentu. Bayangkan batu bata LEGO®. Alih-alih menyatukannya hanya berdasarkan satu dimensi yaitu, bentuk, elemen-elemen ini memiliki beberapa dimensi atau persyaratan untuk dipenuhi. Beberapa bersifat kimia, biologis, didorong oleh fisik, dll., artinya, interaksi tersebut tunduk pada hukum tertentu. Hukum-hukum ini perlu dikuantifikasi dan disematkan dalam data. Contoh konkret dari informasi tersebut meliputi struktur 3D molekul yang direpresentasikan sebagai grafik, hidrofobisitas, atau potensial elektrostatik. Secara keseluruhan, ini berjumlah sekitar 20 fitur berbeda yang dikuratori oleh para ahli TPD. Akibatnya, sejumlah besar data dihasilkan yang perlu dianalisis menggunakan algoritma machine learning dan, khususnya, jalur deep learning geometris. Aplikasi ML yang konkret diperlukan untuk menentukan tingkat interaksi antara molekul yang terlibat dalam apa yang disebut kompleks terner. Dengan kata lain, dengan mempertimbangkan dua protein, kami mengharapkan nilai skalar yang menentukan tingkat interaksi. Selain akurat dan dapat digeneralisasi, kami harus membuat prediksi cepat dalam sistem yang beperforma. Saat kami menyimulasikan interaksi protein yang berbeda, prediksi yang tidak akurat perlu segera dibuang untuk mengurai ruang dengan segera. Hal ini telah terbukti menjadi tantangan bagi set data interaksi dengan lebih dari 20.000 pasangan protein.
Bagaimana AWS dimanfaatkan untuk berbagai proyek penemuan PIC
Untuk menghemat waktu developer dan mendapatkan wawasan yang lebih cepat mengenai masalah khusus seputar pengembangan machine learning, kami beralih ke Amazon SageMaker. Kemampuannya memungkinkan kami untuk menghindari penerapan beberapa solusi infrastruktur machine learning secara mandiri, seperti deteksi bias atau penyetelan hiperparameter. Deteksi bias relevan selama persiapan data; karenanya, kami memanfaatkan SageMaker Clarify. Hal ini berperan penting dalam memastikan kualitas data kami, bahkan sebelum memulai pemodelan. Setelah itu, begitu kami memulai pemodelan, penting untuk memiliki integrasi langsung dari pustaka deep learning geometris, seperti Deep Graph Library (DGL) SageMaker. Karena DGL adalah paket python sumber terbuka untuk deep learning pada grafik, kami menggunakannya untuk mendapatkan pengaturan cepat infrastruktur yang diperlukan untuk deep learning geometris, yang sangat penting.
Setelah model awal ditetapkan, untuk menemukan hiperparameter terbaik dengan cepat, kami menggunakan Penyetelan Model Otomatis SageMaker. Kami memperkirakan bahwa dengan demikian kami menghindari waktu pengembangan selama berbulan-bulan dalam mengodekan kerangka kerja optimisasi hiperparameter. Kami memanfaatkan SageMaker Experiments untuk melacak dan mengatur semua perubahan pada eksperimen. Solusi ini sangat penting. Pertimbangkan masalah yang disebutkan di atas dalam menentukan kekuatan interaksi antara protein yang terlibat dalam kompleks terner, lebih dari 15 arsitektur deep learning geometris yang telah kami uji coba dengan dari lapisan perhatian, operator konvolusi murni pada grafik, dll. Kemampuan lacak model yang berbeda dan parameternya masing-masing penting untuk menentukan apa yang pada akhirnya akan berhasil. Setelah kami membuat versi final model, kami perlu melakukan debug dan mengoptimalkan alur lebih lanjut. Untuk hal ini, SageMaker Debugger terbukti membantu.
Seiring dengan solusi perangkat lunak dari SageMaker, kami membutuhkan daya komputasi yang sangat besar untuk data kami yang luas dan alur deep learning. Oleh karena itu, kami membangun solusi Armada Spot yang dioptimalkan untuk GPU yang digunakan dalam melatih alur kerja machine learning kami.
Mengoptimalkan biaya alur ML kami
Instans Spot adalah jenis khusus dari instans Amazon EC2 yang memberikan diskon 90% dibandingkan dengan harga Sesuai Permintaan. Terkadang, karena tingginya permintaan untuk sumber daya komputasi, sumber daya komputasi dapat terganggu, yang menyebabkan pengguna kehilangan seluruh sesi komputasi. Sangatlah penting untuk menyimpan hasil perantara komputasi, jika seseorang melatih model deep learning untuk waktu yang lama, atau jika beberapa komputasi yang berjalan lama dijalankan pada Instans Spot. Selain menyimpan hasil perantara komputasi, pengguna juga harus dapat secara otomatis melanjutkan perhitungan pada Instans Spot lain dari langkah perantara yang sama di mana pemutusan terjadi.
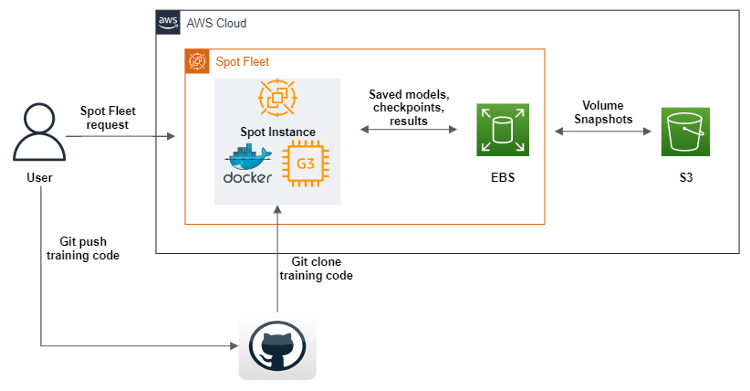
AWS SDK for Python (boto3) digunakan untuk membuat skrip yang akan, setelah eksekusi, mengirim permintaan Armada Spot untuk membuat Instans Spot GPU dengan Amazon Machine Images (AMI), yang berisi semua perangkat lunak dan dependensi untuk mengeksekusi kode machine learning kami. Selanjutnya, kami mendefinisikan skrip data pengguna yang mengunduh citra docker dari Amazon Elastic Container Registery (Amazon ECR), lalu Git mengkloning kode dari repositori kami. Akhirnya, skrip data pengguna mengeksekusi kode alur deep learning geometris. Kode ini telah diubah sedemikian rupa sehingga setelah setiap periode pelatihan machine learning, kode tersebut mengirimkan set data, log, model, dan pos pemeriksaan ke volume Amazon EBS. Untuk memastikan bahwa objek disimpan, kami membuang semuanya ke Amazon S3. Selain menentukan Armada Spot, kami juga mengaktifkan pengisian Instans Spot yang terputus dalam proses, yang memungkinkan kami untuk melanjutkan pelatihan secara otomatis dari pos pemeriksaan terakhir yang ditemukan di bucket S3.
SageMaker menawarkan sesuatu yang sangat mirip, yang disebut Pelatihan Spot Terkelola. Namun, kami tidak memanfaatkan penawaran SageMaker karena ketika digunakan sebagai bagian dari SageMaker, instans EC2 lebih mahal daripada yang standar. Hal ini masuk akal karena SageMaker menyediakan banyak penawaran ML, kemudahan penggunaan, waktu rekayasa yang lebih sedikit, dll. Bagi kami, merancang solusi ini adalah investasi waktu yang strategis karena kami tahu kami akan menggunakan GPU dalam kapasitas yang berbeda selama beberapa tahun.
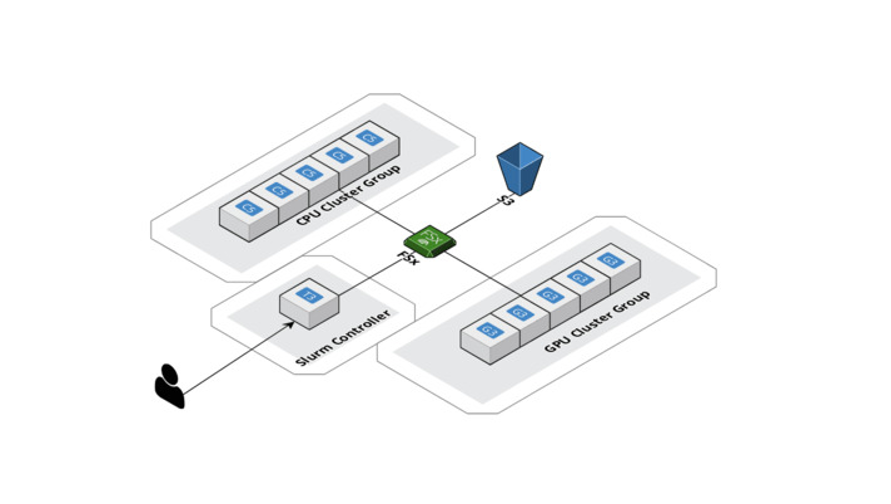
HPC adalah kasus penggunaan penting lainnya yang perlu kami penuhi dengan AWS. Ruang data yang sangat besar perlu diuraikan dengan deep learning geometris hadir dengan beban komputasi yang substansif. Kami meningkatkan perhitungan secara horizontal dengan AWS ParallelCluster dan membuat sistem file bersama, Amazon FSx for Lustre sehingga semua simpul komputasi dapat mengakses dan mengubah data dari tempat yang sama. Selain itu, AWS mendukung Slurm sebagai manajer beban kerja, yang memungkinkan kami mendistribusikan pekerjaan di seluruh CPU dan GPU secara bersamaan. Hal ini pada akhirnya memungkinkan tidak hanya eksperimen yang lebih cepat tetapi juga penyajian model yang dioptimalkan. Sekali lagi, perlu diperhatikan bahwa SageMaker menawarkan layanan serupa untuk set data dan model besar, yang disebut Pustaka Pelatihan Terdistribusi.
Masa depan senyawa penginduksi kedekatan
Hasil awal dari jalur kami tersedia untuk penyakit Parkinson yang berkembang menjadi studi praklinis. Bereksperimen dengan cepat dan andal sangat penting untuk penemuan obat secara komputasional karena kami terus meningkatkan jalur penemuan obat dengan arsitektur dan pendekatan baru. Pendekatan R&D kami, di mana kami menginvestasikan sumber daya yang besar dalam penelitian, menandakan bahwa kami menghadapi banyak risiko berkelanjutan yang perlu dimitigasi. Penawaran standar AWS adalah salah satu cara untuk memastikan bahwa kami tangkas dan bergerak lebih cepat dari penelitian ke laboratorium lalu ke pasar.
Kesimpulan
Sekarang saatnya untuk meningkatkan produktivitas dalam penemuan obat. Kebalikan dari Hukum Moore dalam farmakologi, yang dikenal sebagai “Hukum Eroom,” menunjukkan bahwa biaya penelitian dan pengembangan yang diperlukan untuk mengembangkan obat baru hanya akan terus meningkat. Pendekatan untuk mengatasi hal ini adalah dengan memanfaatkan dan merampingkan proses pelaksanaan eksperimen machine learning berkelanjutan untuk penemuan obat.

Christopher Trummer
Christopher Trummer adalah Co-Founder Celeris Therapeutics dan menjabat sebagai CEO. Dia telah beberapa kali menjadi pembicara utama yang diundang di AI untuk konferensi penemuan obat dan merupakan rekan penulis publikasi peer-review di berbagai jurnal.

Noah Weber
Noah Weber menjabat sebagai Chief Technology Officer di Celeris Therapeutics. Dia adalah Grandmaster Kaggle dan dosen tidak tetap di Vienna University of Technology dan Vienna University of Applied Sciences.

Olajide Enigbokan
Olajide Enigbokan adalah Startups Solutions Architect di Amazon Web Services. Dia suka bekerja dengan Startups (terutama builder) untuk menemukan nilai AWS Cloud.

AWS Editorial Team
Tim Pemasaran Konten AWS Startupss bekerja sama dengan Startups dari semua ukuran dan di semua sektor untuk memberikan konten luar biasa yang mendidik, menghibur, dan menginspirasi.
Bagaimana konten ini?