このコンテンツはいかがでしたか?
- 学ぶ
- CelerisTx: AWS での機械学習による難病の創薬
CelerisTx: AWS での機械学習による難病の創薬
近接誘導化合物 (PIC) の計算による創薬の活用
人類は、病気を治療するための数え切れないほどの治療ソリューションを発展させてきました。Knockout (CRISPR - DNA レベルで機能する) や Knockdown (RNAi - RNA レベルで機能する) などの最近の技術には大きな限界があります。これとは対照的に、近接誘導化合物 (PIC) は、小分子特有の利点を兼ね備えています。このような有益な特徴には、CRISPR や RNAi などのサイレンシング技術に加えて、経口バイオアベイラビリティや製造のしやすさなどがあります。RNAi や CRISPR とは対照的に、PIC はタンパク質に作用するため、特に疾患に関連するタンパク質を標的とする画期的な治療法となります。タンパク質を標的とする代替薬として生物製剤や阻害剤が挙げられますが、これらの代替薬では標的とできる病原性タンパク質の範囲は拡大していません。病原性タンパク質の 80% 以上が、まだ薬剤による治療を受けられない疾患に関連しています。
標的タンパク質分解(TPD) は、2000 年代初めに初めて実証された、最も一般的な近接誘導型薬物モダリティです。また、2004 年にユビキチンを介したタンパク質分解を発見したことでノーベル化学賞を受賞しました。TPD の概念は、人体内の細胞機構を乗っ取ることによってタンパク質を選択的に分解するというものです。阻害剤のような占有主導型の方法と比べ、TPD 機構は足場機能を排除するため、症状を治療するだけでなく問題の根本原因に対処できるという利点があります。一般に、生物学的恒常性を維持するには、細胞内でミスフォールディングや変性したりしたタンパク質を除去するツールが必要です。
リソソームやオートファジーなど、PIC を介してさまざまな機械を積極的に利用できますが、Celeris Therapeutics ではユビキチン - プロテアソームシステムに重点を置いています。このシステムに基づいて、不要なタンパク質には小さなシグナル伝達タンパク質であるユビキチンというタグが付けられます。その結果、この過程で病原性タンパク質の分解が始まります。
ただし、実験室での TPD の評価には時間がかかり、費用もかかります。そこで Celeris Therapeutics は、タンパク質分解を効果的に予測する計算ワークフローを導入して、医薬品開発のスケジュールを短縮し、効率化しました。
近接誘導化合物
Celeris Therapeutics (CelerisTx) は、標的タンパク質分解に焦点を当てて、PIC に AI を採用するパイオニア企業です。データの観点から言うと、タンパク質分解とは、特定の方法で互いに相互作用する複数の分子を特定することを意味します。LEGO® のブロックを想像してみてください。1 つの寸法、つまり形状だけで組み合わせるのではなく、これらの要素には複数の寸法や要件を満たす必要があります。その中には、化学的なもの、生物学的なもの、物理的なものなど、相互作用には特定の法則があります。これらの法則を定量化してデータに組み込む必要があります。このような情報の具体例としては、グラフで表される分子の立体構造、疎水性、静電ポテンシャルなどがあります。これらを合わせると、TPD 専門家がキュレーションする機能はおよそ 20 種類あります。その結果、機械学習アルゴリズム、特に幾何学的深層学習パイプラインを使用して分析する必要がある膨大な量のデータが生成されています。いわゆる三元複合体に含まれる分子間の相互作用の度合いを調べるには、具体的な機械学習アプリケーションが必要です。つまり、2 つのタンパク質を考慮して、相互作用の度合いを決定するスカラー値を得る必要があるという事です。正確で一般化できるだけでなく、高性能なシステムで迅速に予測を行う必要があります。さまざまなタンパク質間相互作用をシミュレートする中で、その空間を迅速に解析するには、不正確な予測を迅速に破棄する必要があります。これは 20,000 組以上のタンパク質ペアを含む相互作用データセットに対する挑戦であることが明らかになっています。
さまざまな PIC 発見プロジェクトで AWS がどのように活用されたか
デベロッパーの時間を節約し、機械学習開発を取り巻く特定の問題をより迅速に把握するために、私たちは Amazon SageMaker を利用しました。その機能により、バイアス検出やハイパーパラメータ調整などの機械学習インフラストラクチャソリューションを自社で実装する必要がなくなりました。データ準備時にはバイアス検出が重要だったため、SageMaker Clarify を利用しました。これは、モデリングを開始する前から、データの品質を確保するうえで非常に役立ちました。その後、モデリングを開始した後は、SageMaker Deep Graph Library (DGL) などの幾何学的深層学習ライブラリを直接統合することが重要でした。DGL はグラフの深層学習用のオープンソースの Python パッケージなので、幾何学的深層学習に必要不可欠なインフラストラクチャーを quick setup するためにこれを利用しました。
初期モデルを設定した後は、最適なハイパーパラメータを素早く見つけるため、SageMaker 自動モデルチューニングを使用しました。これにより、ハイパーパラメータ最適化フレームワークのコーディングに何ヶ月もかかる開発時間を省いたと推定しています。SageMaker Experiments を活用して、実験に加えられたすべての変更を追跡し、整理しました。このソリューションは特に重要でした。前述の三元複合体に含まれるタンパク質間の相互作用の強さ、注意層から実験してきた 15 種類以上の幾何学的深層学習アーキテクチャ、グラフ上の純粋な畳み込み演算子などを考えてみてください。最終的に何が機能するかを決定するには、さまざまなモデルとそれぞれのパラメーターの追跡可能性が重要でした。モデルの最終バージョンを作成したら、それらをデバッグしてパイプラインをさらに最適化する必要がありました。それを行うのに、SageMaker Debugger が有用であることがわかりました。
SageMaker のソフトウェアソリューションに加えて、膨大なデータと深層学習のパイプラインにはかなりの計算能力が必要でした。そこで、機械学習ワークフローのトレーニングに使用する GPU 向けに最適化されたスポットフリートソリューションを構築しました。
ML パイプラインのコストの最適化
スポットインスタンスは特別な Amazon EC2 インスタンスで、オンデマンド料金と比較して 90% の割引が適用されます。コンピューティングリソースの需要が高いために、コンピューティングリソースが中断され、ユーザーがコンピューティングセッション全体を失うことがあります。深層学習モデルを長期間トレーニングする場合や、必然的に長時間かかる計算がスポットインスタンスで実行された場合は、計算の中間結果を保存することが重要です。計算の中間結果を保存する以外に、ユーザーは切断が発生したのと同じ中間ステップから別のスポットインスタンスで自動的に計算を続行できる必要もあります。
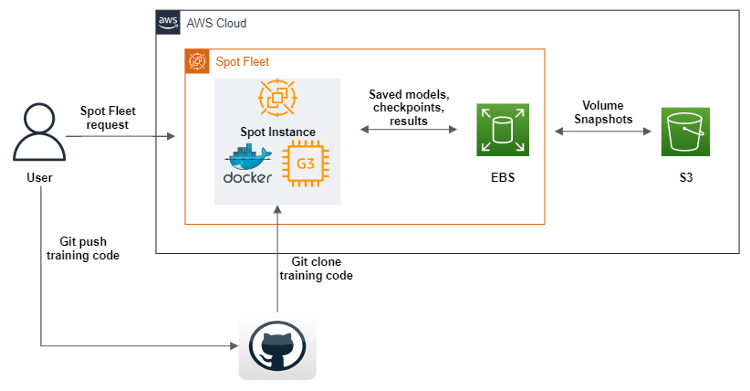
AWS SDK for Python (boto3) を使用して、実行時にスポットフリートリクエストを送信し Amazon マシンイメージ (AMI) を含む GPU スポットインスタンスを作成するスクリプトを作成しました。このインスタンスには、機械学習コードを実行するためのすべてのソフトウェアと依存関係が含まれています。さらに、Amazon Elastic Container Registery (Amazon ECR) から Docker イメージをダウンロードするユーザーデータスクリプトを定義し、Git がリポジトリからそのコードを複製します。最後に、ユーザーデータスクリプトは幾何学的深層学習のパイプラインコードを実行します。このコードは、機械学習トレーニングの各エポック終了後に、データセット、ログ、モデル、チェックポイントを Amazon EBS ボリュームに送信するように変更されています。オブジェクトが確実に保存されるように、すべてを Amazon S3 にダンプします。スポットフリートの定義とは別に、処理中に切断されたスポットインスタンスを補充できるようにしました。これにより、S3 バケットで見つかった最後のチェックポイントから自動的にトレーニングを続けることができます。
SageMaker では、マネージドスポットトレーニングという非常に類似したものを提供しています。しかし、SageMaker の一部として使用する場合、EC2 インスタンスは標準のインスタンスよりも高価になるため、SageMaker 製品を活用しませんでした。しかし SageMaker は多くの ML を提供しており、使いやすく、必要なエンジニアリングにかかる時間の短縮が可能になるためこれは納得のいくことです。当社にとって、このソリューション設計は戦略的な時間投資でした。というのも、異なる容量の GPU を何年にもわたって使用することがわかっていたからです。
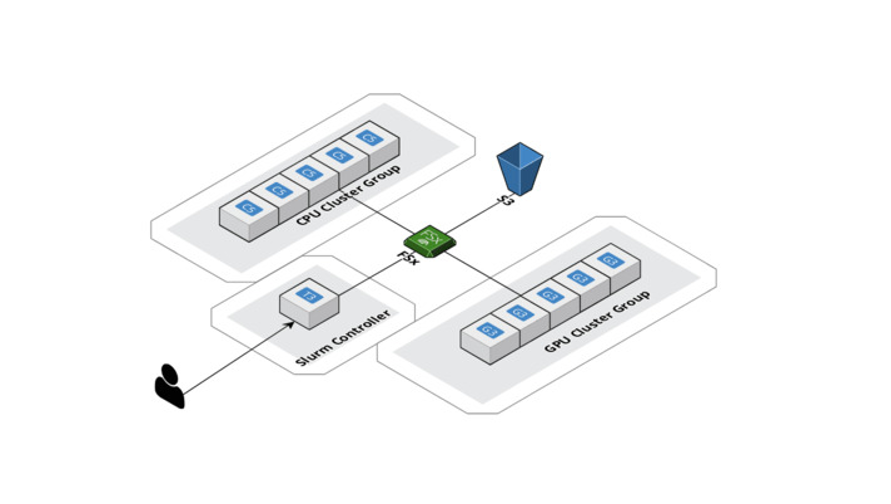
HPC は、AWS で実現する必要があったもうひとつの重要なユースケースでした。幾何学的な深層学習で解析する必要がある膨大なデータスペースには、かなりの計算負荷が伴います。AWS ParallelCluster を使用して計算を水平方向にスケールアップし、Amazon FSx for Lustre という共有ファイルシステムを構築しました。これにより、すべてのコンピューティングノードが同じ場所からデータにアクセスして変更できるようになります。また、AWS はワークロードマネージャーとして Slurm をサポートしているため、CPU と GPU に同時に作業を分散できます。これにより、最終的には実験を迅速に行えるだけでなく、モデル提供の最適化も可能になります。これにいても SageMaker は、大規模なデータセットやモデル向けに、分散トレーニングライブラリと呼ばれる同様のサービスを提供しています。
近接誘導化合物の未来
私たちのパイプラインから、前臨床試験に進んでいるパーキンソン病に関する予備的な結果が得られています。新しいアーキテクチャーとアプローチで創薬パイプラインを改善し続けるためには、計算創薬には迅速かつ確実な実験が不可欠です。研究に多大なリソースを投資する当社の研究開発アプローチは、軽減が必要な多くの継続的なリスクに直面していることを意味します。AWS の標準サービスは、私たちが俊敏に行動し、研究から研究室、さらには市場へと迅速に移行できるようにするためのひとつの手段です。
まとめ
今こそ、創薬における生産性を高める時です。薬理学におけるムーア (Moore) の法則の Moore を逆にした「イールーム (Eroom) の法則」は、新薬開発に必要な研究開発コストが今後も上昇の一途を辿ることを示しています。これに対処するためのアプローチとは、創薬のための持続的な機械学習実験のプロセスを活用し、合理化することなのです。

Christopher Trummer
Christopher Trummer 氏は Celeris Therapeutics の共同創業者であり、CEO を務めています。創薬カンファレンス向けの AI に関する招待制の基調講演における講演者を複数回務めており、さまざまなジャーナルにおける査読済みの出版物の共著者でもあります。

Noah Weber
Noah Weber 氏は Celeris Therapeutics の Chief Technology Officer を務めています。Kaggle Grandmaster であり、Vienna University of Technology および Vienna University of Applied Sciences の非常勤講師でもあります。

Olajide Enigbokan
Olajide Enigbokan は Amazon Web Services の Startup Solutions Architect です。スタートアップ (特にビルダー) と連携して AWS クラウドの価値を発見することに喜びを感じています。

AWS Editorial Team
AWS スタートアップの Content Marketing Team は、教育、エンターテインメント、インスピレーションを提供する優れたコンテンツをもたらすために、あらゆる規模およびあらゆるセクターのスタートアップと連携しています。
このコンテンツはいかがでしたか?