Wie war dieser Inhalt?
- Lernen
- Die Serie Evolutionäre Architekturen: Teil 4
Die Serie Evolutionäre Architekturen: Teil 4
„Möchten Sie einen Kaffee dazu?“
„Evolutionäre Architekturen“ ist eine vierteilige Blogreihe, die zeigt, wie sich Lösungskonzepte und Entscheidungen entwickeln, wenn Unternehmen die verschiedenen Phasen des Lebenszyklus von Startups durchlaufen. In dieser Reihe folgen wir dem treffend benannten Beispiel Startup, dessen Idee es ist, eine Anwendung für den „Fantasie-Aktienmarkt“ zu entwickeln, ähnlich wie bei Fantasie-Sportligen. Sie planen, im Laufe eines Jahres vier „Turniere“ zu veranstalten.
Im dritten Blog-Beitrag wurde beschrieben, wie das Startup damit begann, seine Architektur weiterzuentwickeln, sodass Tools wie CI/CD-Pipelines und Infrastructure-as-Code sowie bewährte Methoden, insbesondere in Bezug auf Sicherheit und Autorisierung, implementiert wurden. In Teil 4 sehen wir, wie das Beispiel-Startup seinen Sicherheits- und Backup-Status formalisiert, um verschiedene Compliance-Standards zu erfüllen. Außerdem legen sie eine Datenstrategie für das Unternehmen fest und erkunden zusätzliche Geschäftsbereiche, um ihr Produktportfolio zu diversifizieren.

Nutzen der Finanzieren der Serie B zur Einstellung, Erweiterung und Skalierung
Für das Beispiel-Startup laufen die Dinge derzeit so gut wie möglich. Sie haben kürzlich eine Finanzierungsrunde der Serie B abgeschlossen, von der sie erwarten, dass sie die dringend benötigten Einstellungen, Erweiterungen und Skalierungen ankurbeln wird. Mit der Finanzierung und der Kundenakzeptanz hat auch der Wettbewerb zugenommen. Etablierte Unternehmen in diesem Bereich beginnen, sie als ernsthafte Konkurrenten zu betrachten, und verstärken ihre Marketingbemühungen.
Das Beispiel Startup beginnt mit der Einstellung von Mitarbeitern, um die Funktionsbereiche zu erweitern und dedizierte Teams für Site Reliability Engineering (SRE), Plattform, Analytik und Datenwissenschaft zusammenzustellen. Angesichts des hart umkämpften Arbeitsmarktes und des Fehlens einer eigenen Personalabteilung wenden sie sich erneut an ihr AWS-Account-Team, um nach technischen Talenten zu fragen, die sich mit AWS auskennen. Es stellt sich heraus, dass das Account-Team bereits anderen Startup-Kunden in ähnlichen Situationen geholfen hat, indem es AWS-Partner vorgeschlagen hat, die sie bei ihren Einstellungsbedürfnissen unterstützen können. Schon bald hat das Startup E-Mails von mehreren geprüften Kandidaten mit AWS-Erfahrung in seinem Posteingang. Glücklicherweise führen viele Vorstellungsgespräche zu Stellenangeboten und das Startup kann die Einstellung von Mitarbeitern von seiner To-Do-Liste streichen.
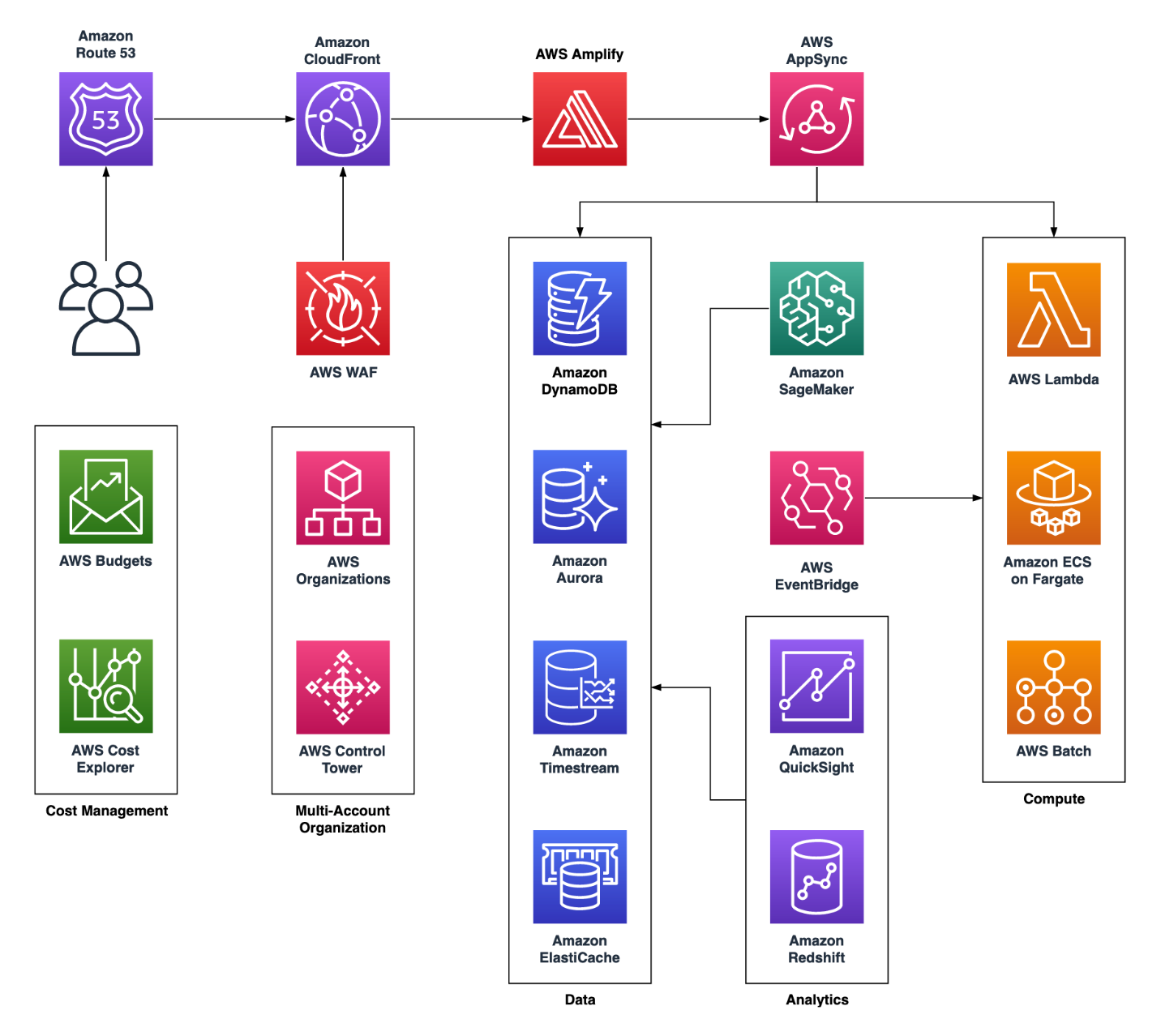
Die Einstellungswelle führt zu einem technischen Problem: Die Teams beschweren sich, dass das Plattformteam des Beispiel Startups zu lange braucht, um neue Konten zu Testzwecken einzurichten, was die Innovation hemmt. Das Plattformteam erklärt, dass es nicht über die nötige Bandbreite verfügt, um jedes Mal, wenn jemand eine neue Idee für eine Funktion hat, individuelle Konten zu erstellen. An diesem Punkt ihrer AWS-Reise hat das Plattformteam ein zweiwöchentliches Treffen mit ihrem AWS-Kontoteam, bei dem sie ihr Dilemma zur Diskussion stellen können. Der AWS-Lösungsarchitekt (SA) empfiehlt die Einrichtung einer dedizierten Sandbox-Organisationseinheit (OU) innerhalb ihrer AWS-Organisation, um schnell temporäre Ressourcen und Umgebungen für andere Teams bereitzustellen, die neue AWS-Services und -Funktionen testen möchten. Um die Kosten im Griff zu behalten, empfiehlt der SA außerdem den Einsatz von Automatisierung, um Ressourcen wie <t2>Amazon-EC2</t2>-Instances außerhalb der normalen Geschäftszeiten automatisch anzuhalten. Das Plattformteam des Beispiel-Startups befolgt den Rat des SA. Dadurch sind sie in der Lage, schnell und kostenkontrolliert Konten für die verschiedenen Teams des Startups einzurichten.
Im Anschluss daran stellt das neu eingestellte SRE-Team fest, dass das Startup in Bezug auf Verfügbarkeit und Notfallwiederherstellung (DR) besser aufgestellt sein kann. Sie erkennen, dass das Startup schnell wächst und mit dem Beginn der Ausrichtung auf größere Kunden mit strengeren Sicherheitsanforderungen wie Audits und Compliance-Prüfungen konfrontiert sein wird. Dadurch mussten einige infrastrukturelle Änderungen vorgenommen werden. Zum Glück wurde ein Großteil der Arbeit für die Notfallwiederherstellung bereits erledigt, als Beispiel-Startup seine Infrastruktur auf Terraform umstellte und in Teil 3 der Reihe zu einer Mehrkonten-Architektur überging.
Als erstes macht sich das Team des Beispiel-Startups mit dem AWS Resilience Hub vertraut, um mehr über die Erstellung von widerstandsfähigen Anwendungen in AWS zu erfahren. Da das Team noch einige offene Fragen hat, setzt es sich mit seinem AWS-Account-Team in Verbindung, das es mit einem SA mit Fachkenntnissen im Bereich Resilienz bekannt macht. Der SA arbeitet mit Beispiel-Startup zusammen, um die Anforderungen an das Recovery Time Objective (RTO) und Recovery Point Objective (RPO) zu spezifizieren und eine Kosten-Nutzen-Analyse verschiedener Szenarien der Notfallwiederherstellung durchzuführen. Nach einigen Gesprächen mit dem SA und einer Menge interner Überlegungen entscheidet das SRE-Team, dass ihre RTO/RPO-Anforderungen noch keine Einrichtung mit mehreren Regionen erfordern. Sie beschließen, ihre Transaktionsdaten von Amazon RDS für PostgreSQL nach Amazon Aurora für PostgreSQL zu verlagern. Dies geschieht in erster Linie wegen der höheren Verfügbarkeit, die Amazon Aurora bietet, sowie wegen der Funktionalität von Amazon Aurora Global Database, die für ihre Produktionsdatenbank wichtig ist. Das Startup nutzt außerdem AWS Audit Manager, um die Einhaltung der relevanten Compliance-Standards für das bevorstehende Audit zu bewerten. Die Funktion zur automatisierten Beweiserfassung erspart ihnen eine Menge manuellen Aufwand.
Entwickeln eines besseren Kundenerlebnisses
Nach Durchsicht des Produktfeedbacks verschiedener Kunden stellt der Chief Technology Officer (CTO) fest, dass die Dashboarding-Funktionen, die Händlern in der Handelsanwendung von Beispiel Startup angeboten werden, fehlen. Mit Mitbewerbern können Benutzer auf einfacher Handelsebene eine visuelle Darstellung des Handelsverlaufs und der Leistung (im Vergleich zu anderen Händlern) anzeigen. Der CTO kennzeichnet dies als kritische Funktionslücke und die Arbeit wird dem neuen Analyseteam zugewiesen. Außerdem möchte der CTO, dass das Team den Händlern ermöglicht, nach Belieben Handelsberichte zu erstellen.
Das Analytik-Team verfügt bereits über Erfahrung mit Amazon Quicksight, so dass die Dashboard-Komponente leicht zu erweitern sein wird. Dazu gehört auch eine Funktion zur Anomalieerkennung, mit der Händler bestimmte Ergebnisse finden können, die Abweichungen darstellen. Die Anfrage für die Berichterstattung ist komplexer, da sie die Entwicklerteams durch die Ausführung dieser Berichte in der Produktionsdatenbank nicht beunruhigen möchten (und das würde auch nicht als gute Praxis angesehen werden). Nach Durchsicht des Whitepapers Moderne Datenarchitektur in AWS erkennt das Analytik-Team, dass der beste Weg, dies zu tun, darin besteht, die Daten aus Amazon RDS für PostgreSQL in Amazon Redshift, ein Data Warehouse, zu laden. Mithilfe der massiven Parallelität von Amazon Redshift sind sie in der Lage, komplexe Aggregationen mit diesen Transaktionsdaten auszuführen, und zwar mit weitaus weniger Latenz und mit dem zusätzlichen Vorteil, dass die Produktionsdatenbank nicht durch Engpässe belastet wird. Das Analytik-Team stellt erfreut fest, dass es die meisten seiner Abfragen wiederverwenden kann, da Amazon Redshift auf der PostgreSQL-Engine entwickelt wurde.
Hinzufügen eines neuen Geschäftsbereichs zum Startup
Während all diese Veränderungen stattfinden, nimmt die Geschäftsführerin (CEO) an einem Treffen mit einem ihrer ehemaligen Kollegen bei einem großen Handelsunternehmen teil. Sie erfährt, dass es auf dem Markt einen Mangel an effektiven Händlern gibt und dass sich dies negativ auf die Einstellungspipeline des Handelsunternehmens und zukünftige Projekte auswirkt. Die CEO ruft einige ihrer Freunde bei Handelsunternehmen an, die bestätigen, dass es sich um einen branchenweiten Mangel handelt. Die CEO fasst eine Idee ins Auge: Beispiel-Startup hat viele Händler, die gute Arbeit leisten. Wie wäre es, wenn Beispiel-Startup seinen Händlern eine Art kohortenbasiertes Training anbietet, das dann in eine Talentpipeline für diese Handelsunternehmen einfließt? Dies würde den Händlern die Chance geben, in den Arbeitsmarkt einzusteigen, und die Handelsunternehmen würden über neue Talente verfügen.
Da ein wichtiger Teil der Ausbildung darin besteht, neuen Auszubildenden die richtigen Geschäfte zu empfehlen, ruft die CEO das Datenwissenschaftsteam an, um zu erfahren, wie schnell es ein Machine Learning (ML)-Modell entwickeln kann. Glücklicherweise haben einige Mitglieder des Datenwissenschaftsteams bereits Erfahrung mit dem Erstellen, Trainieren und Bereitstellen von Modellen mit Amazon Sagemaker. Da Amazon Redshift eine der verfügbaren Datenquellen für SageMaker ist, muss das Datenwissenschaftsteam keine komplexe ETL-Pipeline (Extrahieren, Transformieren und Laden) einrichten. Mitglieder des Datenwissenschaftsteams, die weniger Erfahrung mit SageMaker haben, wurden von ihrem AWS-Kontoteam zu einem SageMaker-spezifischen Vertiefungstag eingeladen, um sich schnell fortzubilden. Bald waren auch sie in der Lage, Trainingsaufträge zu entwickeln, genaue Modelle zu erstellen und die Modelle an den Endpunkten bereitzustellen. In Erwartung des Anrufs des Finanzteams von Beispiel-Startup aufgrund der steigenden Rechenkosten hat das Datenwissenschaftsteam einige Nachforschungen durchgeführt und festgestellt, dass sie ihre Trainingsaufträge (die etwa 80 % ihrer Gesamtkosten ausmachen) auf Spot Instances ausführen können. Auf diese Weise konnten sie ihre Kosten erheblich senken.
Als sich die Nachricht von dieser Talententwicklungsinitiative als neuer Geschäftsbereich und Einnahmequelle in der Branche verbreitet, zeigen immer mehr Risikokapitalfirmen (VC) Interesse an das Beispiel-Startup – noch bevor das Startup seine Absicht bekannt gibt, eine weitere Finanzierungsrunde zu starten!
Einige Quartale später war die Talententwicklungsinitiative des Beispiel Startups dank der Marketingbemühungen, der gemeinsamen Vermarktung mit AWS und der Mundpropaganda bestehender Kunden schnell gewachsen. So aufregend das Wachstum des Kundenstamms auch ist, noch aufregender ist die Tatsache, dass das Startup zum ersten Mal seit seiner Gründung im grünen Bereich ist! Die Personalbeschaffung erweist sich als profitables Geschäft für das Startup und wächst von Tag zu Tag. Das Führungsteam erkennt, dass dieser stetige Profitstrom den Rest des Geschäfts ankurbeln könnte. Sie arbeiten fleißig an weiteren Erweiterungs- und Innovationsplänen und sind begeistert von den unglaublichen Möglichkeiten, die vor ihnen liegen.
Zusammenfassung
Im Verlauf dieser vierteiligen Serie durchläuft Beispiel Startup die Hauptphasen eines Startups von der Entstehung bis hin zu einem ausgereiften Unternehmen. Die meisten Startups beginnen mit kaum mehr als einer mutigen Idee und einem engagierten Gründerteam. Sie erstellen ein Produkt mit minimaler Rentabilität (Minimum Viable Product, MVP) mit Serverless-Infrastruktur, die es ihnen ermöglicht, ihre Idee auf eine Weise zu testen, die das Gründerteam allein bewältigen kann.
Wenn das Startup zahlende Kunden akquiriert und die Finanzierung nach der Gründungsphase gesichert ist, geht es in die Phase des „Aufbruchs“ über, in der sich die Architektur weiterentwickelt und man beginnt, ernsthaft über Skalierung, Sicherheit und Entwicklungsagilität nachzudenken. Dies bedeutet Verbesserungen wie die Verwendung von Entwicklungs-Tools, die Einrichtung von Überwachungsfunktionen und speziell entwickelten Datenbanken.
Eine der wichtigsten Lektionen in diesen Phasen ist die frühzeitige und häufige Zusammenarbeit mit dem AWS-Team, sogar vor Projektbeginn, mit dem AWS-Team in Kontakt zu treten, um Optionen zu evaluieren und Zeit zu sparen. Der Zugriff auf geschäftliche und technische Ressourcen kann Zeitpläne beschleunigen und Startup-Teams in der Anfangsphase dabei helfen, ihre Ziele zu erreichen.
Nach der Phase der Produktmarktanpassung stellen Startups möglicherweise mehr Mitarbeiter ein und konzentrieren sich vor allem auf die Skalierung – die „auf zum Mond“-Phase. Zu diesem Zeitpunkt beginnen sie, eine Mehrkontenstrategie in Betracht zu ziehen und nutzen eine serviceorientierte Architektur, Caching und andere architektonische Verbesserungen, um ihre Anwendung zu optimieren und das Kundenerlebnis aus technischer Sicht zu verbessern.
Schließlich treten sie in die Phase des großen Maßstabs ein, in der sie möglicherweise umfangreiche Einstellungen vornehmen und zusätzliche Geschäftsbereiche aufbauen. Aus technischer Sicht hat das Startup viel Zeit und technischen Aufwand in die Verbesserung von Dingen wie Sicherheit, Kontrollen und Berechtigungen für seine Umgebung investiert. Sie verfügen wahrscheinlich über eine kodifizierte Version ihrer Umgebung, die sie unter anderem für eine schnelle internationale Erweiterung und Notfallwiederherstellung nutzen können. Sie haben außerdem eine Datenstrategie entwickelt und sind dabei, Analytik und Machine Learning einzusetzen, um ihre Kunden und ihr Geschäft besser zu verstehen. Diese letzte Phase kann variieren. Einige Startups sind auf dem Weg zu einer Übernahme, während andere Profitabilität und Marktdominanz anstreben.
Sind Sie bereit, Ihr Startup zu gründen? Werden Sie Mitglied bei AWS Activate, um Ihr Startup mit den richtigen Ressourcen zur richtigen Zeit zu entwickeln und zu skalieren.
Erkunden Sie die gesamte Serie „Evolutionäre Architekturen“:

Aayzed Tanweer
Aayzed ist Solutions Architect bei AWS und arbeitet mit Startup-Kunden im FinTech-Bereich zusammen, wobei der Schwerpunkt auf Analytics-Services liegt. Ursprünglich aus Toronto stammend, ist er vor Kurzem nach New York City gezogen, wo er sich gerne seinen Weg durch die Stadt bahnt und ihre vielen eigenartigen Ecken und Winkel erkundet.

Justin Plock
Justin ist Principal Solutions Architect bei AWS und konzentriert sich auf Fintech-Startups. Er trifft sich regelmäßig mit Fintech-Gründern, um sicherzustellen, dass ihr Unternehmen sicher ist und den Branchenvorschriften entspricht. Vor seiner Zeit bei AWS war er Direktor für Cloud-Enablement bei einem Fortune-200-Versicherungsträger und Director of Engineering bei einem Cybersicherheitsunternehmen. Seine Leidenschaft ist es, Startups dabei zu helfen, sich sicher und effizient in AWS zu entwickeln. Er lebt mit seiner Frau und zwei Töchtern in Connecticut.

Zoran Nakev
Zoran ist Senior Solutions Architect bei AWS, arbeitet hauptsächlich mit FinTech-Startups zusammen und hilft ihnen bei der Entwicklung von Lösungen auf der AWS-Plattform. Er nutzt seine Erfahrung und Leidenschaft für Technologie, um Startups dabei zu unterstützen, ihre Ziele zu erreichen. Er lebt mit seiner Familie in New Jersey und verbringt seine Freizeit gerne damit, Filme zu schauen, Musik zu hören und lange Spaziergänge mit seinem Familienhund zu unternehmen.
Wie war dieser Inhalt?