AWS Architecture Blog
Disaster Recovery (DR) Architecture on AWS, Part II: Backup and Restore with Rapid Recovery
In a previous blog post, I introduced you to four strategies for disaster recovery (DR) on AWS. These strategies enable you to prepare for and recover from a disaster. By using the best practices provided in the AWS Well-Architected Reliability Pillar whitepaper to design your DR strategy, your workloads can remain available despite disaster events such as natural disasters, technical failures, or human actions.
DR strategies: Choosing backup and restore
As shown in Figure 1, backup and restore is associated with higher RTO (recovery time objective) and RPO (recovery point objective). This results in longer downtimes and greater loss of data between when the disaster event occurs and recovery. However, backup and restore can still be the right strategy for your workload because it is the easiest and least expensive strategy to implement. Additionally, not all workloads require RTO and RPO in minutes or less.

Figure 1. DR strategies
Implementing backup and restore
In Figure 2, we show AWS resources that may be used by your workload, including:
- Amazon Elastic Block Store (Amazon EBS): EBS volume
- Amazon Elastic Compute Cloud (Amazon EC2): EC2 instance
- Amazon Relational Database Service (Amazon RDS): DB instance
- Amazon Elastic File System (Amazon EFS)
These are just some examples of data storage resources that are available for you to use on AWS.
AWS Backup provides a centralized view where you can configure, schedule, and monitor backups for these resources. When using the backup and restore strategy, your RPO is determined by how often your backups run.
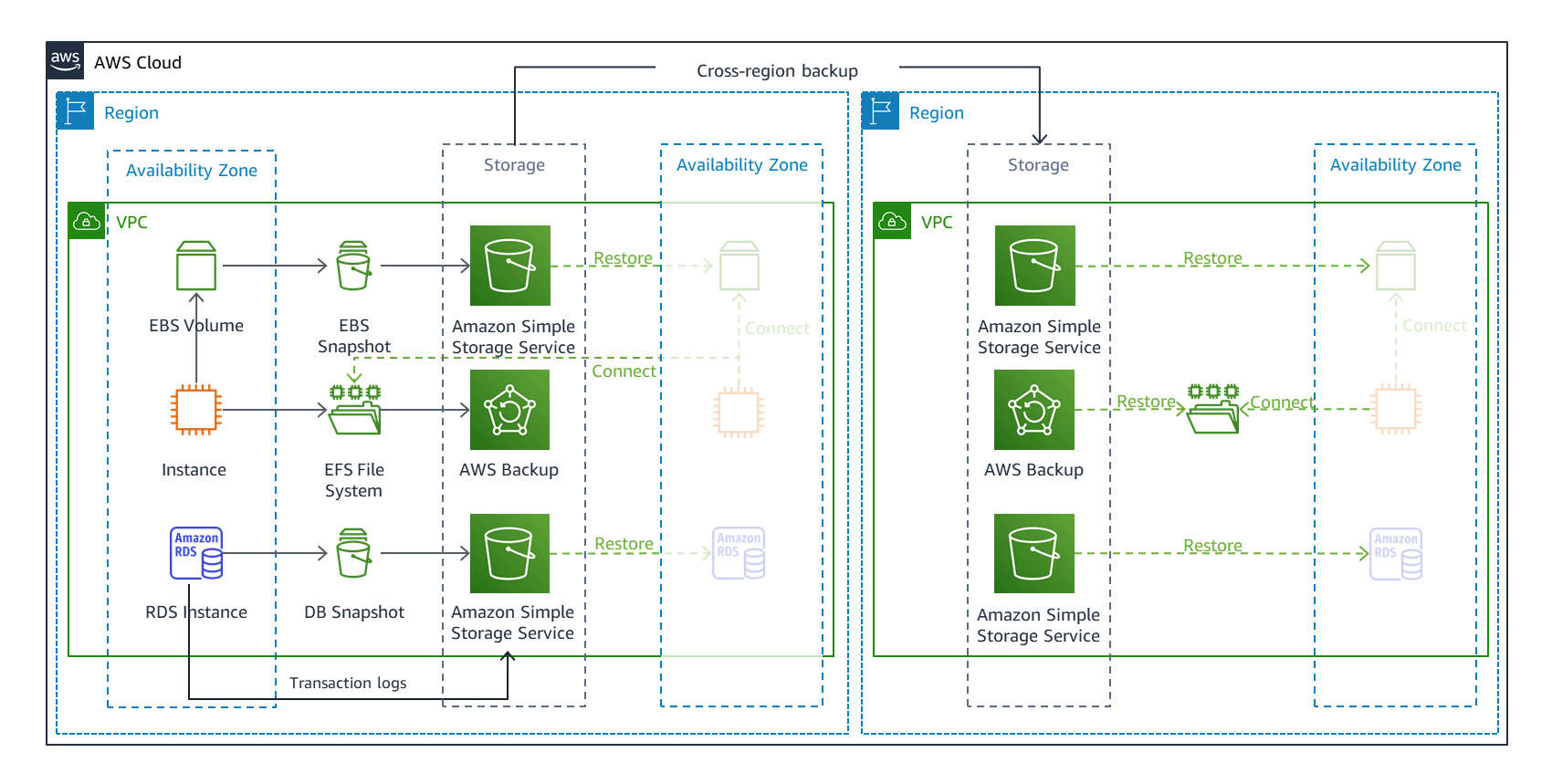
Figure 2. Backup and restore DR strategy
Backup within the AWS Region
Every AWS Region consists of multiple Availability Zones (AZs). A Multi-AZ strategy, which replicates resources across AZs, is necessary to provide high availability (HA).
The HA strategy provides much of what your workload needs for DR within a single Region. However, disaster events include human actions and software bugs that can erase or corrupt your data. If this happens, HA strategies will replicate these types of data errors. So, for DR you must additionally back up your data stores within the Region (Figure 2). Using backups that offer point-in-time recovery (such as point-in-time recovery for Amazon DynamoDB and restoring a DB instance to a specified time for RDS), or enabling versioning (using versioning in Amazon Simple Storage Service (Amazon S3) buckets), will let you “rewind” to the last known good state.
Backup to another AWS Region
In addition to centralized control for backups, AWS Backup lets you copy backups across Regions, as shown in Figure 2, as well as across AWS accounts. By copying your data to another Region, you can handle the largest scope of disasters. If a disaster prevents your workload from operating in a Region, the workload can be restored to a recovery Region (Figure 3) and operate from there.
For your recovery Region, you can use a different AWS account than your primary Region, with different credentials. This can prevent human error or misdeed in one Region from impacting the other.
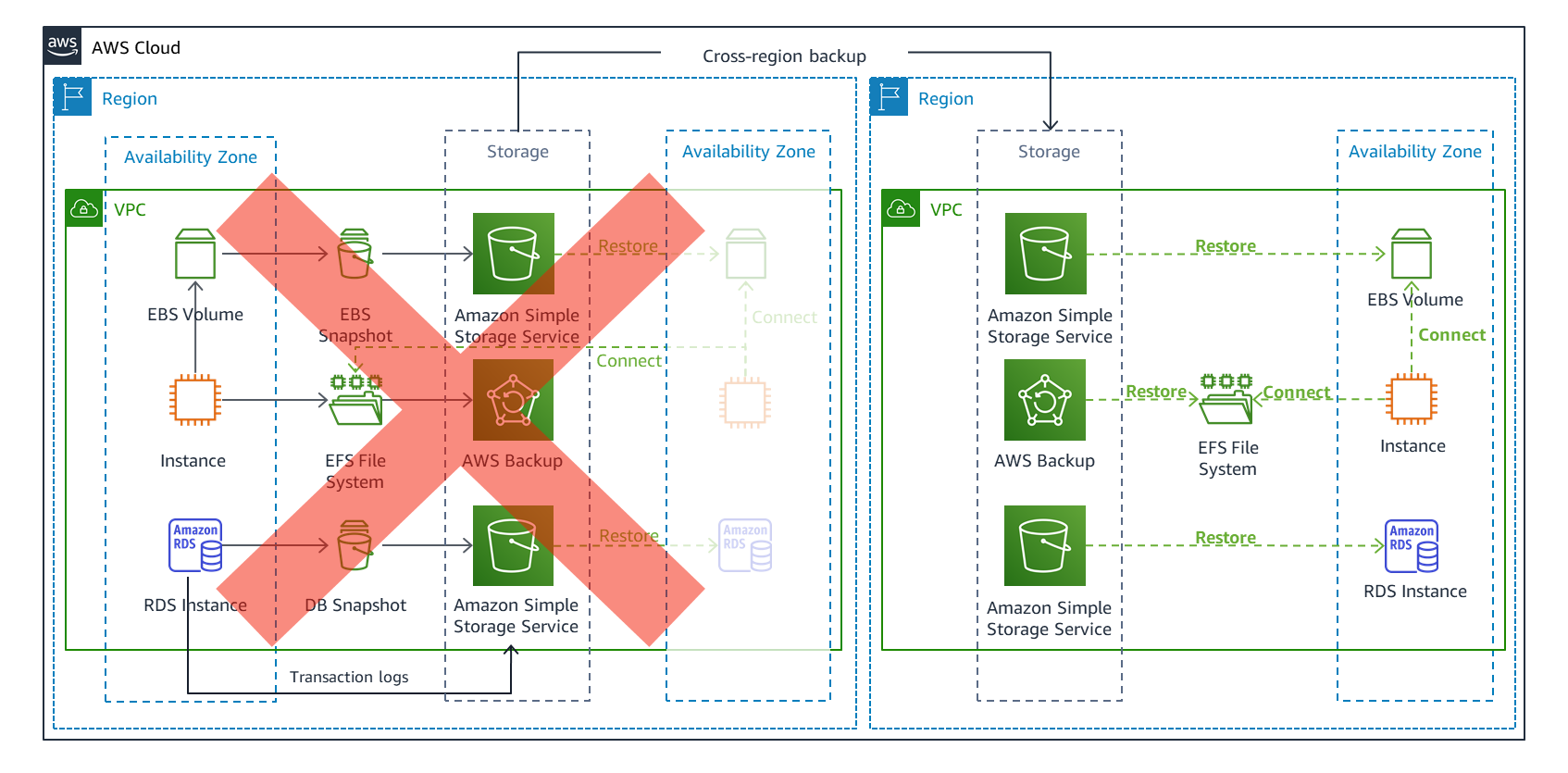
Figure 3. Failover and cross-Region recovery with a multi-Region backup and restore strategy
Getting the most out of backup and restore
When a disaster occurs, you will accomplish your DR strategy using these steps:
- Detect the impact of the disaster event on your workload
- Restore infrastructure, data, and re-integrate these to enable your workload to operate
- Fail over, re-routing requests to the recovery Region
1. Detect
Recovery time (and therefore RTO) is often thought of as the time it takes to restore the workload and fail over. But as shown in Figure 4, time to detection and the time to decide to fail over are additional (and potentially significant) contributors to recovery time.

Figure 4. Contributors to recovery time after a disaster event
To reduce recovery time, detection should be automated. Do not wait until your operators notice the problem, and never wait until your customers notice it.
In Figure 5, we show a possible architecture for detecting and responding to events that impact your workload availability.
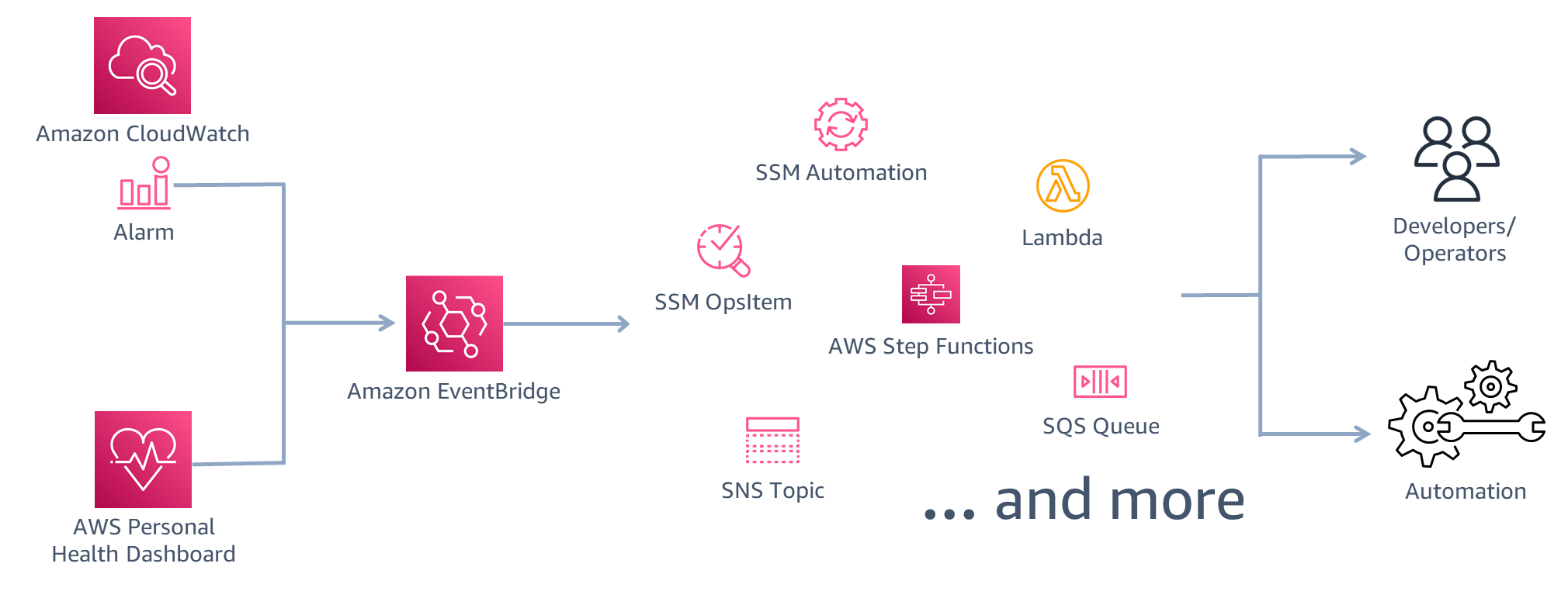
Figure 5. Using EventBridge to detect and respond to a disaster event
Amazon EventBridge supports events from many AWS services and targets actions in response to those events. Here, two event sources are used:
- Amazon CloudWatch features CloudWatch Alarms that are activated from metrics based on a configuration you define. This can be from several metrics using math expressions or based on multiple other alarms. The result is that you can configure sophisticated health checks based on behavior of your workload. Additionally, using CloudWatch Anomaly Detection, you can detect if site engagement, orders, or other key performance indicators have dropped. This is a strong indicator that your workload is impacted by an event.
- AWS Health alerts you when AWS is experiencing events that may impact you. You can view the dashboard in the AWS Management Console and configure EventBridge to monitor and react to these events. In the following example, EventBridge is configured to react to events that are causing increased error rates in PUT and GET operations on Amazon S3.
{ "source": ["aws.health"], "detail-type": ["AWS Health Event"], "detail": { "service": ["S3"], "eventTypeCategory": ["issue"], "eventTypeCode": ["AWS_S3_INCREASED_GET_API_ERROR_RATES", "AWS_S3_INCREASED_PUT_API_ERROR_RATES"] } }
Figure 5 shows that there are many actions we can take as a result of these events. We might track the event by creating an OpsItem in AWS Systems Manager. Or we can alert developers and operators by using Amazon Simple Notification Service (Amazon SNS) to send an email or text message. There are several options for automated response. AWS Lambda can run code, or Systems Manager automation can be activated to initiate runbooks that perform tasks like starting EC2 instances or deploying stacks on AWS CloudFormation.
2. Restore
Restoring data from backup creates resources for that data such as EBS volumes, RDS DB instances, and DynamoDB tables. Figure 6 shows that you can use AWS Backup to restore data in the recovery Region (in this case, for an EBS volume). Rebuilding the infrastructure includes creating resources like EC2 instances in addition to the Amazon Virtual Private Cloud (Amazon VPC), subnets, and security groups needed.
For restoring infrastructure in the recovery Region, you should use Infrastructure as code (IaC). This includes using CloudFormation and AWS Cloud Development Kit (AWS CDK) to create infrastructure consistently across Regions. To create the EC2 instances your workload needs, use Amazon Machine Images (AMIs) to incorporate the required operating system and packages. Since these AMIs contain exactly what you need to stand up consistent servers, we refer to these as “golden AMIs.” Amazon EC2 Image Builder can be used to create golden AMIs and copy them to your recovery Region.

Figure 6. Restoring data from backup and rebuilding infrastructure in a recovery Region
In some cases, you will need to re-integrate your infrastructure and data. For example, in Figure 6 we have recovered stateful data in an EBS volume. We want to re-attach that volume to an EC2 instance. Figure 7 shows one possible way to automate this.
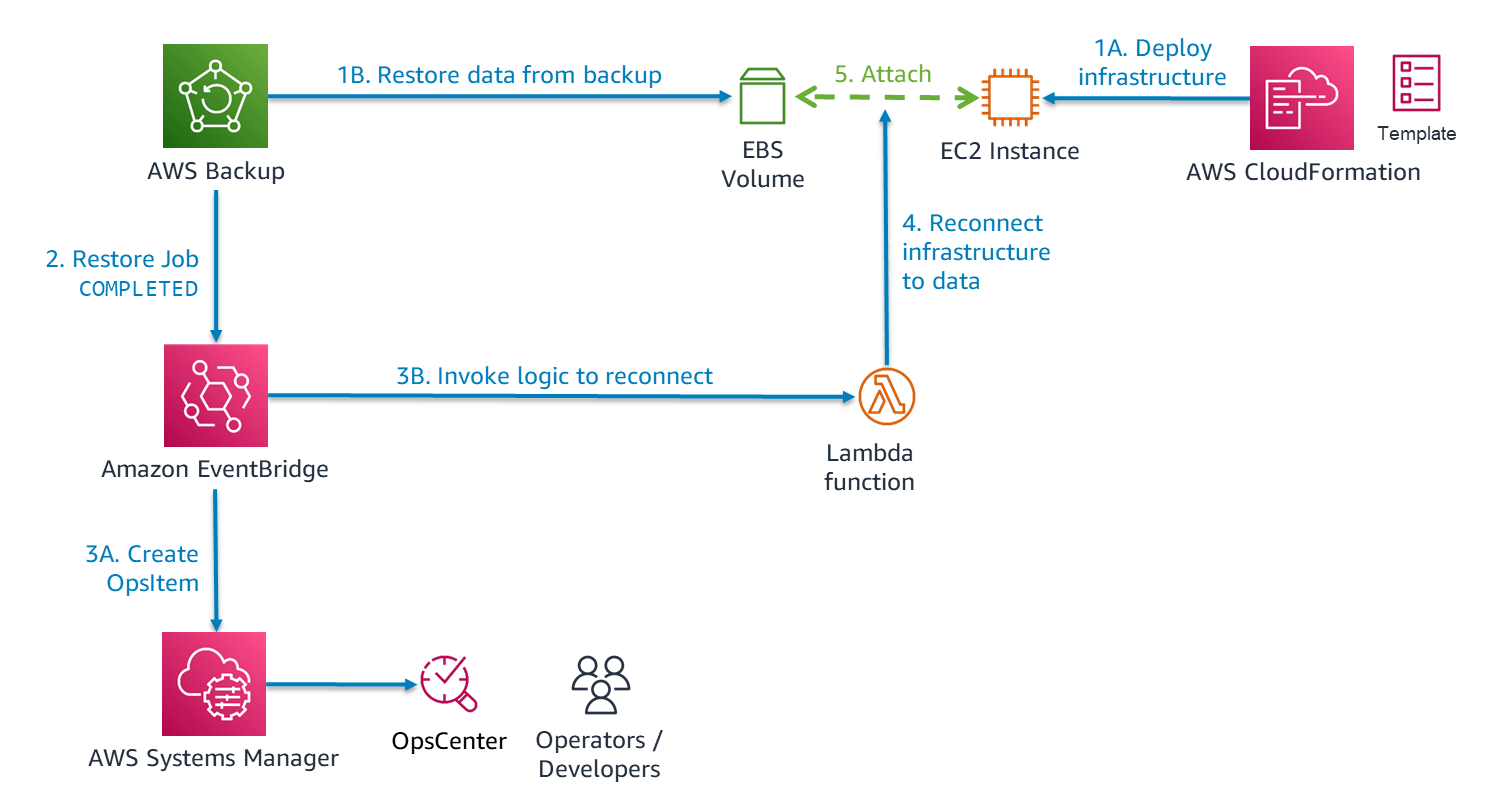
Figure 7. Automating integration of infrastructure and data as part of restoring a workload
Using EventBridge, we implement a serverless solution. AWS Backup emits an event after completing data restore for a resource. Reacting to this, EventBridge initiates two actions: 3A) create an item in OpsCenter for tracking and 3B) invoke a Lambda function. From the event, Lambda gets the ID of the new resource that was created in the recovery Region, as well as the ID of the backup used for recovery (recovery point). The Lambda code makes an API call to get tags that were on the original resource (in the primary Region), which can guide you in configuring the integration. AWS Backup will automatically copy tags from a resource to the backups it makes. With another API call to CloudFormation, Lambda can learn the ID of the EC2 instance. Then it can call the APIs on Amazon EC2 to attach the EBS volume to it.
Figure 7 shows you how to attach an EBS volume to an EC2 instance, but there are other integrations you may want to automate. For example, instead of a Lambda function, the data restore event might activate a runbook on Systems Manager. This will automatically mount a restored EFS or Amazon FSx file system on one or more EC2 instances.
For more comprehensive automation, you could use AWS Step Functions to orchestrate everything. This includes the infrastructure deployment using CloudFormation, the data restore using AWS Backup, and the integration steps. With Step Functions, you configure a state machine that invokes Lambda functions to initiate and monitor each activity in the required order with the required dependencies.
3. Fail Over
Failover re-directs production traffic from the primary Region (where you have determined the workload can no longer run) to the recovery Region. This is covered in another blog post.
Conclusion
As business and engineering teams collaborate on DR goals and implementation, consider using the backup and restore strategy to meet the DR needs for your workload. Using automation, you can minimize RTO and therefore lessen the impacts of downtime in the event of a disaster. This strategy’s lower cost and relative ease of implementation makes it a good choice for many AWS workloads.
Find out more
Other posts in this series
- Disaster Recovery (DR) Architecture on AWS, Part I: Strategies for Recovery in the Cloud
- Disaster Recovery (DR) Architecture on AWS, Part III: Pilot Light and Warm Standby
- Disaster Recovery (DR) Architecture on AWS, Part IV: Multi-site Active/Active