How was this content?
- Learn
- Qbiq: Using AWS Lambda container images & distributed ML to optimize construction
Qbiq: Using AWS Lambda container images & distributed ML to optimize construction
Guest post by Qbiq Team and Hilal Habashi. Startup Solutions Architect, AWS
Real estate software startup Qbiq system delivers an artificial intelligence (AI)-driven space planning design engine that generates large volumes of customized floor plans, compares alternatives, and optimizes the results. It instantly provides suggestions for the best layout design within the constraints of space utilization, costs, build time, efficiency, and a multitude of other factors. These non-trivial compute intensive calculations are done behind the scenes in a distributed manner by dividing each job request into multiple parts. More specifically, each plan received is broken down into sub plans, and each of these sub plans are processed using machine learning (ML) and nonlinear programming. First, we use ML models to recognize and analyze the different layout alternatives, and then we optimize the results using quadratic equations.
We chose AWS right at the start of our journey because of the flexibility and elasticity in AWS’s offering. It is a perfect fit considering our significant compute power requirements in each step of the pipeline. In fact, aside from our main workload, our preprocessing stage, which divides the plans and requires both spatial and geometrical analysis as well as a heavy hyper-parameters search – a non trivial workload by itself. We also heavily rely on its backbone network coverage and response times, its breadth of services, and the pay-as-you-go cost model. All of these allow us to scale our service and bring it to as many customers as we can.
In order to support our business model, we needed to provide our clients with a fast and reliable software-as-a-service (SaaS) solution, which is quite different from what we had in mind when we first started. We’ve had our fair share of challenges throughout the process of building the distributed workload presented in this post, and as with any case of significant architectural change, we needed to find a happy medium between the adoption of new technologies and onboarding and training our engineering team to build the best product we could.
Challenges
Developing distributed ML algorithms
We started out as a cloud-native SaaS solution running on Amazon EC2 instances. In order to perform a large number of computations in a limited run time (sub 5 minute), we had to divide our workload into tiny segments and run subtasks in a distributed manner. As we started to horizontally scale our compute on AWS, we also had to rework our algorithms, use a shared storage to store the different models we need to run, and build a queue of jobs received over time. Thanks to Amazon EFS, and Amazon SQS, we were able to quickly implement and maintain the supporting infrastructure for our distributed compute needs with little to no effort of our small team. EFS enabled us to share a storage between our AWS Lambda containers and use the drive as a shared mounted storage for our subprocesses.
Deploying and maintaining our algorithms
It was important for us to deploy our algorithms in a container-based approach without using proprietary tooling or having to write our own deployment scripts from scratch. We wanted a solution that would work with the traditional Git-ops approach and abstract out the environment that our containers ran on. We wanted to quickly scale out the compute power available based on demand and without worrying about provisioning or managing any container clusters. We chose to use Lambda containers with EFS over solutions based on AWS Fargate or EC2, with Amazon EBS since we wanted a highly flexible and scalable solution with a pay-as-you-go model that didn’t require us to perform container orchestration and management tasks.
Testing our algorithms at load
We had to write end-to-end tests in order to verify that our calculations performed correctly across our cluster of distributed tasks regardless of its size whether running it locally or on the cloud. In reality, when we ran and orchestrated our workload on EC2, we noticed that the more instances of distributed software we added, the harder it became to maintain the configurations and test our stack as a whole. Our high-level goal was to improve our cloud fidelity and avoid maintaining two sets of setup scripts with a mutual codebase. In addition, we wanted to be able to test our product at high load scenarios, without extensive configurations.
AWS Lambda Containers in our Cloud Architecture
The recently added support for custom container images in Lambda have ticked all the boxes for us. It was easy to write our algorithms and wrap them, along with all of our dependencies, inside a container image. After doing so, we had to mount volumes, add new model files onto our container images, and test our software both locally and on the cloud. Adopting containers has simplified our deployment process by solely relying on our trusted Git-based flow rather than on external devops tools. Finally, we managed to reduce our compute resource management to a simple task of configuring memory and vCPU for our Lambda, a task which was made even easier by Lambda Power Tuning. The container images running on Lambda in our environment are essentially the core of our product, and thanks to the mature state of Lambda event source integrations with the rest of the AWS services, the migration from EC2 was effortless.
High level overview:
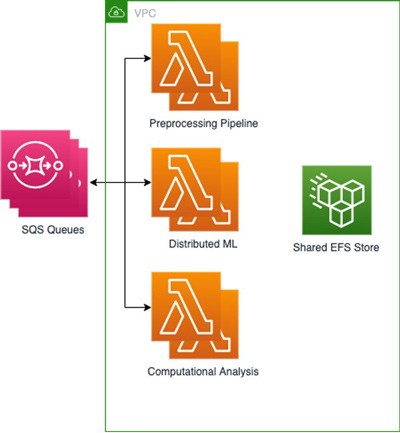
We’ve built 3 Lambda functions using Amazon Elastic Container Registry (Amazon ECR) to store each of our 3 base images; one for each part of the process, with their basic dependencies and settings included as files and environment variables. We then connected EFS to store the outputs of each task so they will be rapidly available for the following tasks, while our distributed ML models were stored in Amazon S3. Since our distributed ML processes cut down the tasks even further, it was crucial to have a mutual file system that can be mounted and accessed within any container-based workload. This setup allowed us to share files with high throughput and low overhead between the various Lambda functions. We use several SQS queues containing information about the jobs, with incoming files.
This architecture allows us to achieve similar result and overall time to deployments over EC2 cluster while reducing costs by paying for only the time that the algorithms are running. For example, we are able to produce a batch of 50 results in 2 minutes by invoking 5,000 Lambda functions with maximum concurrent execution of 500, which results in an average cost of $1 per batch. On the other hand, running it on EC2 cluster with 500 parallel cores would have cost about twice as much and will necessitate provisioning the cluster. Finally, our ML engineers and data scientists can operate within the container-based environments they are familiar with while using one set of tests instead of writing a unique set for a non-containerized environment running on the cloud as they did before.
Managing our workload
In order to manage our distributed ML workload reliably, we implemented our own graph-based workflow manager. Each job request sent by a user starts out with a file being uploaded and its name being recorded as a Topic Name. We then create a sub-graph for each Topic Name that can contain multiple nodes under it – one node for each computational task to be processed. Each node in the job’s sub-graph contains an internal state representation. The edges in the subgraphs are a function of the input and the next task to be executed.
Our current workload is a 3-step process, meaning that we multiply the number of parts we divided each job into by three. The preprocessing pipeline breaks down the jobs and their corresponding files into multiple parts. A sub-graph is created for each job, and the workflow manager then loads the jobs into the system containing many nodes. We start processing the nodes inserted in parallel by traversing the edges of our graph and correspondingly loading the current state information into the next Lambda function, each step at a time. The workflow manager records the data in the corresponding node for each step of the process and part of the job and continues until all the data for the job is processed. Finally, we aggregate the results and communicate them to our customers.
The workflow manager communicates with the Lambda functions through a REST API using two types of POST requests:
1) `RequestRequired` is a synchronous request that can handle large payload size but has a response time limitation of 30 seconds.
2) `Event` is an asynchronous request and works well for sending multiple parallel jobs with a small payload.
Architecting the workflow manager:
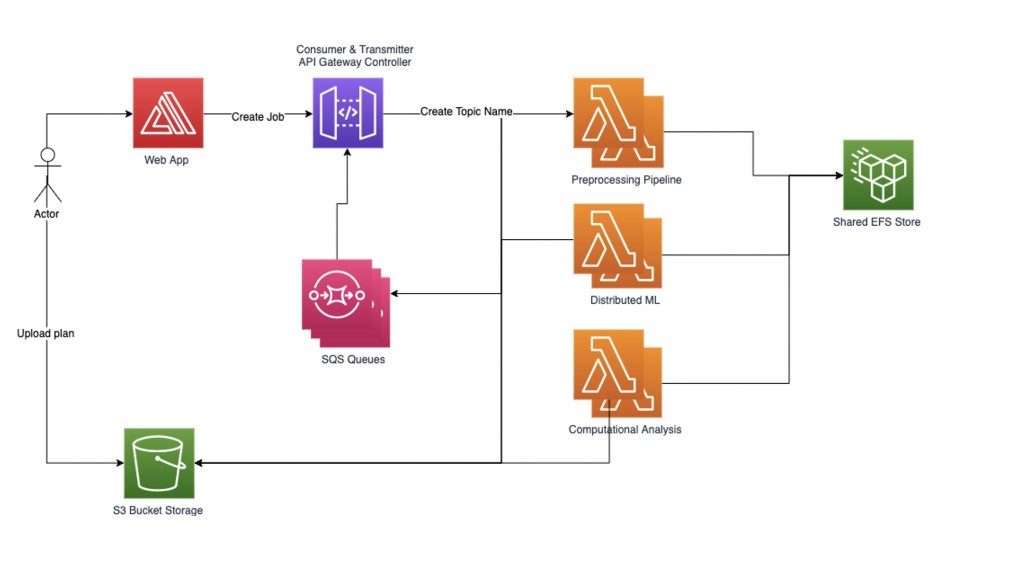
The workflow manager sets up two helper threads: transmitter and consumer. The transmitter thread is responsible for checking the asynchronous jobs queue and managing which jobs to activate by sending them to the Lambda functions. We can control the number of simultaneous active jobs as a parameter in order to control active Lambdas concurrency. When a job is sent to be processed by a lambda function, the request contains a SQS queue name to which it should write the responses. The consumer thread is responsible for consuming the messages from the SQS queue and to distributing incoming job responses according to their topic.
As we deploy a large number of tasks with a limited worker pool so not to exceed concurrency limits, nodes that do not converge or require irregular computational time can significantly reduce the system performance. To protect against hanging or overly long jobs, a three timeouts system is used. The first timeout is the basic lambda timeout that is configured when setting up a Lambda function. This timeout should be pretty loose since it should potentially never be reached. The second timeout is within each lambda function. When the function handler is called, it starts an additional thread and waits for a specific amount of time. If the timeout is reached, the Lambda function sends back a timeout error response to the queue. The last is a topic timeout in the workflow manager that is agnostic to Lambda functions and is triggered if more than a certain amount of time is passed since the last job post was sent under this topic.
To achieve high performance with fast warmup (lower the start time), we used the Provisioned Concurrency feature of the Lambda functions. We also use an initialization call to warm up the Lambda function and prepare the data. The EFS throughput is provisioned to allow high MiB/sec to eliminate bottlenecks when multiple lambdas access the data stored on EFS in parallel.
Conclusion
At Qbiq, we bring cutting-edge AI, generative design, and optimization technology to real-estate planning. Using AWS Lambda image containers enables us to easily scale to hundreds of cloud processors loaded with hundreds of years of architectural experience, process the planning request, analyze different layout alternatives, and optimize the results.
We provide our customers with the best construction alternatives considering utilization, costs, build time, efficiency, and more. For more information about Qbiq, please visit our website, qbiq.ai.

AWS Editorial Team
The AWS Startups Content Marketing Team collaborates with startups of all sizes and across all sectors to deliver exceptional content that educates, entertains, and inspires.
How was this content?