Comment a été ce contenu ?
- Apprendre
- Qbiq : utilisation des images de conteneurs AWS Lambda et du ML distribué pour optimiser la construction
Qbiq : utilisation des images de conteneurs AWS Lambda et du ML distribué pour optimiser la construction
Article d'invité de l'équipe Qbiq et Hilal Habashi. Startup Solutions Architect, AWS
La startup de logiciels immobiliers Qbiq System fournit un moteur de conception de planification de l'espace basé sur l'intelligence artificielle (IA) qui génère de grands volumes de plans d'étage personnalisés, compare les alternatives et optimise les résultats. Il fournit instantanément des suggestions pour la meilleure conception d'aménagement en tenant compte des contraintes d'utilisation de l'espace, des coûts, du temps de construction, de l'efficacité et d'une multitude d'autres facteurs. Ces calculs intensifs et non triviaux sont effectués en coulisse de manière distribuée en divisant chaque demande de travail en plusieurs parties. Plus précisément, chaque plan reçu est décomposé en sous-plans, et chacun de ces sous-plans est traité à l'aide du machine learning (ML) et de la programmation non linéaire. Tout d'abord, nous utilisons des modèles ML pour reconnaître et analyser les différentes alternatives de mise en page, puis nous optimisons les résultats à l'aide d'équations quadratiques.
Nous avons choisi AWS dès le début de notre parcours en raison de la flexibilité et de l'élasticité de l'offre d'AWS. C'est la solution idéale compte tenu de nos besoins importants en puissance de calcul à chaque étape du pipeline. En fait, outre notre charge de travail principale, la phase de prétraitement, qui divise les plans et nécessite à la fois une analyse spatiale et géométrique ainsi qu'une recherche approfondie d'hyperparamètres, est une charge de travail non négligeable en soi. Nous nous appuyons également largement sur la couverture et les temps de réponse de son réseau principal, sur l'étendue de ses services et sur le modèle de tarification à l'usage. Tout cela nous permet de mettre notre service à l'échelle et de le proposer au plus grand nombre de clients possible.
Afin de soutenir notre modèle commercial, nous devions fournir à nos clients une solution logicielle en tant que service (SaaS) rapide et fiable, très différente de ce que nous avions en tête à nos débuts. Nous avons rencontré notre lot de défis tout au long du processus de création de la charge de travail distribuée présentée dans cet article, et comme dans tout cas de changement architectural important, nous avons dû trouver un juste milieu entre l'adoption de nouvelles technologies et l'intégration et la formation de notre équipe d'ingénieurs afin de créer le meilleur produit possible.
Défis
Développement d'algorithmes ML distribués
Nous avons commencé en tant que solution SaaS native cloud exécutée sur des instances Amazon EC2. Afin d'effectuer un grand nombre de calculs dans un temps d'exécution limité (moins de 5 minutes), nous avons dû diviser notre charge de travail en petits segments et exécuter les sous-tâches de manière distribuée. Lorsque nous avons commencé à mettre à l'échelle horizontale nos calculs sur AWS, nous avons également dû retravailler nos algorithmes, utiliser un stockage partagé pour stocker les différents modèles que nous devions exécuter et créer une file d'attente des tâches reçues au fil du temps. Grâce à Amazon EFS et Amazon SQS, nous avons pu rapidement implémenter et maintenir l'infrastructure de support pour nos besoins de calcul distribué avec peu ou pas d'efforts de la part de notre petite équipe. EFS nous a permis de partager un stockage entre nos conteneurs AWS Lambda et d'utiliser le disque comme stockage monté partagé pour nos sous-processus.
Déploiement et maintenance de nos algorithmes
Il était important pour nous de déployer nos algorithmes dans le cadre d'une approche basée sur des conteneurs sans utiliser d'outils propriétaires ni avoir à écrire nos propres scripts de déploiement à partir de zéro. Nous recherchions une solution qui fonctionne avec l'approche GitOps traditionnelle et qui fasse abstraction de l'environnement dans lequel nos conteneurs fonctionnaient. Nous voulions augmenter rapidement la puissance de calcul disponible en fonction de la demande, sans nous soucier du provisionnement ou de la gestion de clusters de conteneurs. Nous avons choisi d'utiliser des conteneurs Lambda avec EFS plutôt que des solutions basées sur AWS Fargate ou EC2, avec Amazon EBS, car nous recherchions une solution hautement flexible et évolutive avec un modèle de paiement à l'utilisation qui ne nous obligeait pas à effectuer des tâches d'orchestration et de gestion des conteneurs.
Tester nos algorithmes à pleine charge
Nous avons dû écrire des tests de bout en bout afin de vérifier que nos calculs s'exécutaient correctement sur notre cluster de tâches distribuées, quelle que soit sa taille, qu'il soit exécuté localement ou sur le cloud. En réalité, lorsque nous avons exécuté et orchestré notre charge de travail sur EC2, nous avons remarqué que plus nous ajoutions d'instances de logiciels distribués, plus il devenait difficile de maintenir les configurations et de tester notre pile dans son ensemble. Notre objectif de haut niveau était d'améliorer la fidélité de notre cloud et d'éviter de conserver deux ensembles de scripts de configuration avec une base de code commune. De plus, nous voulions pouvoir tester notre produit dans des scénarios de charge élevée, sans configurations étendues.
Conteneurs AWS Lambda dans notre architecture cloud
La prise en charge récente des images de conteneurs personnalisées dans Lambda a coché toutes les cases pour nous. Il était facile d'écrire nos algorithmes et de les encapsuler, ainsi que toutes nos dépendances, dans une image de conteneur. Ensuite, nous avons dû monter des volumes, ajouter de nouveaux fichiers modèles sur nos images de conteneurs et tester notre logiciel à la fois localement et sur le cloud. L'adoption de conteneurs a simplifié notre processus de déploiement en nous appuyant uniquement sur notre flux fiable basé sur Git plutôt que sur des outils DevOps externes. Enfin, nous avons réussi à réduire la gestion de nos ressources informatiques à une simple tâche de configuration de la mémoire et du processeur virtuel pour notre Lambda, une tâche qui a été encore facilitée par Lambda Power Tuning. Les images de conteneur exécutées sur Lambda dans notre environnement constituent essentiellement le cœur de notre produit, et grâce à l'état de maturité des intégrations des sources d'événements Lambda avec le reste des services AWS, la migration depuis EC2 s'est faite sans effort.
Vue d'ensemble de haut niveau :
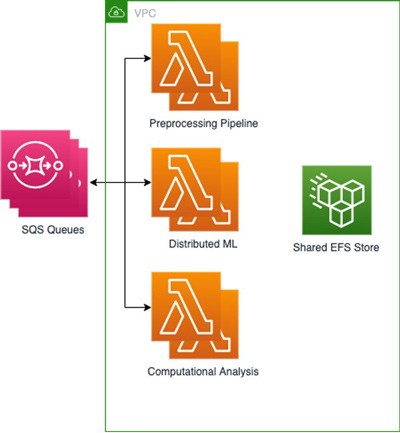
Nous avons créé 3 fonctions Lambda à l'aide d'Amazon Elastic Container Registry (Amazon ECR) pour stocker chacune de nos 3 images de base, une pour chaque partie du processus, avec leurs dépendances et paramètres de base inclus sous forme de fichiers et de variables d'environnement. Nous avons ensuite connecté EFS pour stocker les résultats de chaque tâche afin qu'ils soient rapidement disponibles pour les tâches suivantes, tandis que nos modèles de ML distribués étaient stockés dans Amazon S3. Étant donné que nos processus de machine learning distribués réduisent encore davantage les tâches, il était essentiel de disposer d'un système de fichiers commun pouvant être monté et accessible au sein de n'importe quelle charge de travail basée sur des conteneurs. Cette configuration nous a permis de partager des fichiers avec un débit élevé et une faible surcharge entre les différentes fonctions Lambda. Nous utilisons plusieurs files d'attente SQS contenant des informations sur les tâches, avec les fichiers entrants.
Cette architecture nous permet d'obtenir des résultats et un délai global similaires pour les déploiements sur le cluster EC2, tout en réduisant les coûts en ne payant que le temps d'exécution des algorithmes. Par exemple, nous sommes en mesure de produire un lot de 50 résultats en 2 minutes en invoquant 5 000 fonctions Lambda avec une exécution simultanée maximale de 500, ce qui se traduit par un coût moyen de 1 USD par lot. D'un autre côté, son exécution sur un cluster EC2 avec 500 cœurs parallèles aurait coûté environ deux fois plus cher et nécessiterait le provisionnement du cluster. Enfin, nos ingénieurs en machine learning et nos scientifiques des données peuvent travailler dans les environnements basés sur des conteneurs qu'ils connaissent bien tout en utilisant un seul ensemble de tests au lieu d'écrire un ensemble unique pour un environnement non conteneurisé exécuté sur le cloud comme ils le faisaient auparavant.
Gérer notre charge de travail
Afin de gérer de manière fiable notre charge de travail de machine learning distribuée, nous avons implémenté notre propre gestionnaire de flux de travail basé sur des graphes. Chaque demande de travail envoyée par un utilisateur commence par le chargement d'un fichier et l'enregistrement de son nom en tant que nom de rubrique. Nous créons ensuite un sous-graphe pour chaque nom de rubrique qui peut contenir plusieurs nœuds en dessous, à savoir un nœud pour chaque tâche de calcul à traiter. Chaque nœud du sous-graphe de la tâche contient une représentation d'état interne. Les arêtes des sous-graphes sont fonction de l'entrée et de la prochaine tâche à exécuter.
Notre charge de travail actuelle est un processus en 3 étapes, ce qui signifie que nous multiplions le nombre de parties en lesquelles nous avons divisé chaque tâche par trois. Le pipeline de prétraitement décompose les tâches et les fichiers correspondants en plusieurs parties. Un sous-graphe est créé pour chaque tâche, et le gestionnaire de flux de travail charge ensuite les tâches dans le système contenant de nombreux nœuds. Nous commençons à traiter les nœuds insérés en parallèle en parcourant les bords de notre graphe et en chargeant en conséquence les informations d'état actuelles dans la fonction Lambda suivante, étape par étape. Le gestionnaire de flux de travail enregistre les données dans le nœud correspondant pour chaque étape du processus et une partie de la tâche et continue jusqu'à ce que toutes les données de la tâche soient traitées. Enfin, nous agrégeons les résultats et les communiquons à nos clients.
Le gestionnaire de flux de travail communique avec les fonctions Lambda via une API REST à l'aide de deux types de requêtes POST :
1) « RequestRequired » est une requête synchrone qui peut gérer une charge utile importante, mais dont le temps de réponse est limité à 30 secondes.
2) « Event » est une requête asynchrone qui fonctionne bien pour envoyer plusieurs tâches parallèles avec une faible charge utile.
Architecture du gestionnaire de flux de travail :
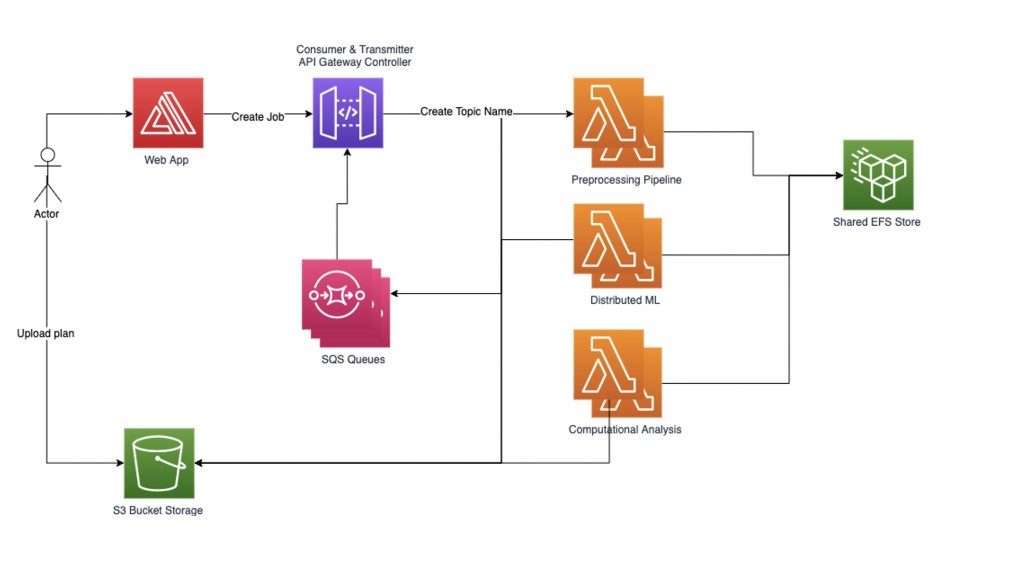
Le gestionnaire de flux de travail définit deux threads auxiliaires : émetteur et consommateur. Le thread émetteur est chargé de vérifier la file d'attente des tâches asynchrones et de gérer les tâches à activer en les envoyant aux fonctions Lambda. Nous pouvons contrôler le nombre de tâches actives simultanées en tant que paramètre afin de contrôler la simultanéité des Lambdas actifs. Lorsqu'une tâche est envoyée pour être traitée par une fonction lambda, la demande contient un nom de file d'attente SQS dans lequel elle doit écrire les réponses. Le thread consommateur est chargé de consommer les messages de la file d'attente SQS et de distribuer les réponses aux tâches entrantes en fonction de leur sujet.
Alors que nous déployons un grand nombre de tâches avec un groupe de travailleurs limité afin de ne pas dépasser les limites de simultanéité, les nœuds qui ne convergent pas ou qui nécessitent un temps de calcul irrégulier peuvent réduire considérablement les performances du système. Pour éviter les interruptions de travail ou les travaux trop longs, un système de trois délais d'expiration est utilisé. Le premier délai d'expiration est le délai lambda de base configuré lors de la configuration d'une fonction Lambda. Ce délai d'expiration devrait être assez long, car il ne devrait potentiellement jamais être atteint. Le deuxième délai d'expiration se situe dans chaque fonction lambda. Lorsque le gestionnaire de fonctions est appelé, il démarre un thread supplémentaire et attend pendant un certain temps. Si le délai d'expiration est atteint, la fonction Lambda renvoie une réponse d'erreur de délai à la file d'attente. Le dernier est un délai d'expiration de la rubrique dans le gestionnaire de flux de travail qui est indépendant des fonctions Lambda et qui est déclenché si plus d'un certain temps s'est écoulé depuis que le dernier message de tâche a été envoyé sous cette rubrique.
Pour obtenir des performances élevées avec une préparation rapide (réduction du temps de démarrage), nous avons utilisé la fonctionnalité Provisioned Concurrency des fonctions Lambda. Nous utilisons également un appel d'initialisation pour préparer la fonction Lambda et les données. Le débit EFS est configuré pour permettre un débit élevé en Mio/s afin d'éliminer les goulots d'étranglement lorsque plusieurs lambdas accèdent aux données stockées sur EFS en parallèle.
Conclusion
Chez Qbiq, nous apportons une intelligence artificielle de pointe, une conception générative et une technologie d'optimisation à la planification immobilière. L'utilisation des conteneurs d'images AWS Lambda nous permet une mise à l'échelle facile à des centaines de processeurs cloud chargés de centaines d'années d'expérience en architecture, de traiter la demande de planification, d'analyser différentes alternatives de mise en page et d'optimiser les résultats.
Nous proposons à nos clients les meilleures alternatives de construction en tenant compte de l'utilisation, des coûts, du temps de construction, de l'efficacité, etc. Pour plus d'informations sur Qbiq, rendez-vous sur notre site Web, qbiq.ai.

AWS Editorial Team
L'équipe de marketing de contenu d'AWS Startups collabore avec des startups de toutes tailles et de tous secteurs pour proposer un contenu exceptionnel qui éduque, divertit et inspire.
Comment a été ce contenu ?