このコンテンツはいかがでしたか?
- 学ぶ
- Qbiq: AWS Lambda コンテナイメージと分散 ML を使用して構築を最適化
Qbiq: AWS Lambda コンテナイメージと分散 ML を使用して構築を最適化
Qbiq チームと Hilal Habashi によるゲスト投稿。AWS スタートアップソリューションアーキテクト
不動産ソフトウェアのスタートアップである Qbiq system は、カスタマイズされた間取り図を大量に生成し、代替案を比較し、結果を最適化する人工知能 (AI) 主導の空間計画設計エンジンを提供しています。スペース使用率、コスト、建設時間、効率、その他さまざまな要因の制約の中で、最適なレイアウト設計の提案を即座に提供します。このような計算負荷の高い計算は、各ジョブリクエストを複数の部分に分割することで、舞台裏で分散的に行われます。具体的には、受け取った各プランはサブプランに分割され、各サブプランは機械学習 (ML) と非線形プログラミングを使用して処理されます。まず、ML モデルを使用してさまざまなレイアウトの選択肢を認識して分析し、次に 2 次方程式を使用して結果を最適化します。
そのサービスの柔軟性と伸縮性から、当社は AWS を選択しました。パイプラインの各ステップで必要とされる処理能力の大きさを考えると、AWS は最適です。実際、主なワークロードとは別に、計画を分割して空間分析と幾何学的分析の両方を必要とする前処理段階と、大量のハイパーパラメータ検索が必要となります。それだけでも簡単なワークロードではありません。また、バックボーンネットワークのカバレッジと応答時間、幅広いサービス、従量課金制のコストモデルにも大きく依存しています。これらすべてが、当社のサービスをスケールし、できるだけ多くのお客様に提供することを可能にしています。
当社のビジネスモデルをサポートするには、クライアントに高速で信頼性の高いサービスとしてのソフトウェア (SaaS) ソリューションを提供する必要がありました。これは、当初考えていたものとはまったく異なっていました。この記事で紹介した分散型ワークロードを構築するプロセスでは、かなりの課題に直面してきました。アーキテクチャが大幅に変更された場合と同様に、新しいテクノロジーの採用と、エンジニアリングチームのオンボーディングとトレーニングの間で、できる限り最高の製品を構築するための良い媒体を見つける必要がありました。
課題
分散 ML アルゴリズムの開発
当社は、Amazon EC2 インスタンスで実行されるクラウドネイティブ SaaS ソリューションとしてスタートしました。限られた実行時間 (5 分未満) で大量の計算を実行するには、ワークロードを小さなセグメントに分割し、サブタスクを分散的に実行する必要がありました。AWS でコンピューティングの水平スケールを開始するにつれ、アルゴリズムを作り直し、実行する必要のあるさまざまなモデルを共有ストレージを使用して保存し、時間の経過とともに受信したジョブのキューを構築する必要もありました。Amazon EFS と Amazon SQS のおかげで、小規模なチームではほとんどまたはまったく労力をかけずに、分散コンピューティングのニーズに対応するサポートインフラストラクチャを迅速に実装し、維持することができました。EFS により、AWS Lambda コンテナ間でストレージを共有し、そのドライブをサブプロセスの共有マウントストレージとして使用できるようになりました。
アルゴリズムのデプロイと保守
独自のツールを使用したり、独自のデプロイスクリプトをゼロから作成したりすることなく、コンテナベースのアプローチでアルゴリズムをデプロイすることが重要でした。従来の Git-Ops アプローチと連携し、コンテナが稼働する環境を抽象化するソリューションを求めていました。コンテナクラスターのプロビジョニングや管理を気にすることなく、需要に応じて利用可能な計算能力を迅速にスケールアウトしたいと考えていました。Amazon EBS では、AWS Fargate や EC2 に基づくソリューションではなく、EFS で Lambda コンテナを使用することにしました。これは、コンテナのオーケストレーションや管理タスクを実行する必要のない、従量課金制モデルの、柔軟性と拡張性に優れたソリューションが必要だったからです。
負荷時のアルゴリズムのテスト
ローカルで実行するかクラウドで実行するかにかかわらず、分散タスクのクラスター全体で計算が正しく実行されることを確認するために、エンドツーエンドのテストを作成する必要がありました。実際に、EC2 でワークロードを実行してオーケストレーションしたところ、追加した分散型ソフトウェアのインスタンスが増えるほど、構成の保守やスタック全体のテストが難しくなることに気付きました。私たちの大まかな目標は、クラウドの忠実度を向上させ、相互のコードベースを持つ 2 セットのセットアップスクリプトを維持することを避けることでした。さらに、大規模な構成を行わずに、高負荷のシナリオで製品をテストできるようにしたいと考えていました。
クラウドアーキテクチャの AWS Lambda コンテナ
最近 Lambda にカスタムコンテナイメージのサポートが追加されたことで、すべての要件が満たされました。アルゴリズムを書いて、それをすべての依存関係とともにコンテナイメージ内にラップするのは簡単でした。その後、ボリュームをマウントし、コンテナイメージに新しいモデルファイルを追加し、ローカルとクラウドの両方でソフトウェアをテストする必要がありました。コンテナを採用したことで、外部の devops ツールではなく、信頼できる GIT ベースのフローのみに依存するようになり、デプロイプロセスが簡素化されました。ついに、コンピュートリソース管理を Lambda 用のメモリと vCPU の設定という単純なタスクに減らすことができました。この作業は、Lambda Power Tuning によってさらに簡単になりました。私たちの環境で Lambda 上で実行されているコンテナイメージは、基本的に当社製品の中核を成しています。Lambda イベントソースと他の AWS サービスとの統合が成熟しているおかげで、EC2 からの移行は簡単になりました。
高レベルの概要:
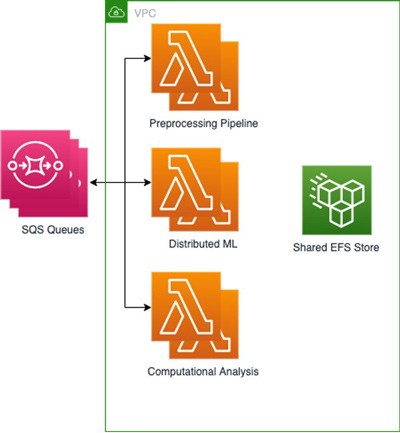
Amazon Elastic Container Registry (Amazon ECR) を使用して 3 つのベースイメージをそれぞれ保存する 3 つの Lambda 関数を構築しました。3 つのベースイメージはプロセスの各部分に 1 つずつ保存され、基本的な依存関係と設定がファイルおよび環境変数として含まれています。次に、EFS を接続して各タスクの出力を保存し、次のタスクですぐに利用できるようにしました。一方、分散型 ML モデルは Amazon S3 に保存されていました。分散型 ML プロセスではタスクがさらに削減されるため、コンテナベースのあらゆるワークロードにマウントしてアクセスできる相互ファイルシステムを持つことが重要でした。この設定により、さまざまな Lambda 関数間で高いスループットと低いオーバーヘッドでファイルを共有できるようになりました。受信ファイルとともに、ジョブに関する情報を含む複数の SQS キューを使用しています。
このアーキテクチャにより、EC2 クラスターでのデプロイと同様の結果と全体的な時間を達成できると同時に、アルゴリズムの実行時間に対してのみ支払いを行うことでコストを削減できます。たとえば、最大 500 回の同時実行で 5,000 個の Lambda 関数を呼び出すと、2 分で 50 件の結果のバッチを生成できます。つまり、バッチあたりの平均コストは 1 USD です。一方、500 個の並列コアを搭載した EC2 クラスターで実行すると、約 2 倍のコストがかかり、クラスターのプロビジョニングが必要になります。最後に、当社の ML エンジニアとデータサイエンティストは、以前のようにクラウド上で稼働するコンテナ化されていない環境向けに独自のセットを記述する代わりに、使い慣れたコンテナベースの環境内で 1 つのテストセットを使用して運用できます。
ワークロード管理
分散した機械学習ワークロードを確実に管理するために、独自のグラフベースのワークフローマネージャーを実装しました。ユーザーが送信するジョブリクエストは、まずファイルをアップロードし、その名前をトピック名として記録します。次に、トピック名ごとにサブグラフを作成します。その下には複数のノード (処理する計算タスクごとに 1 つのノード) を含めることができます。ジョブのサブグラフ内の各ノードには、内部状態表現が含まれています。サブグラフのエッジは、入力と次に実行されるタスクの関数です。
現在のワークロードは 3 段階のプロセスです。つまり、各ジョブを分割した部分の数に 3 を掛けます。前処理パイプラインは、ジョブとそれに対応するファイルを複数の部分に分割します。ジョブごとにサブグラフが作成され、ワークフローマネージャーはジョブを多数のノードを含むシステムにロードします。グラフのエッジをたどり、それに応じて現在の状態情報を次の Lambda 関数にステップごとに読み込むことで、並列に挿入されたノードの処理を開始します。ワークフローマネージャーは、プロセスの各ステップとジョブの一部のデータを対応するノードに記録し、ジョブのすべてのデータが処理されるまで処理を続けます。最後に、結果を集計してお客様に伝えます。
ワークフローマネージャーは、以下の 2 種類の POST リクエストを使用して REST API を通じて Lambda 関数と通信します。
1) 「RequestRequired」は同期リクエストで、大きなペイロードサイズを処理できますが、応答時間は 30 秒に制限されています。
2) 「Event」は非同期リクエストで、小さなペイロードで複数の並列ジョブを送信するのに適しています。
ワークフローマネージャーの設計:
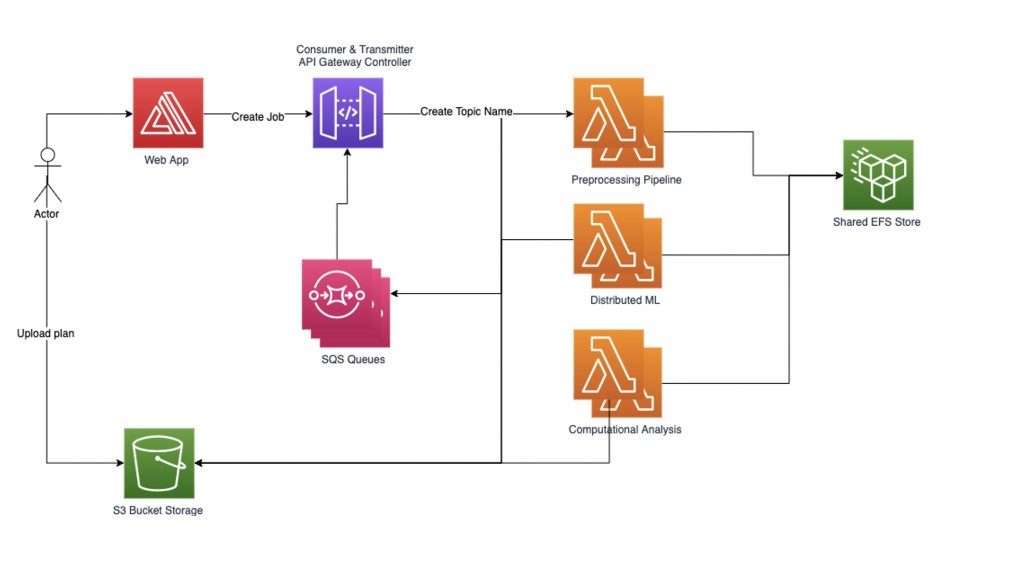
ワークフローマネージャーは、トランスミッターとコンシューマーの 2 つのヘルパースレッドを設定します。トランスミッタースレッドは、非同期ジョブキューをチェックし、どのジョブを Lambda 関数に送信してアクティブにするかを管理します。Lambda のアクティブな同時実行性を制御するために、同時に実行できるアクティブなジョブの数をパラメータとして制御できます。Lambda 関数によって処理されるジョブが送信されると、リクエストにはレスポンスを書き込むべき SQS キュー名が含まれます。コンシューマースレッドは SQS キューからのメッセージを受け取り、受信したジョブのレスポンスをトピックに従って配信します。
同時実行数の制限を超えないようにワーカープールを制限して多数のタスクをデプロイすると、収束しないノードや不規則な計算時間を必要とするノードは、システムパフォーマンスを大幅に低下させる可能性があります。ジョブがハングアップしたり、長すぎたりするのを防ぐため、3 回のタイムアウトシステムが使用されています。1 回目のタイムアウトは、Lambda 関数のセットアップ時に設定される基本的な Lambda タイムアウトです。このタイムアウトには絶対に達しないはずなので、かなり緩いはずです。2 回目のタイムアウトは各 Lambda 関数内にあります。関数ハンドラーが呼び出されると、追加のスレッドを開始し、一定時間待機します。タイムアウトに達すると、Lambda 関数はタイムアウトエラーレスポンスをキューに送り返します。最後は、Lambda 関数に依存しないワークフローマネージャーのトピックタイムアウトで、このトピックで最後のジョブポストが送信されてから一定時間以上経過するとトリガーされます。
高速ウォームアップ (開始時間の短縮) で高いパフォーマンスを実現するために、Lambda 関数のプロビジョニングされた同時実行機能を使用しました。また、初期化呼び出しを使用して Lambda 関数をウォームアップし、データを準備します。EFS スループットは、複数の Lambda が EFS に保存されているデータに並行してアクセスする場合のボトルネックを解消するために MiB/秒が高くなるようにプロビジョニングされています。
まとめ
Qbiq では、最先端の AI、生成デザイン、最適化テクノロジーを不動産計画に取り入れています。AWS Lambda イメージコンテナを使用することで、数百年のアーキテクチャ経験を積んだ数百のクラウドプロセッサに簡単にスケールでき、計画リクエストを処理し、さまざまなレイアウト案を分析し、結果を最適化できます。
使用率、コスト、建設時間、効率などを考慮した最良の構築代替案をお客様に提供します。Qbiq の詳細については、当社のウェブサイト qbiq.ai をご覧ください。

AWS Editorial Team
AWS スタートアップの Content Marketing Team は、教育、エンターテインメント、インスピレーションを提供する優れたコンテンツをもたらすために、あらゆる規模およびあらゆるセクターのスタートアップと連携しています。
このコンテンツはいかがでしたか?