Come ti è sembrato il contenuto?
- Scopri
- Qbiq: utilizzo di immagini di container di AWS Lambda e ML distribuito per ottimizzare la costruzione
Qbiq: utilizzo di immagini di container di AWS Lambda e ML distribuito per ottimizzare la costruzione
Post del team di Qbiq e di Hilal Habashi. Startup Solutions Architect, AWS
La startup di software immobiliare Qbiq System offre un motore di progettazione dello spazio basato sull'intelligenza artificiale (AI) che genera grandi volumi di planimetrie personalizzate, confrontando le alternative e ottimizzando i risultati. Fornisce immediatamente suggerimenti per la progettazione del miglior layout nel rispetto dei vincoli di utilizzo dello spazio, dei costi, dei tempi di costruzione, dell'efficienza e di numerosi altri fattori. Questi calcoli intensivi e non banali vengono eseguiti dietro le quinte in modo distribuito, suddividendo ogni richiesta di lavoro in più parti. In particolare, ogni piano ricevuto viene suddiviso in sottopiani secondari, ciascuno dei quali viene elaborato utilizzando il machine learning (ML) e la programmazione non lineare. Per prima cosa vengono usati modelli ML per riconoscere e analizzare le diverse alternative di layout; poi, i risultati vengono ottimizzati utilizzando equazioni quadratiche.
Abbiamo scelto AWS fin dall'inizio del nostro percorso per la flessibilità e l'elasticità dell'offerta di AWS. È la soluzione perfetta considerando i nostri elevati requisiti in termini di potenza di calcolo in ogni fase della pipeline. In effetti, oltre al nostro carico di lavoro principale, la fase di pre-elaborazione, che divide i piani e richiede analisi spaziali e geometriche, nonché una ricerca approfondita degli iperparametri (un carico di lavoro di per sé non banale), facciamo molto affidamento anche sulla copertura della dorsale di rete e sui tempi di risposta, sull'ampiezza dei servizi e sul modello di costo con pagamento a consumo. Tutto ciò rende scalabile il nostro servizio, consentendoci di offrirlo a quanti più clienti possibile.
Per supportare il nostro modello di business, dovevamo fornire ai nostri clienti una soluzione software-as-a-service (SaaS) veloce e affidabile, che fosse molto diversa da quella che avevamo in mente quando abbiamo iniziato. Abbiamo dovuto affrontare diverse sfide in tutto il processo di creazione del carico di lavoro distribuito presentato in questo post e, come in tutti gli altri casi di modifiche significative a livello architetturale, avevamo bisogno di trovare una via di mezzo tra l'adozione di nuove tecnologie e l'onboarding e la formazione del nostro team di ingegneri per creare il miglior prodotto possibile.
Sfide
Sviluppo di algoritmi di ML distribuito
Inizialmente proponevamo una soluzione SaaS nativa del cloud in esecuzione su istanze Amazon EC2. Per eseguire un gran numero di calcoli in un tempo di esecuzione limitato (inferiore a 5 minuti), abbiamo dovuto dividere il nostro carico di lavoro in piccoli segmenti ed eseguire le attività secondarie in modo distribuito. Quando abbiamo iniziato a ridimensionare orizzontalmente il nostro calcolo su AWS, abbiamo dovuto anche rielaborare i nostri algoritmi, utilizzare uno storage condiviso per archiviare i diversi modelli da eseguire e creare una coda di attività ricevute nel tempo. Grazie ad Amazon EFS e Amazon SQS, siamo stati in grado di implementare e mantenere rapidamente l'infrastruttura di supporto per le nostre esigenze di elaborazione distribuita con uno sforzo minimo o nullo da parte del nostro piccolo team. EFS ci ha permesso di condividere uno storage tra i nostri container AWS Lambda e di usare l'unità come storage montato condiviso per i nostri processi secondari.
Implementazione e manutenzione dei nostri algoritmi
Per noi era importante implementare i nostri algoritmi in un approccio basato su container senza utilizzare strumenti proprietari o dover scrivere i nostri script di implementazione da zero. Volevamo una soluzione che funzionasse con l'approccio Git-ops tradizionale e che distinguesse l'ambiente in cui venivano eseguiti i nostri container. Volevamo rapidamente impiegare la scalabilità orizzontale per la potenza di calcolo disponibile in base alla domanda, senza preoccuparci del provisioning o della gestione di cluster di container. Abbiamo scelto di utilizzare i container Lambda con EFS rispetto a soluzioni basate su AWS Fargate o EC2, con Amazon EBS, poiché volevamo una soluzione altamente flessibile e scalabile con un modello pay-as-you-go che non richiedesse l'esecuzione di attività di orchestrazione e gestione dei container.
Testare i nostri algoritmi sotto carico
Abbiamo dovuto scrivere test end-to-end per verificare che i nostri calcoli fossero eseguiti correttamente nel nostro cluster di attività distribuite indipendentemente dalle sue dimensioni, sia che lo eseguissimo localmente o sul cloud. In realtà, quando abbiamo eseguito e orchestrato il nostro carico di lavoro su EC2, abbiamo notato che più istanze di software distribuito aggiungevamo, più difficile diventava mantenere le configurazioni e testare il nostro stack nel suo complesso. Il nostro obiettivo principale era quello di migliorare la fedeltà del cloud ed evitare di mantenere due set di script di configurazione con una base di codice reciproca. Inoltre, volevamo poter testare il nostro prodotto in scenari di carico elevato, senza configurazioni estese.
Container AWS Lambda nella nostra architettura cloud
Il supporto recentemente aggiunto per le immagini di container personalizzate in Lambda ha completamente soddisfatto le nostre esigenze. È stato facile scrivere i nostri algoritmi e inserirli, insieme a tutte le nostre dipendenze, all'interno di un'immagine di container. Dopo averlo fatto, abbiamo dovuto montare i volumi, aggiungere nuovi file di modello alle nostre immagini di container e testare il software sia in locale che sul cloud. L'adozione dei container ha semplificato il nostro processo di implementazione, consentendoci di basarci esclusivamente sul nostro affidabile flusso basato su Git invece che su strumenti DevOps esterni. Infine, siamo riusciti a ridurre la gestione delle risorse di calcolo a una semplice operazione di configurazione della memoria e della vCPU per la nostra funzione Lambda: un'attività resa ancora più semplice da Lambda Power Tuning. Le immagini di container in esecuzione su Lambda nel nostro ambiente sono il fulcro del nostro prodotto e, grazie alla maturità delle integrazioni dell'origine di evento Lambda con il resto dei servizi AWS, la migrazione da EC2 è stata semplice.
Panoramica di alto livello:
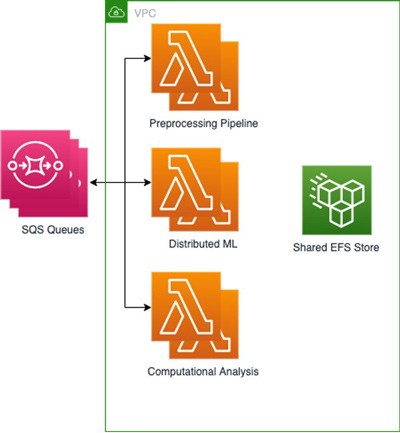
Abbiamo creato 3 funzioni Lambda utilizzando Amazon Elastic Container Registry (Amazon ECR) per archiviare ognuna delle nostre 3 immagini di base, una per ogni parte del processo, con le relative dipendenze e impostazioni di base incluse come file e variabili di ambiente. Abbiamo quindi collegato EFS per archiviare gli output di ogni attività in modo che fossero rapidamente disponibili per le attività seguenti, mentre i nostri modelli di ML distribuiti sono stati archiviati in Amazon S3. Poiché i nostri processi di ML distribuiti riducono ulteriormente le attività, era fondamentale disporre di un file system reciproco che potesse essere montato e accessibile all'interno di qualsiasi carico di lavoro basato su container. Questa configurazione ci ha permesso di condividere file con una velocità di trasmissione effettiva elevata e costi generali ridotti tra le varie funzioni Lambda. Utilizziamo diverse code SQS contenenti informazioni sui lavori, con file in entrata.
Questa architettura ci permette di ottenere risultati e tempi complessivi simili a quelli delle implementazioni su cluster EC2, riducendo al contempo i costi grazie al pagamento del solo tempo di esecuzione degli algoritmi. Ad esempio, siamo in grado di produrre un batch di 50 risultati in 2 minuti richiamando 5.000 funzioni Lambda con un massimo di 500 esecuzioni contemporanee, il che si traduce in un costo medio di 1 USD per batch. L'esecuzione su un cluster EC2 con 500 core paralleli sarebbe invece costata circa il doppio e avrebbe richiesto il provisioning del cluster. Infine, i nostri ingegneri ML e data scientist possono operare all'interno degli ambienti basati su container con cui hanno familiarità, utilizzando un unico set di test invece di scriverne uno specifico per un ambiente non containerizzato in esecuzione sul cloud, come facevano prima.
Gestione del nostro carico di lavoro
Per gestire in modo affidabile il nostro carico di lavoro ML distribuito, abbiamo implementato il nostro gestore di workflow basato su grafici. Ogni richiesta di processo inviata da un utente inizia con il caricamento di un file e la registrazione del suo nome come nome dell'argomento. Quindi creiamo un sotto-grafico per ogni nome di argomento che può contenere più nodi sotto di esso (un nodo per ogni attività computazionale da elaborare). Ogni nodo del sotto-grafico del processo contiene una rappresentazione dello stato interno. Gli archi dei sotto-grafici sono una funzione dell'input e della prossima attività da eseguire.
Il nostro attuale carico di lavoro prevede tre fasi, il che significa che moltiplichiamo per tre il numero di parti in cui abbiamo suddiviso ogni attività. La pipeline di pre-elaborazione scompone le attività e i file corrispondenti in più parti. Per ogni attività viene creato un sotto-grafico e il gestore del flusso di lavoro carica le attività nel sistema, il quale contiene molti nodi. Iniziamo l'elaborazione dei nodi inseriti in parallelo, attraversando gli archi del nostro grafico e caricando di conseguenza le informazioni sullo stato corrente nella funzione Lambda successiva dopo ogni passaggio. Il gestore del flusso di lavoro registra i dati nel nodo corrispondente per ogni fase del processo e parte dell'attività e continua fino a quando tutti i dati dell'attività sono stati elaborati. Infine, aggreghiamo i risultati e li comunichiamo ai nostri clienti.
Il gestore del flusso di lavoro comunica con le funzioni Lambda tramite una REST API utilizzando due tipi di richieste POST:
1) "RequestRequired" è una richiesta sincrona che può gestire payload di grandi dimensioni ma ha un limite di tempo di risposta di 30 secondi.
2) "Event" è una richiesta asincrona e funziona bene per l'invio di più attività parallele con un piccolo payload.
Progettazione del gestore del flusso di lavoro:
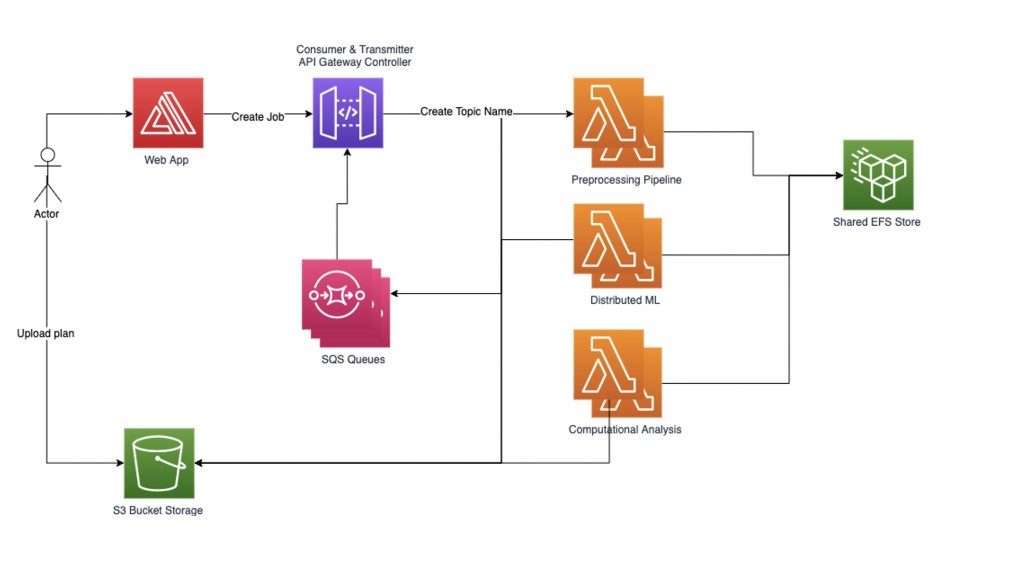
Il gestore del flusso di lavoro imposta due thread di assistenza: transmitter e consumer. Il thread transmitter è responsabile del controllo della coda di processi asincroni e della gestione dei processi da attivare, inviandoli alle funzioni Lambda. Possiamo controllare il numero di processi attivi simultaneamente come parametro, al fine di controllare la concomitanza delle funzioni Lambda attive. Quando un processo viene inviato per essere elaborato da una funzione lambda, la richiesta contiene il nome di una coda SQS in cui scrivere le risposte. Il thread consumer è responsabile del consumo dei messaggi dalla coda SQS e della distribuzione delle risposte ai processi in arrivo in base al loro argomento.
Poiché implementiamo un gran numero di attività con un pool di dipendenti limitato per non superare i limiti di simultaneità, i nodi che non convergono o che richiedono tempi di calcolo irregolari possono ridurre significativamente le prestazioni del sistema. Per prevenire processi sospesi o eccessivamente lunghi, viene utilizzato un sistema di tre timeout. Il primo timeout è il timeout Lambda di base, configurato quando si imposta una funzione Lambda. Questo timeout dovrebbe essere piuttosto ampio, poiché non dovrebbe mai essere raggiungibile. Il secondo timeout è all'interno di ogni funzione Lambda. Quando il gestore della funzione viene richiamato, avvia un thread aggiuntivo e attende per un determinato periodo di tempo. Se il timeout viene raggiunto, la funzione Lambda invia alla coda una risposta di errore di timeout. L'ultimo è un timeout per argomento nel gestore del flusso di lavoro, che non dipende dalle funzioni Lambda e viene attivato se trascorre un certo periodo di tempo dall'invio dell'ultimo post per questo argomento.
Per ottenere prestazioni elevate con un riscaldamento rapido (ossia una riduzione del tempo di avvio), abbiamo utilizzato la funzione Provisioned Concurrency delle funzioni Lambda. Utilizziamo anche una chiamata di inizializzazione per riscaldare la funzione Lambda e preparare i dati. La velocità di trasmissione effettiva di EFS è fornita per consentire un elevato numero di MiB/sec, in modo da eliminare i colli di bottiglia quando più funzioni Lambda accedono in parallelo ai dati archiviati su EFS.
Conclusioni
In Qbiq, mettiamo a disposizione della pianificazione immobiliare tecnologie di intelligenza artificiale, progettazione generativa e ottimizzazione all'avanguardia. L'utilizzo dei container di immagini di AWS Lambda ci consente di raggiungere facilmente centinaia di processori cloud contenenti centinaia di anni di esperienza nel campo dell'architettura, di elaborare le richieste di pianificazione, di analizzare diverse alternative di layout e di ottimizzare i risultati.
Forniamo ai nostri clienti le migliori alternative di costruzione considerando l'utilizzo, i costi, i tempi di costruzione, l'efficienza e altri aspetti. Per ulteriori informazioni su Qbiq, visitate il sito web qbiq.ai.

AWS Editorial Team
Il team Content Marketing di Startup AWS collabora con startup di varie dimensioni e in ogni settore, al fine di sviluppare contenuti eccezionali che siano informativi, coinvolgenti e autentici fonti di ispirazione.
Come ti è sembrato il contenuto?