Como estava esse conteúdo?
- Aprenda
- Qbiq: uso de imagens de contêiner e ML distribuído do AWS Lambda para otimizar a construção
Qbiq: uso de imagens de contêiner e ML distribuído do AWS Lambda para otimizar a construção
Publicação de convidado pela equipe da Qbiq e por Hilal Habashi, arquiteto de soluções para startups da AWS
O sistema da Qbiq, uma startup com softwares para propriedades imobiliárias, oferece um mecanismo de design de planejamento de espaço orientado por inteligência artificial (IA) que gera grandes volumes de plantas baixas personalizadas, compara alternativas e otimiza os resultados. O sistema fornece instantaneamente sugestões para o melhor design de layout dentro das restrições de utilização do espaço, custos, tempo de desenvolvimento, eficiência e uma infinidade de outros fatores. Esses cálculos intensivos de computação não triviais são realizados em segundo plano de maneira distribuída ao dividir cada solicitação de trabalho em várias partes. Em particular, cada planta recebida é dividida em subplantas, e cada uma dessas subplantas é processada usando machine learning (ML) e programação não linear. Primeiro, usamos modelos de ML para reconhecer e analisar as diferentes alternativas de layout e, em seguida, otimizamos os resultados usando equações quadráticas.
Escolhemos a AWS logo no início de nossa jornada pela flexibilidade e elasticidade da oferta da AWS. É a opção mais adequada, considerando nossos requisitos significativos de capacidade computacional em cada etapa do pipeline. De fato, além de nossa workload principal, nossa etapa de processamento prévio, que divide as plantas e requer tanto análises espaciais e geométricas quanto uma pesquisa abrangente de hiperparâmetros, sendo uma workload não trivial por si só, também dependemos fortemente da cobertura de rede de base e dos tempos de resposta, além de sua variedade de serviços e do modelo de custo conforme o uso. Tudo isso nos permite escalar nosso serviço e disponibilizá-lo ao maior número de clientes possível.
Para oferecer suporte ao nosso modelo de negócios, precisávamos fornecer aos nossos clientes uma solução de software como serviço (SaaS) rápida e confiável, o que é bem diferente do que tínhamos em mente quando começamos. Tivemos nossa parcela de desafios ao longo do processo de desenvolvimento da workload distribuída apresentada nesta publicação e, como em qualquer caso de alteração arquitetônica significativa, precisávamos encontrar um meio termo entre a adoção de novas tecnologias e a integração e treinamento de nossa equipe de engenharia para desenvolver o melhor produto possível.
Desafios
Desenvolvimento de algoritmos de ML distribuídos
Começamos como uma solução de SaaS nativa de nuvem que era executada em instâncias do Amazon EC2. Para realizar um grande número de cálculos em um tempo de execução limitado (menos de cinco minutos), tivemos que dividir nossa workload em pequenos segmentos e executar subtarefas de maneira distribuída. Quando começamos a escalar horizontalmente nossa computação na AWS, também tivemos que retrabalhar nossos algoritmos, usar um armazenamento compartilhado para armazenar os diferentes modelos que precisávamos executar e criar uma fila de trabalhos recebidos ao longo do tempo. Graças ao Amazon EFS e ao Amazon SQS, conseguimos implementar e manter com rapidez a infraestrutura de suporte para nossas necessidades de computação distribuída com pouco ou nenhum esforço de nossa pequena equipe. O EFS nos possibilitou compartilhar um armazenamento entre nossos contêineres do AWS Lambda e usar a unidade como um armazenamento montado e compartilhado para nossos subprocessos.
Implantação e manutenção dos algoritmos
Para nós, era importante implantar os algoritmos com uma abordagem baseada em contêineres sem o uso de ferramentas proprietárias ou a necessidade de escrever nossos próprios scripts de implantação do zero. Desejávamos uma solução que funcionasse com a abordagem tradicional do GitOps e substituísse o ambiente em que os contêineres são executados. Desejávamos aumentar a escala horizontalmente da capacidade computacional disponível rapidamente com base na demanda e sem nos preocupar com o provisionamento ou o gerenciamento de clusters de contêineres. Optamos por usar contêineres do Lambda com o EFS em vez de soluções baseadas no AWS Fargate ou no EC2, com o Amazon EBS, pois desejávamos uma solução altamente flexível e escalável com um modelo de pagamento conforme o uso que não exigisse a execução de tarefas de orquestração e de gerenciamento de contêineres.
Teste dos algoritmos no carregamento
Tivemos que escrever testes completos para verificar se os cálculos eram executados corretamente no cluster de tarefas distribuídas, independentemente do tamanho, seja executando-os localmente ou na nuvem. Na realidade, quando executamos e orquestramos a workload no EC2, percebemos que quanto mais instâncias do software distribuído adicionávamos, mais difícil se tornava manter as configurações e testar a pilha de forma completa. Nosso objetivo de alto nível era aprimorar a fidelidade na nuvem e evitar a manutenção de dois conjuntos de scripts de configuração com uma base de código mútua. Além disso, desejávamos testar o produto em cenários de alta carga, sem configurações extensas.
Contêineres do AWS Lambda na arquitetura em nuvem
O suporte adicionado recentemente para imagens de contêiner personalizadas no Lambda preencheu todos os nossos requisitos. Foi fácil escrever os algoritmos e agrupá-los, em conjunto com todas as nossas dependências, em uma imagem de contêiner. Depois disso, tivemos que montar volumes, adicionar novos arquivos de modelos às nossas imagens de contêiner e testar nosso software localmente e na nuvem. A adoção de contêineres simplificou o processo de implantação ao depender somente de nosso fluxo confiável baseado em Git, em vez de ferramentas de DevOps externas. Por fim, conseguimos reduzir o gerenciamento de recursos computacionais a uma simples tarefa de configuração de memória e de vCPU para o Lambda, e essa tarefa ficou ainda mais fácil com o Lambda Power Tuning. As imagens de contêiner em execução no Lambda em nosso ambiente são essencialmente a parte principal do nosso produto e, graças ao estado maduro das integrações de fontes de eventos do Lambda com o restante dos serviços da AWS, a migração do EC2 ocorreu sem complicações.
Visão geral de alto nível:
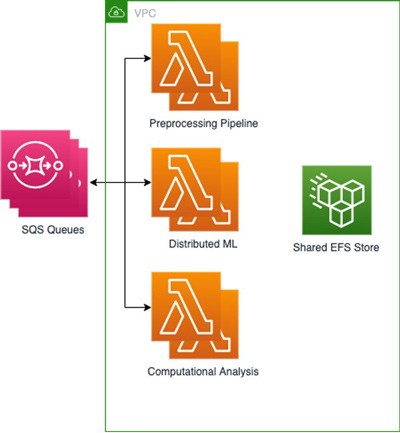
Desenvolvemos três funções do Lambda usando o Amazon Elastic Container Registry (Amazon ECR) para armazenar cada uma de nossas três imagens de base, sendo cada uma desenvolvida para uma parte do processo, com suas dependências e configurações básicas inclusas como arquivos e variáveis de ambiente. Em seguida, conectamos o EFS para armazenar as saídas de cada tarefa com a finalidade de que elas estejam rapidamente disponíveis para as tarefas seguintes, enquanto nossos modelos de ML distribuídos foram armazenados no Amazon S3. Como os processos de ML distribuídos reduzem ainda mais as tarefas, era crucial ter um sistema de arquivos mútuo que pudesse ser montado e acessado em qualquer workload baseada em contêiner. Essa configuração nos permitiu compartilhar arquivos com alto throughput e baixa sobrecarga entre as várias funções do Lambda. Usamos várias filas do SQS contendo informações sobre os trabalhos, com arquivos recebidos.
Essa arquitetura nos permite obter resultados e tempos gerais semelhantes às implantações em clusters do EC2 e, ao mesmo tempo, reduzir os custos ao pagar somente pelo tempo em que os algoritmos estão sendo executados. Por exemplo, podemos produzir um lote de 50 resultados em dois minutos ao invocar 5 mil funções do Lambda com execução simultânea máxima de 500 funções, o que resulta em um custo médio de USD 1 por lote. Por outro lado, executá-lo no cluster do EC2 com 500 núcleos paralelos custaria aproximadamente o dobro e exigiria o provisionamento do cluster. Por fim, nossos engenheiros de ML e cientistas de dados podem operar nos ambientes baseados em contêiner com os quais estão familiarizados enquanto usam um conjunto de testes, em vez de terem que escrever um conjunto exclusivo para um ambiente sem contêiner em execução na nuvem, como faziam antes.
Gerenciamento da workload
Para gerenciar a workload de ML distribuída de forma confiável, implementamos nosso próprio gerenciador de fluxo de trabalho baseado em gráficos. Cada solicitação de trabalho enviada por um usuário começa com um arquivo sendo carregado e seu nome sendo registrado como um Nome do tópico. Em seguida, criamos um subgráfico para cada Nome do tópico que pode conter vários nós sob ele, sendo um nó para cada tarefa computacional a ser processada. Cada nó no subgráfico do trabalho contém uma representação do estado interno. As bordas nos subgráficos correspondem a uma função da entrada e da próxima tarefa a ser executada.
Nossa workload atual é um processo de três etapas, o que significa que multiplicamos o número de partes em que dividimos cada trabalho por três. O pipeline de processamento prévio divide os trabalhos e seus arquivos correspondentes em várias partes. Um subgráfico é criado para cada trabalho e, em seguida, o gerenciador de fluxo de trabalho carrega os trabalhos no sistema que contém diversos nós. Começamos a processar os nós inseridos em paralelo percorrendo as bordas de nosso gráfico e carregando correspondentemente as informações do estado atual na próxima função do Lambda, uma etapa por vez. O gerenciador de fluxo de trabalho registra os dados no nó correspondente para cada etapa do processo e parte do trabalho, e continua a fazer isso até que todos os dados do trabalho sejam processados. Por fim, agregamos os resultados e os comunicamos aos nossos clientes.
O gerenciador de fluxo de trabalho se comunica com as funções do Lambda usando uma API REST com dois tipos de solicitações POST:
1) “RequestRequired” corresponde a uma solicitação síncrona que pode lidar com um grande dimensão de carga útil, mas tem uma limitação de tempo de resposta de 30 segundos.
2) “Event” corresponde a uma solicitação assíncrona e funciona bem para enviar vários trabalhos paralelos com uma pequena carga útil.
Arquitetura do gerenciador de fluxo de trabalho:
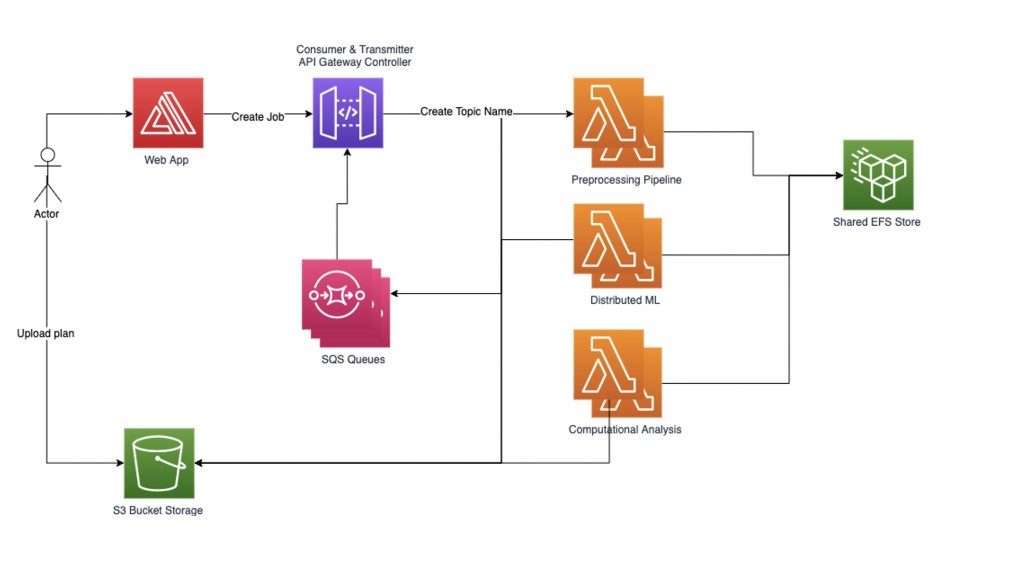
O gerenciador de fluxo de trabalho configura dois threads auxiliares: o transmissor e o consumidor. O thread do transmissor é responsável por verificar a fila de trabalhos assíncronos e gerenciar quais trabalhos ativar, enviando-os para as funções do Lambda. É possível controlar o número de trabalhos simultâneos ativos como um parâmetro para controlar a simultaneidade ativa do Lambda. Quando um trabalho é enviado para ser processado por uma função do Lambda, a solicitação contém um nome de fila do SQS na qual deve gravar as respostas. O thread do consumidor é responsável por consumir as mensagens da fila do SQS e distribuir as respostas do trabalho recebidas de acordo com o tópico.
Como implantamos um grande número de tarefas com um grupo de trabalhado limitado para não exceder os limites de simultaneidade, os nós que não convergem ou requerem tempo computacional irregular podem reduzir significativamente a performance do sistema. Para se proteger contra trabalhos suspensos ou excessivamente longos, um sistema de três tempos limites é usado. O primeiro tempo limite corresponde ao tempo limite básico do Lambda que é configurado ao configurar uma função do Lambda. Esse tempo limite deve ser bastante flexível, pois provavelmente nunca será atingido. O segundo tempo limite está dentro de cada função do Lambda. Quando o manipulador da função é chamado, ele inicia um thread adicional e aguarda um período específico. Se o tempo limite for atingido, a função do Lambda retornará uma resposta de erro de tempo limite para a fila. O último corresponde a um tempo limite de tópico no gerenciador de fluxo de trabalho que é independente para as funções do Lambda e é acionado se exceder um determinado período desde que a última publicação de trabalho foi enviada neste tópico.
Para obter alta performance com aquecimento rápido (diminuição do tempo de início), usamos o recurso de simultaneidade provisionada das funções do Lambda. Além disso, usamos uma chamada de inicialização para aquecer a função do Lambda e preparar os dados. O throughput do EFS é provisionado para permitir alto MiB/s com a finalidade de eliminar gargalos quando diversas funções do Lambda acessam os dados armazenados no EFS em paralelo.
Conclusão
Na Qbiq, trazemos inteligência artificial de ponta, design generativo e tecnologia de otimização para propriedades imobiliárias. O uso de contêineres de imagem do AWS Lambda nos possibilita escalar com facilidade para centenas de processadores de nuvem carregados com centenas de anos de experiência em arquitetura, processar as solicitações de planejamento, analisar diferentes alternativas de layout e otimizar os resultados.
Disponibilizamos aos nossos clientes as melhores alternativas para construção considerando a utilização, os custos, o tempo de desenvolvimento, a eficiência e muito mais. Para obter mais informações sobre a Qbiq, visite nosso site, qbiq.ai.

AWS Editorial Team
A equipe de Marketing de Conteúdo da AWS Startups colabora com startups de todos os tamanhos e setores para oferecer excepcional conteúdo educativo, divertido e inspirador.
Como estava esse conteúdo?