¿Qué le pareció este contenido?
- Aprender
- Qbiq: Uso de imágenes de contenedores de AWS Lambda y ML para optimizar la construcción
Qbiq: Uso de imágenes de contenedores de AWS Lambda y ML para optimizar la construcción
Publicación de invitados: equipo de Qbiq y Hilal Habashi, Startup Solutions Architect de AWS
El sistema de la startup de software inmobiliario Qbiq ofrece un motor de diseño de planificación de espacios impulsado por inteligencia artificial (IA) que genera grandes volúmenes de planos de plantas personalizados, compara alternativas y optimiza los resultados. Proporciona al instante sugerencias para conseguir el mejor diseño teniendo en cuenta las limitaciones de la utilización del espacio, los costos, el tiempo de construcción, la eficiencia y muchos otros factores. Estos cálculos, que no son triviales y hacen un uso intensivo de la computación, se llevan a cabo entre bastidores de forma distribuida y se divide cada solicitud de trabajo en varias partes. Más específicamente, cada plan recibido se divide en subplanos y cada uno de estos subplanos se procesa mediante machine learning (ML) y programación no lineal. En primer lugar, utilizamos modelos de ML para reconocer y analizar las diferentes alternativas de diseño y, a continuación, optimizamos los resultados mediante ecuaciones cuadráticas.
Elegimos AWS desde el principio de nuestro recorrido por la flexibilidad y elasticidad de la oferta de AWS. Es la opción perfecta si tenemos en cuenta nuestros importantes requisitos de potencia de computación en cada etapa de la canalización. De hecho, aparte de nuestra carga de trabajo principal, nuestra fase de preprocesamiento, que divide los planes y requiere tanto un análisis espacial como geométrico y una búsqueda exhaustiva de hiperparámetros, una carga de trabajo nada trivial en sí misma. También dependemos en gran medida de la cobertura y los tiempos de respuesta de su red troncal, la variedad de servicios y el modelo de costos de pago por uso. Todo esto nos permite escalar nuestro servicio y llevarlo a tantos clientes como sea posible.
Para respaldar nuestro modelo de negocio, necesitábamos ofrecer a nuestros clientes una solución de software como servicio (SaaS) rápida y fiable, algo muy diferente de lo que teníamos en mente cuando empezamos. Hemos tenido un buen número de desafíos a lo largo del proceso de creación de la carga de trabajo distribuida que se presenta en esta publicación y, como ocurre con cualquier caso de cambio arquitectónico significativo, necesitábamos encontrar un punto medio entre la adopción de nuevas tecnologías y la incorporación y capacitación de nuestro equipo de ingeniería para crear el mejor producto posible.
Desafíos
Desarrollo de algoritmos de ML distribuido
Empezamos como una solución de SaaS nativa en la nube que se ejecutaba en instancias de Amazon EC2. Para poder llevar a cabo una gran cantidad de computaciones en un tiempo de ejecución limitado (menos de 5 minutos), tuvimos que dividir nuestra carga de trabajo en segmentos pequeños y ejecutar las subtareas de forma distribuida. Cuando empezamos a escalar horizontalmente nuestra computación en AWS, también tuvimos que rediseñar nuestros algoritmos, usar un almacenamiento compartido para almacenar los diferentes modelos que necesitábamos ejecutar y crear una cola de los trabajos recibidos a lo largo del tiempo. Gracias a Amazon EFS y Amazon SQS, pudimos implementar y mantener rápidamente la infraestructura de soporte para nuestras necesidades de computación distribuida con poco o ningún esfuerzo por parte de nuestro pequeño equipo. EFS nos permitió compartir un almacenamiento entre nuestros contenedores de AWS Lambda y utilizar la unidad como almacenamiento montado compartido para nuestros subprocesos.
Implementación y mantenimiento de nuestros algoritmos
Para nosotros era importante implementar nuestros algoritmos en un enfoque basado en contenedores sin usar herramientas patentadas ni tener que escribir nuestros propios scripts de implementación desde cero. Queríamos una solución que funcionara con el enfoque tradicional de GitOps y que eliminara el entorno en el que se ejecutaban nuestros contenedores. Queríamos escalar horizontalmente la potencia de computación disponible con rapidez en función de la demanda y sin preocuparnos por el aprovisionamiento o la administración de ningún clúster de contenedores. Elegimos usar contenedores de Lambda con EFS en lugar de soluciones basadas en AWS Fargate o EC2 con Amazon EBS, ya que buscábamos una solución altamente flexible y escalable con un modelo de pago por uso que no requiriera que lleváramos a cabo tareas de orquestación y administración de contenedores.
Pruebas de nuestros algoritmos en carga
Tuvimos que escribir pruebas integrales para comprobar si nuestros cálculos funcionaban correctamente en nuestro clúster de tareas distribuidas, independientemente de su tamaño, tanto si se ejecutaban de forma local como en la nube. En realidad, cuando ejecutamos y orquestamos nuestra carga de trabajo en EC2, nos dimos cuenta de que cuantas más instancias de software distribuido agregábamos, más difícil resultaba mantener las configuraciones y probar nuestra pila en su conjunto. Nuestro objetivo de alto nivel era mejorar la fidelidad de nuestra nube y evitar tener que mantener dos conjuntos de scripts de configuración con una base de código común. Además, queríamos poder probar nuestro producto en escenarios de carga elevada, sin configuraciones extensas.
Contenedores de AWS Lambda en nuestra arquitectura de nube
La compatibilidad agregada recientemente con imágenes de contenedores personalizadas en Lambda ha cumplido todos nuestros requisitos. Fue fácil escribir nuestros algoritmos y empaquetarlos, junto con todas nuestras dependencias, en una imagen de contenedor. Después de hacerlo, tuvimos que montar volúmenes, agregar nuevos archivos de modelo en nuestras imágenes de contenedores y probar el software tanto localmente como en la nube. La adopción de contenedores ha simplificado nuestro proceso de implementación, ya que dependemos únicamente de nuestro flujo de confianza basado en Git y no de herramientas de DevOps externas. Finalmente, logramos reducir la administración de nuestros recursos de computación a una simple tarea de configuración de la memoria y la vCPU para nuestra instancia de Lambda, una tarea que Lambda Power Tuning facilitó todavía más. Las imágenes de contenedores que se ejecutan en Lambda en nuestro entorno son básicamente el núcleo de nuestro producto y, gracias al estado avanzado de las integraciones de los orígenes de eventos de Lambda con el resto de los servicios de AWS, la migración desde EC2 fue sencilla.
Descripción general de alto nivel:
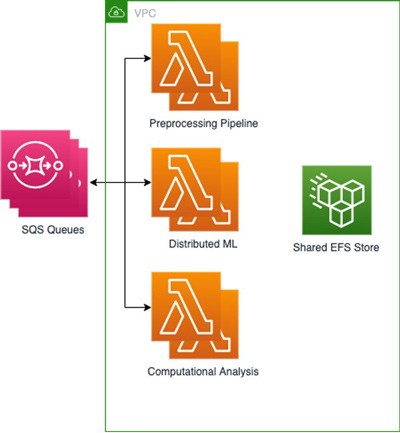
Hemos creado 3 funciones de Lambda con Amazon Elastic Container Registry (Amazon ECR) para almacenar nuestras 3 imágenes base; una para cada parte del proceso, con sus dependencias y configuraciones básicas incluidas como archivos y variables de entorno. A continuación, conectamos EFS para almacenar los resultados de cada tarea, de modo que estuvieran disponibles rápidamente para las siguientes tareas, mientras que nuestros modelos de ML distribuido se almacenaban en Amazon S3. Dado que nuestros procesos de ML distribuido reducían aún más las tareas, era fundamental contar con un sistema de archivos común que se pudiera montar y al que se pudiera acceder desde cualquier carga de trabajo basada en contenedores. Esta configuración nos permitió compartir archivos con un rendimiento alto y una sobrecarga baja entre las distintas funciones de Lambda. Usamos varias colas de SQS con información sobre los trabajos con los archivos entrantes.
Esta arquitectura nos permite lograr un resultado y un tiempo total similares a los de las implementaciones en un clúster de EC2 y, al mismo tiempo, reducir los costos al pagar solo por el tiempo que los algoritmos están en ejecución. Por ejemplo, podemos generar un lote de 50 resultados en 2 minutos mediante la invocación de 5000 funciones de Lambda con una ejecución simultánea máxima de 500, lo que supone un costo promedio de 1 USD por lote. Por otro lado, la ejecución en un clúster de EC2 con 500 núcleos paralelos habría costado aproximadamente el doble y habría que aprovisionar el clúster. Por último, nuestros ingenieros de ML y nuestros científicos de datos pueden trabajar en los entornos basados en contenedores con los que están familiarizados y utilizar un conjunto de pruebas en lugar de escribir un conjunto único para un entorno no incluido en contenedores que se ejecuta en la nube, como hacían antes.
Administración de nuestra carga de trabajo
Para administrar nuestra carga de trabajo de ML distribuido de forma fiable, implementamos nuestro propio administrador de flujos de trabajo basado en gráficos. Cada solicitud de trabajo que envía un usuario comienza con la carga de un archivo y con el registro de su nombre como nombre de tema. A continuación, creamos un subgráfico para cada nombre de tema que puede contener varios nodos: un nodo para cada tarea de computación que se va a procesar. Cada nodo del subgráfico del trabajo contiene una representación de estado interna. Los bordes de los subgráficos son una función de la entrada y la siguiente tarea que se va a ejecutar.
Nuestra carga de trabajo actual es un proceso de 3 pasos, lo que significa que multiplicamos por tres el número de partes en las que dividimos cada trabajo. La canalización de preprocesamiento divide los trabajos y sus archivos correspondientes en varias partes. Se crea un subgráfico para cada trabajo y, a continuación, el administrador de flujos de trabajo carga los trabajos en el sistema que contiene muchos nodos. Empezamos a procesar los nodos insertados en paralelo; para ello, recorremos los bordes del gráfico y cargamos como corresponde la información del estado actual en la siguiente función de Lambda, paso a paso. El administrador de flujos de trabajo registra los datos en el nodo correspondiente para cada paso del proceso y parte del trabajo y continúa hasta que se procesan todos los datos del trabajo. Por último, agregamos los resultados y se los comunicamos a nuestros clientes.
El administrador de flujos de trabajo se comunica con las funciones de Lambda a través de una API de REST con dos tipos de solicitudes POST:
1) “RequestRequired” es una solicitud síncrona que puede gestionar una carga útil de gran tamaño, pero tiene un límite de tiempo de respuesta de 30 segundos.
2) “Event” es una solicitud asíncrona y funciona bien para enviar múltiples trabajos paralelos con una carga útil pequeña.
Diseño de la arquitectura del administrador de flujos de trabajo:
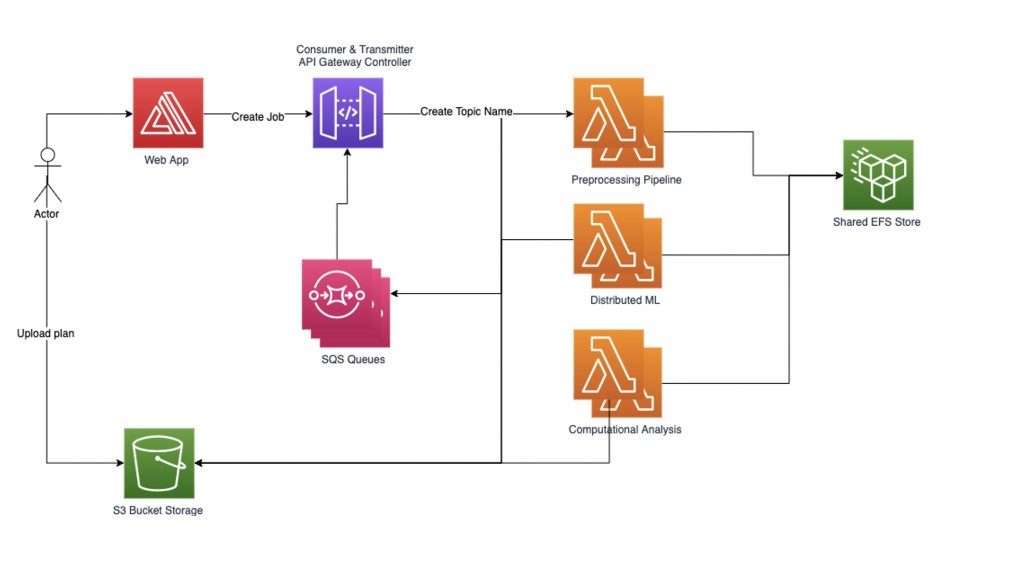
El administrador de flujos de trabajo configura dos subprocesos auxiliares: transmisor y consumidor. El subproceso del transmisor se encarga de comprobar la cola de trabajos asíncronos y de administrar los trabajos que se van a activar y, para ello, los envía a las funciones de Lambda. Podemos controlar el número de trabajos activos simultáneos como parámetro para controlar la simultaneidad de las funciones de Lambda activas. Cuando se envía un trabajo para que lo procese una función de Lambda, la solicitud contiene un nombre de cola de SQS en el que se deben escribir las respuestas. El subproceso del consumidor se encarga de consumir los mensajes de la cola de SQS y de distribuir las respuestas de los trabajos entrantes según su tema.
Al implementar una gran cantidad de tareas con un grupo de trabajadores limitado para no superar los límites de simultaneidad, los nodos que no convergen o que requieren un tiempo de computación irregular pueden reducir significativamente el rendimiento del sistema. Para evitar trabajos suspendidos o demasiado largos, se utiliza un sistema de tres tiempos de espera. El primer tiempo de espera es el tiempo de espera básico de Lambda que se establece al configurar una función de Lambda. Este tiempo de espera debería ser bastante flexible, ya que es posible que nunca se alcance. El segundo tiempo de espera está dentro de cada función de Lambda. Cuando se llama al controlador de funciones, se inicia un subproceso adicional y se espera una cantidad de tiempo específica. Si se alcanza el tiempo de espera, la función de Lambda devuelve a la cola una respuesta de error de tiempo de espera. El último es un tiempo de espera de tema en el administrador de flujos de trabajo que es independiente de las funciones de Lambda y que se desencadena si ha transcurrido más de una determinada cantidad de tiempo desde que se envió la última solicitud POST del trabajo en este tema.
Para lograr un rendimiento alto con un calentamiento rápido (reducir el tiempo de inicio), utilizamos la característica de simultaneidad aprovisionada de las funciones de Lambda. También utilizamos una llamada de inicialización para calentar la función de Lambda y preparar los datos. El rendimiento de EFS se aprovisiona para permitir valores elevados de MiB por segundo a fin de eliminar los cuellos de botella cuando varias funciones de Lambda acceden en paralelo a los datos almacenados en EFS.
Conclusión
En Qbiq, aportamos IA de vanguardia, diseño generativo y tecnología de optimización a la planificación inmobiliaria. El uso de los contenedores de imágenes de AWS Lambda nos permite escalar fácilmente a cientos de procesadores en la nube con cientos de años de experiencia en arquitectura, procesar la solicitud de planificación, analizar diferentes alternativas de diseño y optimizar los resultados.
Brindamos a nuestros clientes las mejores alternativas de construcción teniendo en cuenta la utilización, los costos, el tiempo de construcción, la eficiencia, entre muchos otros factores. Para obtener más información sobre Qbiq, visite nuestro sitio web, qbiq.ai.

AWS Editorial Team
El equipo de marketing de contenido para startups de AWS colabora con startups de todos los tamaños y sectores para ofrecer contenido excepcional que eduque, entretenga e inspire.
¿Qué le pareció este contenido?