Wie war dieser Inhalt?
- Lernen
- Qbiq: Verwendung von AWS-Lambda-Container-Images und Distributed ML zur Optimierung der Konstruktion
Qbiq: Verwendung von AWS-Lambda-Container-Images und Distributed ML zur Optimierung der Konstruktion
Gastbeitrag von Qbiq Team und Hilal Habashi. Startup Solutions Architect, AWS
Das Immobilien-Software-Startup Qbiq System bietet eine auf künstlicher Intelligenz (KI) basierende Designengine für Raumplanung, die große Mengen an maßgeschneiderten Grundrissen generiert, Alternativen vergleicht und die Ergebnisse optimiert. Es liefert sofort Vorschläge für das beste Layoutdesign unter Berücksichtigung der Einschränkungen von Raumnutzung, Kosten, Bauzeit, Effizienz und einer Vielzahl anderer Faktoren. Diese nicht trivialen rechenintensiven Berechnungen werden im Hintergrund verteilt durchgeführt, indem jede Auftragsanfrage in mehrere Teile aufgeteilt wird. Genauer gesagt wird jeder eingegangene Plan in Unterpläne aufgeteilt, und jeder dieser Unterpläne wird mithilfe von Machine Learning (ML) und nichtlinearer Programmierung verarbeitet. Zunächst verwenden wir ML-Modelle, um die verschiedenen Layoutalternativen zu erkennen und zu analysieren, und dann optimieren wir die Ergebnisse mithilfe quadratischer Gleichungen.
Wir haben uns gleich zu Beginn unserer Reise für AWS entschieden, weil das Angebot von AWS flexibel und elastisch ist. Angesichts unseres hohen Rechenleistungsbedarfs in jedem Schritt der Pipeline ist es eine perfekte Lösung. Abgesehen von unserem Haupt-Workload, unserer Vorverarbeitungsphase, die die Pläne unterteilt und sowohl räumliche als auch geometrische Analysen sowie eine umfangreiche Suche nach Hyperparametern erforder, ein nicht trivialer Workload an sich. Außerdem verlassen wir uns in hohem Maße auf die Abdeckung des Backbone-Netzes und die Reaktionszeiten, die Bandbreite der Services und das Pay-as-you-go-Kostenmodell. All dies ermöglicht es uns, unseren Service zu skalieren und ihn so vielen Kunden wie möglich zur Verfügung zu stellen.
Um unser Geschäftsmodell zu unterstützen, mussten wir unseren Kunden eine schnelle und zuverlässige Software-as-a-Service (SaaS)-Lösung bieten, die sich deutlich von dem unterscheidet, was wir zu Beginn im Sinn hatten. Während des gesamten Prozesses der Erstellung der in diesem Beitrag vorgestellten verteilten Workloads standen wir vor einer Reihe von Herausforderungen, und wie bei jedem Fall bedeutender architektonischer Änderungen mussten wir einen guten Mittelweg zwischen der Einführung neuer Technologien und der Einführung und Schulung unseres Entwicklungsteams finden, um das bestmögliche Produkt zu entwickeln.
Herausforderungen
Entwicklung verteilter ML-Algorithmen
Wir haben als cloudnative SaaS-Lösung begonnen, die auf Amazon-EC2-Instances läuft. Um eine große Anzahl von Berechnungen in einer begrenzten Laufzeit (unter 5 Minuten) durchführen zu können, mussten wir unsere Workloads in winzige Segmente aufteilen und Unteraufgaben verteilt ausführen. Als wir anfingen, unsere Rechenleistung auf AWS horizontal zu skalieren, mussten wir auch unsere Algorithmen überarbeiten, einen gemeinsamen Speicher verwenden, um die verschiedenen Modelle zu speichern, die wir ausführen müssen, und eine Warteschlange mit Aufträgen erstellen, die im Laufe der Zeit empfangen wurden. Dank Amazon EFS und Amazon SQS waren wir in der Lage, die unterstützende Infrastruktur für unsere verteilten Rechenanforderungen schnell zu implementieren und zu warten, so dass unser kleines Team nur wenig bis gar keinen Aufwand betreiben musste. EFS ermöglichte es uns, einen Speicher zwischen unseren AWS-Lambda-Containern gemeinsam zu nutzen und das Laufwerk als gemeinsam genutzten bereitgestellten Speicher für unsere Unterprozesse zu verwenden.
Einsatz und Wartung unserer Algorithmen
Für uns war es wichtig, unsere Algorithmen in einem containerbasierten Ansatz bereitzustellen, ohne proprietäre Tools zu verwenden oder unsere eigenen Deployment-Skripte von Grund auf neu schreiben zu müssen. Wir wollten eine Lösung, die mit dem traditionellen Git-Ops-Ansatz funktioniert und die Umgebung, in der unsere Container laufen, abstrahiert. Wir wollten die verfügbare Rechenleistung schnell und bedarfsgerecht skalieren, ohne uns Gedanken über die Bereitstellung oder Verwaltung von Container-Clustern machen zu müssen. Wir entschieden uns für Lambda-Container mit EFS gegenüber Lösungen, die auf AWS Fargate oder EC2 mit Amazon EBS basieren, da wir eine hochflexible und skalierbare Lösung mit einem Pay-as-you-go-Modell wollten, bei dem wir keine Aufgaben zur Orchestrierung und Verwaltung von Containern durchführen mussten.
Testen unserer Algorithmen unter Last
Wir mussten umfassende Tests schreiben, um zu überprüfen, ob unsere Berechnungen in unserem Cluster verteilter Aufgaben korrekt ausgeführt wurden, unabhängig von seiner Größe, unabhängig davon, ob er lokal oder in der Cloud ausgeführt wurde. Tatsächlich stellten wir bei der Ausführung und Orchestrierung unserer Workloads auf EC2 fest, dass es umso schwieriger wurde, die Konfigurationen zu verwalten und unseren Stack als Ganzes zu testen, je mehr Instances verteilter Software wir hinzufügten. Unser übergeordnetes Ziel bestand darin, unsere Cloud-Zuverlässigkeit zu verbessern und zu vermeiden, dass zwei Sätze von Setup-Skripten mit einer gemeinsamen Codebasis verwaltet werden mussten. Darüber hinaus wollten wir unser Produkt in Szenarien mit hoher Auslastung ohne umfangreiche Konfigurationen testen können.
AWS-Lambda-Container in unserer Cloud-Architektur
Die kürzlich hinzugefügte Unterstützung für benutzerdefinierte Container-Images in Lambda hat für uns alle Kriterien erfüllt. Es war einfach, unsere Algorithmen zu schreiben und sie zusammen mit all unseren Abhängigkeiten in ein Container-Image zu packen. Danach mussten wir Volumes mounten, unseren Container-Images neue Modelldateien hinzufügen und unsere Software sowohl lokal als auch in der Cloud testen. Die Einführung von Containern hat unseren Bereitstellungsprozess vereinfacht, da wir uns ausschließlich auf unseren vertrauenswürdigen Git-basierten Ablauf verlassen haben und nicht auf externe DevOps-Tools. Schließlich ist es uns gelungen, unser Rechenressourcenmanagement auf eine einfache Aufgabe der Konfiguration von Speicher und vCPU für unser Lambda zu reduzieren, eine Aufgabe, die durch Lambda Power Tuning noch einfacher wurde. Die Container-Images, die in unserer Umgebung auf Lambda laufen, sind im Grunde das Herzstück unseres Produkts, und dank der ausgereiften Integration von Lambda-Ereignisquellen mit den übrigen AWS-Services verlief die Migration von EC2 mühelos.
Überblick auf übergeordnetem Niveau:
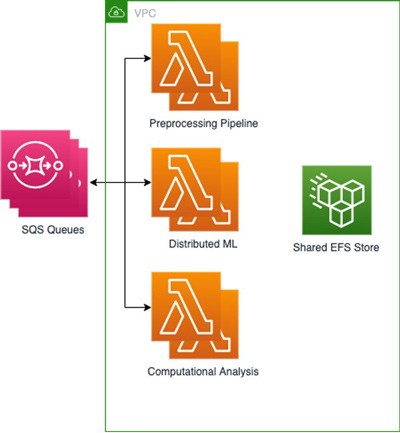
Wir haben drei Lambda-Funktionen mithilfe von Amazon Elastic Container Registry (Amazon ECR) erstellt, um jedes unserer 3 Basis-Images zu speichern; eine für jeden Teil des Prozesses, wobei die grundlegenden Abhängigkeiten und Einstellungen als Dateien und Umgebungsvariablen enthalten sind. Anschließend haben wir EFS verbunden, um die Ausgaben jeder Aufgabe zu speichern, sodass sie für die folgenden Aufgaben schnell verfügbar sind, während unsere verteilten ML-Modelle in Amazon S3 gespeichert wurden. Da unsere verteilten ML-Prozesse die Aufgaben noch weiter reduzieren, war es von entscheidender Bedeutung, ein gemeinsames Dateisystem zu haben, das innerhalb jedes containerbasierten Workloads bereitgestellt und abgerufen werden kann. Dieses Setup ermöglichte es uns, Dateien mit hohem Durchsatz und geringem Overhead zwischen den verschiedenen Lambda-Funktionen gemeinsam zu nutzen. Wir verwenden mehrere SQS-Warteschlangen, die Informationen über die Aufträge und eingehende Dateien enthalten.
Diese Architektur ermöglicht es uns, ähnliche Ergebnisse und eine ähnliche Gesamtzeit wie Bereitstellungen über einen EC2-Cluster zu erzielen und gleichzeitig die Kosten zu senken, indem wir nur für die Zeit bezahlen, in der die Algorithmen ausgeführt werden. Wir sind beispielsweise in der Lage, einen Stapel von 50 Ergebnissen in 2 Minuten zu erzeugen, indem wir 5 000 Lambda-Funktionen aufrufen und dabei maximal 500 gleichzeitig ausgeführt werden, was zu durchschnittlichen Kosten von 1 USD pro Batch führt. Andererseits hätte die Ausführung auf einem EC2-Cluster mit 500 parallelen Kernen etwa doppelt so viel gekostet und die Bereitstellung des Clusters erforderlich gemacht. Schließlich können unsere ML-Techniker und Datenwissenschaftler in den Container-basierten Umgebungen arbeiten, mit denen sie vertraut sind, und gleichzeitig einen Satz von Tests verwenden, anstatt wie bisher einen eindeutigen Satz für eine nicht containerisierte Umgebung zu schreiben, die in der Cloud läuft.
Verwaltung unseres Workloads
Um unseren verteilten ML-Workload zuverlässig zu verwalten, haben wir unseren eigenen graphbasierten Workflow-Manager implementiert. Jede von einem Benutzer gesendete Auftragsanfrage beginnt damit, dass eine Datei hochgeladen und ihr Name als Themenname aufgezeichnet wird. Anschließend erstellen wir für jeden Themennamen ein Unterdiagramm, das mehrere Knoten darunter enthalten kann, einen Knoten für jede zu verarbeitende Rechenaufgabe. Jeder Knoten im Untergraphen des Auftrags enthält eine interne Statusdarstellung. Die Kanten in den Unterdiagrammen hängen von der Eingabe und der nächsten auszuführenden Aufgabe ab.
Unser derzeitiger Arbeitsaufwand besteht aus drei Schritten, was bedeutet, dass wir die Anzahl der Teile, in die wir jeden Job aufgeteilt haben, mit drei multiplizieren. Die Vorverarbeitungspipeline unterteilt die Jobs und die entsprechenden Dateien in mehrere Teile. Für jeden Job wird ein Unterdiagramm erstellt, und der Workflow-Manager lädt die Jobs dann in das System, das viele Knoten enthält. Wir beginnen mit der Verarbeitung der parallel eingefügten Knoten, indem wir die Kanten unseres Diagramms durchqueren und entsprechend die aktuellen Statusinformationen Schritt für Schritt in die nächste Lambda-Funktion laden. Der Workflow-Manager zeichnet die Daten im entsprechenden Knoten für jeden Schritt des Prozesses und jeden Teil des Jobs auf und fährt fort, bis alle Daten für den Job verarbeitet sind. Schließlich aggregieren wir die Ergebnisse und teilen sie unseren Kunden mit.
Der Workflow-Manager kommuniziert mit den Lambda-Funktionen über eine REST-API und verwendet dabei zwei Arten von POST-Anfragen:
1) `RequestRequired` ist eine synchrone Anfrage, die große Nutzlastgrößen verarbeiten kann, aber eine Antwortzeitbeschränkung von 30 Sekunden hat.
2) `Event` ist eine asynchrone Anfrage und eignet sich gut zum Senden mehrerer paralleler Aufträge mit einer kleinen Nutzlast.
Architektur des Workflow-Managers:
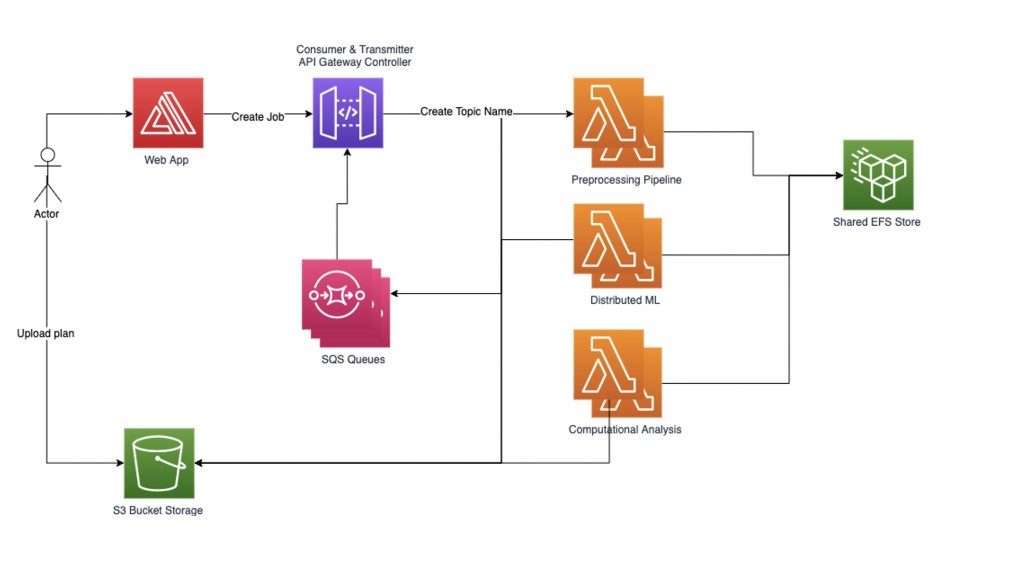
Der Workflow-Manager richtet zwei Hilfs-Threads ein: Transmitter und Consumer. Der Transmitter-Thread ist dafür verantwortlich, die Warteschlange für asynchrone Aufträge zu überprüfen und zu verwalten, welche Aufträge aktiviert werden sollen, indem er sie an die Lambda-Funktionen sendet. Wir können die Anzahl der gleichzeitig aktiven Aufträge als Parameter steuern, um die Parallelität der aktiven Lambdas zu kontrollieren. Wenn ein Auftrag zur Verarbeitung durch eine Lambda-Funktion gesendet wird, enthält die Anfrage einen SQS-Warteschlangennamen, in den die Antworten geschrieben werden sollen. Der Consumer-Thread ist dafür verantwortlich, die Nachrichten aus der SQS-Warteschlange zu verarbeiten und eingehende Auftragsantworten entsprechend ihrem Thema zu verteilen.
Da wir eine große Anzahl von Aufgaben mit einem begrenzten Workerpool bereitstellen, um die Parallelitätsgrenzen nicht zu überschreiten, können Knoten, die nicht konvergieren oder unregelmäßige Rechenzeit benötigen, die Systemleistung erheblich reduzieren. Zum Schutz vor hängenden oder zu langen Aufträgen wird ein System mit drei Timeouts verwendet. Das erste Timeout ist das grundlegende Lambda-Timeout, das beim Einrichten einer Lambda-Funktion konfiguriert wird. Dieses Timeout sollte ziemlich locker sein, da es möglicherweise nie erreicht werden sollte. Das zweite Timeout ist innerhalb jeder Lambda-Funktion. Wenn der Funktionshandler aufgerufen wird, startet er einen zusätzlichen Thread und wartet eine bestimmte Zeit. Wenn das Timeout erreicht ist, sendet die Lambda-Funktion eine Timeout-Fehlerantwort an die Warteschlange zurück. Das letzte ist ein Thema-Timeout im Workflow-Manager, das unabhängig von Lambda-Funktionen ist und ausgelöst wird, wenn seit dem Senden des letzten Auftrags-Posts unter diesem Thema mehr als eine bestimmte Zeit vergangen ist.
Um eine hohe Leistung bei schnellem Aufwärmen (kürzere Startzeit) zu erreichen, haben wir das Feature Provisioned Concurrency der Lambda-Funktionen verwendet. Wir verwenden auch einen Initialisierungsaufruf, um die Lambda-Funktion aufzuwärmen und die Daten vorzubereiten. Der EFS-Durchsatz wird bereitgestellt, um hohe MiB/Sek zu ermöglichen und Engpässe zu vermeiden, wenn mehrere Lambdas parallel auf die in EFS gespeicherten Daten zugreifen.
Fazit
Bei Qbiq bringen wir modernste KI-, generatives Design- und Optimierungstechnologie in die Immobilienplanung ein. Die Verwendung von AWS-Lambda-Image-Containern ermöglicht es uns, problemlos auf Hunderte von Cloud-Prozessoren mit Hunderten von Jahren Architekturerfahrung zu skalieren, die Planungsanfrage zu bearbeiten, verschiedene Layoutalternativen zu analysieren und die Ergebnisse zu optimieren.
Wir bieten unseren Kunden die besten Baualternativen unter Berücksichtigung von Auslastung, Kosten, Bauzeit, Effizienz und mehr. Weitere Informationen zu Qbiq finden Sie auf unserer Website qbiq.ai.

AWS Editorial Team
Das Content Marketing Team von AWS Startups arbeitet mit Startups aller Größen und Branchen zusammen, um außergewöhnliche Inhalte bereitzustellen, die informieren, unterhalten und inspirieren.
Wie war dieser Inhalt?