- Amazon 建置者資料中心
- 在分散式系統中避免回復
在分散式系統中避免回復
架構 | 等級 300
簡介
嚴重失敗導致服務無法產出實用的結果。例如,在電子商務網站中,如果產品資訊的資料庫查詢失敗,網站就無法成功顯示產品頁。Amazon 服務必須處理大部分嚴重失敗,才可保持可靠性。處理嚴重失敗的策略分成四大類別:
-
重試:立即或延遲後再次執行失敗的活動。
-
主動重試:並行多次執行活動,並利用第一個活動完成。
-
容錯移轉:針對不同端點副本再次執行活動,或者最好執行多個並行活動複本,以提高至少其中一個成功的機率。
-
備用:使用不同的機制來實現相同的結果。
本文會說明回復策略,以及 Amazon 幾乎從來不使用的原因。您可能對此感到驚訝。畢竟工程師的設計起點,經常來自於真實世界。在真實世界中,必須事前規劃回復策略並在需要時使用。就以機場的顯示幕故障為例。此時必須採取應急計畫(例如人工在白板上撰寫班機資訊),因為乘客還是得找到登機門。但大家想想這套應急計畫有多蹩腳:白板閱讀不易、難以提供最新資訊,以及人工撰寫資訊錯誤的風險。白板回復策略有其必要,但夾雜著各種問題。
在分散式系統的世界裡,回復策略屬於最難處理的挑戰,尤其對時間緊迫的服務而言。更困難的是,劣質回復策略帶來的惡果,可能需要更長的時間(甚至數年)才能擺脫,而回復策略的優劣之別相當細微。本文會著重於何以回復策略造成的問題,超過它能夠修正的問題。我們會舉例說明回復策略在 Amazon 造成哪些問題。最後,我們會討論 Amazon 在回復策略以外採用的替代方法。
服務回復策略的分析不是三言兩語可論斷,且在分散式系統中的漣漪效應難以預料,所以,讓我們先從單機應用程式的回復策略開始談起。
單機回復
想想下列 C 語言程式碼片段,這是許多應用程式常用來處理記憶體分配失敗的型態。這段程式碼使用 malloc() 函式分配記憶體,然後將影像緩衝區複製到該記憶體中,同時執行某種轉換:
pixel_ranges = malloc(image_size); // allocates memory
if (pixel_ranges == NULL) {
// On error, malloc returns NULL
exit(1);
}
for (i = 0; i < image_size; i++) {
pixel_ranges[i] = xform(original_image[i]);
}單機備援,(續)
這段程式碼無法巧妙回復 malloc 失敗的案例。實際上,叫用 malloc 很少失敗,因此開發人員在程式碼中常忽略此可能性。為什麼此策略如此普遍? 理由是在單機上如果 malloc 失敗,機器的記憶體可能用盡。因此,一個 malloc 叫用失敗可能不是最主要的問題,真正的大問題在於機器可能即將當機。多數時候在單機上,這樣的說法聽起來很合理。許多應用程式並沒有重要到值得耗費心力處理棘手的問題。但是,如果您就是想要處理這項錯誤,該怎麼辦? 想在此情境下採取實際有用的作法絕非易事。假設我們實作第二種方法並命名為 malloc2,以不同方式分配記憶體,並且在預設的 malloc 實作失敗時叫用 malloc2:
pixel_ranges = malloc(image_size);
if (pixel_ranges == NULL) {
pixel_ranges = malloc2(image_size);
}單機備援,(續)
乍看之下這段程式碼似乎可以運作,實際上卻潛藏問題,其中有些問題更是不易察覺。首先,後退邏輯很難測試。我們可以攔截 malloc 的叫用並插入失敗,但可能無法準確模擬實際執行環境中會發生的情況。在實際執行環境中,如果 malloc 失敗,機器的記憶體很有可能用盡或過低。這些牽連廣泛的記憶體問題該如何模擬? 即使您設法創造低記憶體環境執行測試(例如在 Docker 容器中),低記憶體條件又該如何計時,使其與 malloc2 回復程式碼的執行狀況吻合?
另一個問題是後備本身可能會失敗。先前的回復程式碼未能處理 malloc2 失敗,因此程式無法帶來您預想的效益。回復策略有機會降低完全失敗的可能性,但無法做到滴水不漏。在 Amazon,我們發現投入工程資源提高主要(非回復)程式碼的可靠性,相較於投資不常使用的回復策略,更能提高成功率。
此外,如果可用性是我們的首要任務,則後備策略可能不值得冒險。如果 malloc2 成功的可能性比較高,何必為了 malloc 傷神? 從邏輯上看,malloc2 勢必得付出一些代價,來交換更高的可用性。可能是提高分配記憶體的延遲,但換取較大的 SSD 型態儲存。不過這就衍生出一個問題:為什麼 malloc2 付出此代價沒有關係? 讓我們想想採取此回復策略後,可能發生的一系列事件。首先,客戶使用應用程式。malloc2 突然(因為 malloc 失敗)開始發揮作用,因此拖慢應用程式的速度。這是不好的影響:拖慢速度真的沒關係嗎? 問題還不是到此為止。想想機器的記憶體很可能用盡(或速度非常慢)。使得客戶現在面臨兩個問題(應用程式速度變慢和機器速度變慢),而不是一個問題。切換為 malloc2 的副作用,甚至可能讓整體問題加劇。舉例來說,其他子系統也可能爭奪同一個 SSD 型態儲存。
後備邏輯也可以在系統上產生不可預測的負載。就算撰寫錯誤訊息及堆疊追蹤記錄等簡單常見的邏輯表面上無害,但如果突然發生變化造成錯誤高頻率發生,佔用龐大 CPU 資源的應用程式就可能突然轉化成佔用龐大 I/O 資源的應用程式。此外,如果磁碟機並未佈建為能夠以該速率處理寫入,或者可儲存該資料量,就可能拖慢應用程式或使其損毀。
後備策略不僅可能會使問題更糟,這可能會發生為潛在錯誤。 常見的狀況是開發出在實際執行環境中很少觸發的回復策略。甚至可能經過好幾年的時間,才有一台客戶的機器真的在恰到好處的時刻用盡記憶體,從而觸發先前提到的 malloc2 回復特定程式碼行。如果回復邏輯中的錯誤或某種副作用導致整體問題加劇,此時撰寫程式碼的工程師可能早已忘記當初的寫碼方式,讓程式碼更難修正。對於單機應用程式,這樣的商業代價或許還可接受,但在分散式系統中,後果會放大許多,容我們稍後再討論。
前述種種都是棘手的問題,但根據我們的經驗,在單機應用程式中加以忽略多半是安全的。最常見的解決方案是先前提過的:就讓記憶體分配錯誤損毀應用程式。分配記憶體的程式碼和其餘機器命運共享,而其餘機器在此案例中很可能即將失敗。即使並非命運共享,應用程式現在也會處在預期外的狀態,此時快速失敗是很好的策略。合理的商業代價。
對於在記憶體分配失敗時必須繼續運作的關鍵單機應用程式來說,有一個解決方案是在啟動時先行分配所有堆積記憶體,絕不再次依賴 malloc,即使在錯誤情況下也一樣。Amazon 已多次實作此策略;例如,在實際執行伺服器上執行的監控精靈中,以及在監控客戶 CPU 高載的 Amazon Elastic Compute Cloud (Amazon EC2) 精靈中。
分散式回復
在 Amazon,我們不會讓分散式系統,尤其是應當即時回應的系統,付出與單機應用程式相同的代價。理由之一是客戶與我們並非命運共享。假設應用程式是在客戶面前的機器上執行,如果應用程式的記憶體用盡,客戶可能不會期待程式繼續執行。然而服務並非在客戶直接使用的機器上執行,所以他們也會產生不同的期待。此外,客戶通常會使用服務的原因,正是因為比單一伺服器上執行的應用程式可用性更高,所以我們必須辦到這一點。理論上,這些考量會引導我們實作回復,作為讓服務更可靠的方法。然而很可惜,分散式回復除了前述所有問題之外,在關鍵系統失敗時,還會面臨其他問題。
分散式後退策略更難測試。 服務回復比單機應用程式案例複雜許多,因為多台機器和下游服務也扮演左右失敗的角色。在測試中難以複製失敗模式本身(例如過載情境),即使跨多台機器的測試協調已經就緒。排列組合也讓需要測試的案例遽增,因此您需要進行更多更難設置的測試。
分散式後退策略本身可能會失敗。雖然後退策略似乎可以保證成功,但根據我們的經驗,它們通常只提高成功的機率。
分散式備援策略通常會使中斷更糟。 根據我們的經驗,回復策略會擴大失敗的影響範圍,同時拉長復原時間。
分散式回復策略通常不值得冒險。 如同 malloc2 一樣,回復策略通常得付出某種代價;若非如此,我們一定老是使用。在已發生錯誤時,何苦再用讓事態更加惡化的回復策略?
分散式後退策略通常有潛在錯誤,這些錯誤只有在發生一組不可能的巧合發生時(可能在引入數個月或數年後)才會出現。
在 Amazon 零售網站上,因回復機制觸發的真實重大中斷故障事件,就是前述所有問題的最佳例證。2001 年前後曾發生過一次中斷故障,肇因是針對網站上顯示的所有產品,提供最新出貨速度的一項新功能。
這項新功能看起來像這樣:

因此,我們在每個 Web 服務器上添加了一個以單獨的進程運行的緩存層
當時網站架構只有兩層,因為此資料儲存在供應鏈資料庫中,因此 Web 伺服器必須直接查詢資料庫。但是,資料庫跟不上來自網站的大量請求。網站的流量相當高,有些網頁顯示 25 項或更多產品,且每項產品內嵌顯示出貨速度。因此,我們在每個 Web 服務器上添加了一個以單獨的進程運行的緩存層(有點像 Memcached):
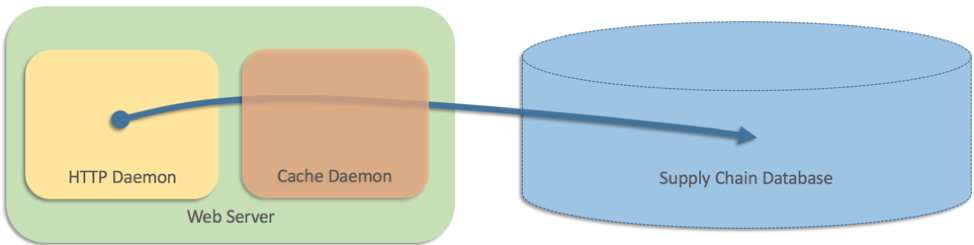
我們在虛擬碼中撰寫這樣的內容:
這樣的方式運作良好,但是團隊也嘗試處理快取(作為單獨程序)因某些理由失敗的案例。在此情境中,Web 伺服器恢復為直接查詢資料庫。在偽代碼中,我們寫了這樣的內容:返回直接數據庫查詢是一個直觀的解決方案,它已經有好幾個月的工作。不過,後來所有快取幾乎在相同時間全部失敗,也就意味著每部 Web 伺服器會直接觸及資料庫。因此帶來足以讓資料庫完全鎖死的負載量。整個網站大當機,因為所有 Web 伺服器程序都在資料庫上遭到封鎖。這個供應鏈資料庫對於履行中心也非常重要,因此中斷更加擴大,全球所有履行中心都停止,直到問題解決。我們在單機案例中看到的所有問題都存在於分散式案例中,帶來更嚴重的後果。測試分散式後退案例很難;即使我們模擬了緩存失敗,我們也不會發現問題,這需要在多台機器上發生故障才能觸發。在這種情況下,後備策略本身擴大了問題,並且比沒有備援策略更糟糕。後備將部分網站中斷(無法顯示出貨速度)變成全站停機(完全沒有載入頁面),並在後端消除了整個 Amazon 出貨網絡。在這種情況下,我們的備用策略背後的思考是不合理的。如果直接觸及資料庫比經由快取更可靠,當初何必那麼麻煩增加快取? 我們害怕不使用快取會造成資料庫過載,但如果潛在的傷害性如此之大,何必那麼麻煩設置回復程式碼? 我們可能早期注意到我們的錯誤,但錯誤是隱藏的錯誤,導致停機的情況出現在啟動後幾個月。
if (cache_healthy) {
shipping_speed = get_speed_via_cache(sku);
} else {
shipping_speed = get_speed_from_database(sku);
}Amazon 如何避免回復
由於我們在分散式回復中遭遇過這些陷阱,現在我們幾乎一律偏好採用回復之外的替代作法。摘述如下。
改善非回復情況的可靠性
如前所述,回復策略降低完全失敗可能性的成效不彰。如果主要(非回復)程式碼更穩固,服務的可用性會提升許多。例如:團隊不在兩個不同的資料存放區之間實作回復邏輯,而是投資使用固有可用性較高的資料庫,如 Amazon DynamoDB。此策略在 Amazon 各單位使用經常獲得成功。例如,本講座描述了使用 DynamoDB 在 2017 年 Prime Day 上為 amazon.com 提供電力。
讓叫用端處理錯誤
關鍵系統失敗的一個解決方案不是回復,而是讓叫用系統處理失敗(例如透過重試)。這是 AWS 服務偏好的策略,當中我們的 CLI 和 SDK 已有內建重試邏輯。在可能的範圍內我們偏好此策略,尤其是已經設法處理命運共享並降低主案例失敗可能性(且回復邏輯幾乎根本不可能改善可用性)的狀況。
主動推送資料
我們避免回復的另一項方針是減少回應請求時移動元件的數量。例如,如果服務需要資料以履行請求,且該資料已經存在於本機(不必擷取),就沒有必要採用容錯移轉策略。為 Amazon EC2 實作 AWS 身分與存取管理 (IAM) 角色的成功範例。IAM 服務需要提供已簽章與輪換的登入資料,給 EC2 執行個體上執行的程式碼。為了避免出現回復需要,會將登入資料主動推送至每個執行個體,且在數小時內維持有效。也就是說,在不太可能發生的推送機制中斷情況下,IAM 角色相關請求仍將繼續運作。
回復轉換為容錯移轉
關於回復最糟糕的一點在於並非定期實行,且在中斷故障期間一旦觸發,可能會失敗或擴大影響範圍。觸發回復的情況,可能要好幾個月甚至數年才會自然發生! 為了解決回復策略隱含失敗的問題,在實際執行環境中定期實作很重要。服務必須不間斷執行回復及非回復邏輯。不可只執行回復情況,而必須將其同樣視為有效的資料來源。例如,服務可隨機選擇回復及非回復回應(同時傳回兩者時),以確保兩者皆可正常運作。但是,此時不能再將其視為回復策略,而可以肯定其歸屬於容錯移轉類別。
確認重試和逾時不成為回復
重試和逾時將在超時、重試以及使用抖動反擊中討論。該文章說,重試是在臨時和隨機錯誤時提供高可用性的強大機制。換言之,針對假性封包遺失、不相關的單機失敗之類小問題造成的偶爾失敗,重試和逾時提供了保險。可是,重試和逾時也很容易受到誤解。服務常運行好幾個月甚至更久都不需要多次重試,最後卻在您的團隊從未測試的狀況下上陣。因此,我們保有監控整體重試率及警示(若重試頻頻發生,會對團隊發出警示)的數據。
避免重試變成後退的另一種方法是始終使用主動重試(也稱為對沖或平行請求)來執行它們。這是建立於執行仲裁讀取或寫入系統內的固有技術,該系統可能需要三部伺服器中的兩部應答才可回應。主動重試遵循不斷工作的設計模式。因為一律提出備援請求,所以重試不會使系統因為備援請求之需求增加而提高額外負載。
結論
在 Amazon,我們在系統中避免回復,因它的效用難以證明也難以測試。只有在系統內容開始破壞、最混亂的時刻才會進入回復策略帶來的運作模式,而切換為此模式只會使混亂不減反增。從實作回復策略,到回復策略在實際執行環境中遭遇問題,經常經過一段漫長的延遲時間。
相較於此,我們偏好可在實際執行環境中持續實行的程式碼途徑,而不是極少實行的途徑。我們藉由使用推送資料至所需系統的型態(而不是在關鍵時刻提取並冒著遠端叫用失敗的風險)專注於改善主要系統的可用性。最後,我們留意程式碼當中,可能使其翻轉為類回復操作模式的細微行為,例如執行重試次數過多。
如果回復對系統來說必不可少,我們會在實際執行環境中儘可能經常實作,讓回復行為一如主要操作模式般可預期且可靠。
作者簡介
Jacob Gabrielson 是 Amazon Web Services 的資深首席工程師。他已在 Amazon 服務 17 年,主要工作領域是內部微型服務平台。過去 8 年,他的工作項目為 EC2 和 ECS,包括軟體部署系統、控制平面服務、Spot 市場、Lightsail 和最近的容器專案。Jacob 熱衷於系統程式設計、程式設計語言和分散式運算。最不喜歡雙峰系統行為,尤其在失敗情況下。他擁有西雅圖華盛頓大學的電腦科學學士學位。
