



O que são incorporações em machine learning?
As incorporações são representações numéricas de objetos do mundo real que os sistemas de machine learning (ML) e inteligência artificial (IA) usam para entender domínios complexos do conhecimento, como os humanos. Como exemplo, os algoritmos de computação entendem que a diferença entre 2 e 3 é 1, indicando uma relação próxima entre 2 e 3 em comparação com 2 e 100. No entanto, os dados do mundo real incluem relacionamentos mais complexos. Por exemplo, um ninho de pássaro e uma toca de leão são pares análogos, enquanto dia-noite são termos opostos. As incorporações convertem objetos do mundo real em representações matemáticas complexas que capturam propriedades e relações inerentes entre dados do mundo real. Todo o processo é automatizado, com sistemas de IA criando incorporações automaticamente durante o treinamento e usando-as conforme necessário para concluir novas tarefas.
Por que as incorporações são importantes?
As incorporações permitem que os modelos de aprendizado profundo entendam os domínios de dados do mundo real com mais eficiência. Eles simplificam a forma como os dados do mundo real são representados, mantendo as relações semânticas e sintáticas. Isso permite que algoritmos de machine learning extraiam e processem tipos de dados complexos e possibilitem aplicações de IA inovadoras. As seções a seguir descrevem alguns fatores importantes.
Reduzir a dimensionalidade dos dados
Cientistas de dados usam incorporações para representar dados de alta dimensão em um espaço de baixa dimensão. Na ciência de dados, o termo dimensão normalmente se refere a uma característica ou atributo dos dados. Dados de maior dimensão em IA se referem a conjuntos de dados com muitos recursos ou atributos que definem cada ponto de dados. Isso pode significar dezenas, centenas ou até milhares de dimensões. Por exemplo, uma imagem pode ser considerada um dado de alta dimensão porque cada valor de cor de pixel é uma dimensão separada.
Quando apresentados com dados de alta dimensão, os modelos de aprendizado profundo exigem mais poder computacional e tempo para aprender, analisar e inferir com precisão. As incorporações reduzem o número de dimensões identificando semelhanças e padrões entre vários atributos. Consequentemente, isso reduz os recursos de computação e o tempo necessários para processar dados brutos.
Treinar grandes modelos de linguagem
As incorporações melhoram a qualidade dos dados ao treinar grandes modelos de linguagem (LLMs). Por exemplo, cientistas de dados usam incorporações para limpar os dados de treinamento de irregularidades que afetam o aprendizado do modelo. Os engenheiros de ML também podem reutilizar modelos pré-treinados adicionando novas incorporações para o aprendizado por transferência, o que exige o refinamento do modelo básico com novos conjuntos de dados. Com as incorporações, os engenheiros podem ajustar um modelo para conjuntos de dados personalizados do mundo real.
Criar aplicações inovadoras
As incorporações permitem novas aplicações de aprendizado profundo e inteligência artificial generativa (IA generativa). Diferentes técnicas de incorporação aplicadas na arquitetura de rede neural permitem que modelos precisos de IA sejam desenvolvidos, treinados e implantados em vários campos e aplicações. Por exemplo:
- Com a incorporação de imagens, os engenheiros podem criar aplicações de visão computacional de alta precisão para detecção de objetos, reconhecimento de imagens e outras tarefas visuais.
- Com a incorporação de palavras, o software de processamento de linguagem natural pode entender com mais precisão o contexto e as relações das palavras.
- As incorporações gráficas extraem e categorizam informações relacionadas de nós interconectados para apoiar a análise de rede.
Modelos de visão computacional, chatbots de IA e sistemas de recomendação de IA usam incorporações para concluir tarefas complexas que imitam a inteligência humana.
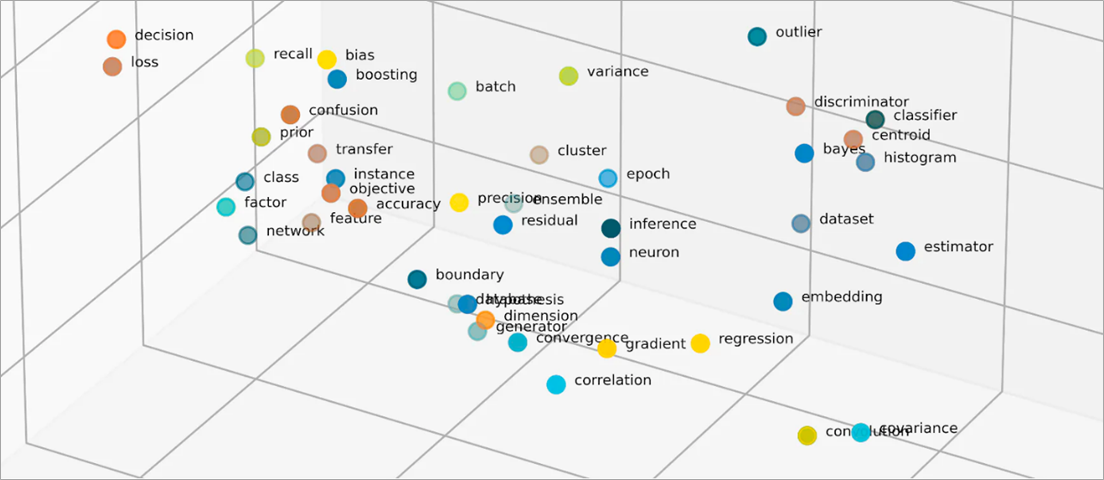
O que são vetores em incorporações?
Os modelos de ML não conseguem interpretar as informações de forma inteligível em seu formato bruto e exigem dados numéricos como entrada. Eles usam incorporações de redes neurais para converter informações reais em representações numéricas chamadas vetores. Vetores são valores numéricos que representam informações em um espaço multidimensional. Eles ajudam os modelos de ML a encontrar semelhanças entre itens pouco distribuídos.
Cada objeto com o qual um modelo de ML aprende tem várias características ou atributos. Como um exemplo simples, considere os seguintes filmes e programas de TV. Cada um é caracterizado pelo gênero, tipo e ano de lançamento.
The Conference (Horror, 2023, Movie)
Upload (Comedy, 2023, TV Show, Season 3)
Tales from the Crypt (Horror, 1989, TV Show, Season 7)
Dream Scenario (Horror-Comedy, 2023, Movie)
Os modelos de ML podem interpretar variáveis numéricas, como anos, mas não podem comparar variáveis não numéricas, como gênero, tipos, episódios e total de temporadas. A incorporação de vetores codifica dados não numéricos em uma série de valores que os modelos de ML podem entender e relacionar. Por exemplo, a seguir está uma representação hipotética dos programas de TV listados anteriormente.
The Conference (1.2, 2023, 20.0)
Upload (2.3, 2023, 35.5)
Tales from the Crypt (1.2, 1989, 36.7)
Dream Scenario (1.8, 2023, 20.0)
O primeiro número no vetor corresponde a um gênero específico. Um modelo de ML descobriria que The Conference e Tales from the Crypt compartilham o mesmo gênero. Da mesma forma, o modelo encontrará mais relações entre Upload e Tales from the Crypt com base no terceiro número, representando o formato, as temporadas e os episódios. À medida que mais variáveis são introduzidas, você pode refinar o modelo para condensar mais informações em um espaço vetorial menor.
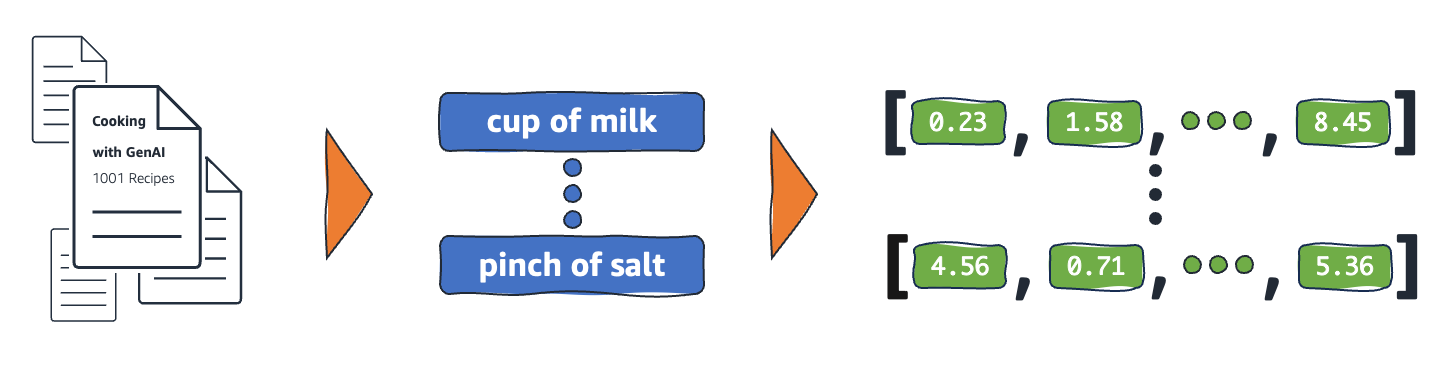
Como as incorporações funcionam?
As incorporações convertem dados brutos em valores contínuos que os modelos de ML podem interpretar. Convencionalmente, os modelos de ML usam codificação única para mapear variáveis categóricas em formas com as quais elas possam aprender. O método de codificação divide cada categoria em linhas e colunas e atribui a elas valores binários. Considere as seguintes categorias de produtos e seus preços.
| Frutas |
Preço |
| Apple |
5,00 |
| Orange |
7,00 |
| Carrot |
10,00 |
A representação dos valores com codificação única resulta na tabela a seguir.
| Apple |
Orange |
Pear |
Preço |
| 1 |
0 |
0 |
5,00 |
| 0 |
1 |
0 |
7,00 |
| 0 |
0 |
1 |
10,00 |
A tabela é representada matematicamente como vetores [1,0,0,5.00], [0,1,0,7.00] e [0,0,1,10.00].
A codificação one-hot expande os valores dimensionais de 0 e 1 sem fornecer informações que ajudem os modelos a relacionar os diferentes objetos. Por exemplo, o modelo não consegue encontrar semelhanças entre apple e orange, apesar de serem frutas, nem pode diferenciar orange e carrot como frutas e vegetais. À medida que mais categorias são adicionadas à lista, a codificação resulta em variáveis pouco distribuídas com muitos valores vazios que consomem um enorme espaço de memória.
As incorporações vetorizam objetos em um espaço de baixa dimensão representando semelhanças entre objetos com valores numéricos. As incorporações de redes neurais garantem que o número de dimensões permaneça gerenciável com a expansão dos atributos de entrada. Os atributos de entrada são características de objetos específicos que um algoritmo de ML tem a tarefa de analisar. A redução da dimensionalidade permite que as incorporações retenham as informações que os modelos de ML usam para encontrar semelhanças e diferenças nos dados de entrada. Os cientistas de dados também podem visualizar incorporações em um espaço bidimensional para entender melhor as relações de objetos distribuídos.
O que são modelos de incorporação?
Modelos de incorporação são algoritmos treinados para encapsular informações em representações densas em um espaço multidimensional. Os cientistas de dados usam modelos de incorporação para permitir que os modelos de ML compreendam e raciocinem com dados de alta dimensão. Esses são modelos de incorporação comuns usados em aplicações de ML.
Análise de componentes principais
A análise de componentes principais (PCA) é uma técnica de redução de dimensionalidade que reduz tipos de dados complexos em vetores de baixa dimensão. Ele encontra pontos de dados com semelhanças e os compacta em vetores incorporados que refletem os dados originais. Embora o PCA permita que os modelos processem dados brutos com mais eficiência, a perda de informações pode ocorrer durante o processamento.
Decomposição de valores singulares
A decomposição de valor singular (SVD) é um modelo de incorporação que transforma uma matriz em suas matrizes singulares. As matrizes resultantes retêm as informações originais enquanto permitem que os modelos compreendam melhor as relações semânticas dos dados que representam. Os cientistas de dados usam o SVD para habilitar várias tarefas de ML, incluindo compressão de imagens, classificação de texto e recomendação.
Word2Vec
O Word2Vec é um algoritmo de ML treinado para associar palavras e representá-las no espaço de incorporação. Cientistas de dados alimentam o modelo Word2Vec com grandes conjuntos de dados textuais para permitir a compreensão da linguagem natural. O modelo encontra semelhanças nas palavras ao considerar seu contexto e suas relações semânticas.
Existem duas variantes do Word2Vec—Continuous Bag of Words (CBOW) e Skip-gram. O CBOW permite que o modelo preveja uma palavra a partir de um determinado contexto, enquanto o Skip-gram deriva o contexto de uma determinada palavra. Embora o Word2Vec seja uma técnica eficaz de incorporação de palavras, ele não consegue distinguir com precisão as diferenças contextuais da mesma palavra usada para sugerir significados diferentes.
BERT
O BERT é um modelo de linguagem baseado em transformador treinado com grandes conjuntos de dados para entender linguagens como os humanos. Como o Word2Vec, o BERT pode criar incorporações de palavras a partir dos dados de entrada com os quais foi treinado. Além disso, o BERT pode diferenciar os significados contextuais das palavras quando aplicado a frases diferentes. Por exemplo, o BERT cria diferentes incorporações para “play”, como em “I went to a play” e “I like to play”.
Como as integrações são criadas?
Os engenheiros usam redes neurais para criar incorporações. As redes neurais consistem em camadas de neurônios ocultas que tomam decisões complexas de forma iterativa. Ao criar incorporações, uma das camadas ocultas aprende como fatorar atributos de entrada em vetores. Isso ocorre antes das camadas de processamento de atributos. Esse processo é supervisionado e orientado por engenheiros com as seguintes etapas:
- Os engenheiros alimentam a rede neural com algumas amostras vetorizadas preparadas manualmente.
- A rede neural aprende com os padrões descobertos na amostra e usa o conhecimento para fazer previsões precisas a partir de dados não vistos.
- Ocasionalmente, os engenheiros podem precisar ajustar o modelo para garantir que ele distribua os atributos de entrada no espaço dimensional apropriado.
- Com o tempo, as integrações operam de forma independente, permitindo que os modelos de ML gerem recomendações a partir das representações vetorizadas.
- Os engenheiros continuam monitorando a performance da incorporação e ajustando com novos dados.
Como a AWS pode ajudar com seus requisitos de incorporação?
O Amazon Bedrock é um serviço totalmente gerenciado que oferece uma variedade de modelos de base (FMs) de alta performance das principais empresas de IA, além de um amplo conjunto de atributos para criar aplicações de inteligência artificial generativa (IA generativa). Os modelos da fundação Amazon Bedrock Titan são uma família de FMs pré-treinados pela AWS em grandes conjuntos de dados. Eles são modelos poderosos e de uso geral, criados para suportar uma variedade de casos de uso. Utilize-os em sua configuração original ou personalize-os com seus próprios dados.
Titan Embeddings é um LLM que traduz texto em uma representação numérica. O modelo Titan Embeddings oferece suporte à recuperação de texto, similaridade semântica e agrupamento. O texto máximo de entrada é de 8K tokens e o comprimento máximo do vetor de saída é 1536.
As equipes de machine learning também podem usar o Amazon SageMaker para criar incorporações. O Amazon SageMaker é um hub no qual você pode criar, treinar e implantar modelos de ML em um ambiente seguro e escalável. Ele fornece uma técnica de incorporação chamada Object2Vec, com a qual engenheiros podem vetorizar dados de alta dimensão em um espaço de baixa dimensão. Você pode usar as incorporações aprendidas para calcular relacionamentos entre objetos para tarefas posteriores, como classificações e regressão.
Comece a usar integrações na AWS criando uma conta hoje mesmo.
Próximas etapas na AWS
Obtenha acesso instantâneo ao nível gratuito da AWS.