



Что такое синтетические данные?
Синтетические данные – это данные, созданные не человеком, при этом имитирующие реальные данные. Они создаются с помощью вычислительных алгоритмов и моделирования на основе технологий генеративного искусственного интеллекта. Синтетический набор данных обладает теми же математическими свойствами, что и фактический, на которых он основан, но не содержит информации из него. Организации используют синтетические данные для исследований, тестирования и новых разработок в области машинного обучения. Последние инновации в области искусственного интеллекта сделали генерацию синтетических данных эффективной и быстрой, а также повысили ее значение в вопросах регулирования данных.
Каковы преимущества синтетических данных?
Синтетические данные предоставляют организациям ряд преимуществ. Далее мы рассмотрим некоторые из них.
Неограниченная генерация данных
Синтетические данные можно создавать по запросу и практически в неограниченном масштабе. Инструменты генерации синтетических данных позволяют экономично получить большой объем данных. Они также могут присваивать метки (классифицировать или маркировать) для всех созданных данных, что полезно для сценариев с машинным обучением. Вы получаете доступ к структурированным и маркированным данным без необходимости преобразовывать необработанные данные. Вы также можете добавить синтетические данные к уже имеющемуся объему данных, чтобы увеличить размер обучающих данных для анализа.
Защита конфиденциальности
В таких областях, как здравоохранение, финансы и юриспруденция, существует множество нормативных актов по защите конфиденциальности, авторских прав и соблюдению требований, которые регламентируют защиту конфиденциальных данных. Но организациям в этих отраслях нужно использовать данные для аналитики и исследований, и для извлечения максимальной пользы часто приходится передавать эти данные третьим сторонам. Вместо реальных конфиденциальных данных они могут в целях исследований использовать синтетические наборы данных. Они создают данные с такими же статистическими характеристиками, но без раскрытия личных или конфиденциальных данных. Давайте для примера рассмотрим медицинские исследования, в которых синтетические данные создаются на основе динамического набора данных и содержат такой же процент биологических характеристик и генетических маркеров, что и исходный набор данных, но в них все имена, адреса и другие личные сведения о пациенте являются фиктивными.
Снижение предвзятости
С помощью синтетических данных можно снизить предвзятость обучаемых моделей искусственного интеллекта. Поскольку большие модели обычно основаны на общедоступных данных, эти тексты могут содержать необъективные мнения. Исследователи могут использовать синтетические данные, чтобы противопоставлять их предвзятым формулировкам или мнениям, которые собирают модели искусственного интеллекта. Например, если определенный контент основан на частных мнениях и отдает предпочтение определенной группе людей, вы можете создать синтетические данные для балансировки набора данных.
Какие существуют типы синтетических данных?
Различают два основных типа синтетических данных – частично и полностью синтетические.
Частично синтетические данные
В частично синтетических данных небольшую часть реального набора данных заменяется синтетической информацией. Такие данные можно использовать для защиты конфиденциальных фрагментов в наборе данных. Например, если вам нужно анализировать данные конкретных клиентов, вы можете синтезировать такие атрибуты, как имя, контактные данные и некоторую другую реальную информацию, чтобы по ним невозможно было отследить конкретного человека.
Полностью синтетические данные
Полностью синтетические данных содержат только искусственно сгенерированные значения. Полностью синтетический набор данных не содержит никаких реальных данных. Но в нем будут сохраняться те же соотношения, распределения и статистические свойства, что и в реальных данных. Такие данные не основаны на реальных собранных данных, но они позволяют сделать точно такие же выводы.
При тестировании моделей машинного обучения можно смело использовать полностью синтетические данные. Это полезно для тестирования или создания новых моделей, когда у вас нет достаточного количества реальных данных, чтобы получить нужную точность машинного обучения.
Как генерируются синтетические данные?
Генерация синтетических данных включает использование вычислительных методов и моделирования. Результат имитирует статистические свойства реальных данных, но не содержит реальных наблюдений. Возможна генерация данных в разных форматах: текст, числа, таблицы или более сложные типы, вплоть до изображений и видео. Различают три основных подхода к генерации синтетических данных, каждый из которых дает разные уровни точности и разные типы данных.
Статистическое распределение
При этом подходе сначала анализируются реальные данные для поиска лежащих в их основе статистических распределений: нормальное, экспоненциальное, хи-квадратное распределение и так далее. Затем специалисты по анализу данных генерируют синтетические примеры с обнаруженными распределениями, чтобы получить набор данных, статистически близкий к исходному.
На основе модели
При этом подходе модель машинного обучения обучается понимать и воспроизводить характеристики реальных данных. После обучения модель может генерировать искусственные данные с таким же статистическим распределением, как у реальных данных. Этот подход особенно полезен для создания гибридных наборов данных, в которых статистические свойства реальных данных сочетаются с дополнительными синтетическими элементами.
Методы глубокого обучения
Для генерации синтетических данных можно использовать передовые технологии, такие как генеративные состязательные сети (GAN), вариационные автокодировщики (VAE) и другие. Эти методы часто применяются к более сложным типам данных, таким как изображения или данные временных рядов, и позволяют создавать высококачественные синтетические наборы данных.
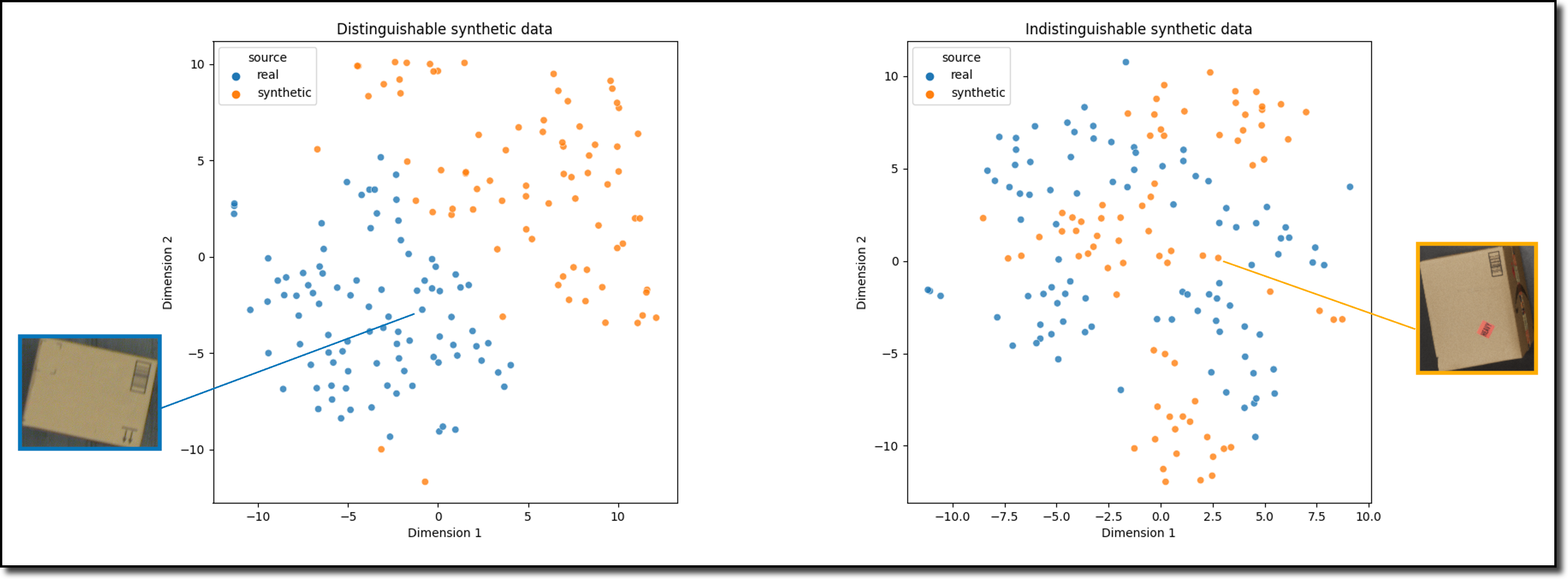
Что представляют собой технологии генерации синтетических данных?
Ниже мы расскажем о некоторых передовых технологиях, которые можно использовать для генерации синтетических данных.
Генеративные состязательные сети
Модели генеративных состязательных сетей (GAN) используют две нейронные сети, которые совместно генерируют и классифицируют новые данные. Одна из них использует необработанные данные для получения синтетических данных, а вторая оценивает, характеризует и классифицирует эту информацию. Эти сети продолжают соперничество друг с другом до тех пор, пока сеть оценки не перестанет различать синтетические данные и исходные данные.
С помощью GAN можно генерировать синтетические данные с высокой степенью достоверности и точно отражающие характеристики реальных данных, например реалистично выглядящие видео и изображения.
Подробнее о генеративных состязательных сетях (GAN) »
Вариационные автокодировщики
Вариационные автокодировщики (VAE) – это алгоритмы, генерирующие новые данные на основе представлений исходных данных. Алгоритм обучения без наблюдения изучает распределение необработанных данных, а затем применяет архитектуру кодер-декодер для генерации новых данных через двойной преобразование. Кодер сжимает входные данные в представление более низкой размерности, а декодер «восстанавливает» новые данные из этого ограниченного представления. Модель использует вероятностные вычисления для плавного распределения воспроизводимых данных.
VAE наиболее полезны для создания синтетических данных, очень похожих на исходные с некоторыми вариациями. Например, вы можете использовать VAE при создании новых изображений.
Модели на основе трансформеров
Генеративные предобученные трансформеры или модели на основе GPT используют большие исходные наборы данных для понимания структуры и типичного распределения данных. В основном они используются для генерации текста с обработкой естественного языка (NLP). Например, если текстовую модель на основе трансформера обучить по большому набору текстов на английском языке, она будет понимать структуру, грамматику и даже нюансы этого языка. При создании синтетических данных модель берет за основу текст-затравку (или подсказки) и прогнозирует следующее слово на основе изученных вероятностей, постепенно формируя полную последовательность.
Какие сложности возникают при генерации синтетических данных?
При создании синтетических данных возникает несколько сложностей. Ниже перечислены типичные ограничения и задачи, которые вам предстоит преодолеть при работе с синтетическими данными.
Контроль качества
В статистике и аналитике очень важное значение имеет качество данных. Прежде чем включать синтетические данные в модели обучения, тщательно проверьте их точность соблюдение минимального уровня качества данных. Но снижение точности может оказаться обязательным, чтобы никто не смог сопоставить синтетические данные с реальной информацией. Компромисс между конфиденциальностью и точностью может повлиять на качество обучения.
Чтобы решить эту проблему, можно вручную выполнить проверку синтетических данных перед их использованием. Но не забывайте, что проверка вручную может занять очень много времени, если вам требуется большой объем синтетических данных.
Технические проблемы
Создавать синтетические данные непросто. Чтобы обеспечить их точность и полезность, важно хорошо разбираться в подходах, правилах и современных методах. Чтобы генерировать полезные синтетические данные, вам требуется большой опыт в этой области.
Но даже при хорошем опыте создание синтетических данных, которые идеально имитируют реальные аналоги, – непростая задача. Например, реальные данные часто содержат отклонения и аномалии, которые сложно воссоздать с помощью алгоритмов генерации синтетических данных.
Разногласия заинтересованных сторон
Синтетические данные являются полезным дополнительным инструментом, но не все заинтересованные стороны понимают их важность. Поскольку это совсем новая технология, некоторые бизнес-пользователи могут не считать аналитику по синтетическим данным актуальным для реального мира. С другой стороны, некоторые могут переоценивать ожидаемые результаты из-за контролируемого аспекта генерации. Расскажите всем заинтересованным сторонам об ограничениях этой технологии и ее результатов. Убедитесь, что они правильно поняли как преимущества, так и недостатки технологии.
Как AWS может вам помочь в создании синтетических данных?
Amazon SageMaker – это полностью управляемый сервис, который можно использовать для подготовки данных, создания, обучения и развертывания моделей машинного обучения (ML). Эти модели подходят для любого варианта использования с полностью управляемой инфраструктурой, инструментами и рабочими процессами. SageMaker предлагает два варианта для маркировки необработанных данных, например изображений, текстовых файлов и видео, и генерации синтетических данных с метками для получения высококачественных наборов данных для обучения моделей машинного обучения.
- Amazon SageMaker Ground Truth – это сервис самообслуживания, который упрощает маркировку данных. Он позволяет привлечь людей для создания аннотаций через сервис Amazon Mechanical Turk, через сторонних поставщиков или из числа ваших сотрудников.
- Amazon SageMaker Ground Truth Plus – это полностью управляемый сервис, который позволяет создавать высококачественные наборы обучающих данных. Вам не придется самостоятельно создавать приложения для маркировки или организовывать работу сотрудников для маркировки.
Прежде всего, вы определяете требования к синтетическим изображениям или предоставляете 3D-ресурсы и базовые изображения, например в формате CAD (автоматизированного проектирования). Затем цифровые художники AWS создают изображения «с нуля» или на основе предоставленных заказчиком ресурсов. Сгенерированные изображения имитируют позу и расположение объектов, добавляют вариации объектов или сцен, а при необходимости добавляют новые включения, как например царапины, вмятины и так далее. Это избавляет от трудоемкого процесса сбора данных и от необходимости повреждать элементы для получения изображений. Вы можете создавать сотни тысяч синтетических изображений, которые автоматически маркируются с высокой точностью.
Начните работу по генерации синтетических данных на AWS, создав бесплатный аккаунт прямо сейчас.
AWS: дальнейшие шаги
Получите мгновенный доступ к уровню бесплатного пользования AWS.