Artificial Intelligence
Powering Language Learning on Duolingo with Amazon Polly
| Listen to this post
Voiced by Amazon Polly |

This is a guest post by André Kenji Horie, a software engineer on Duolingo’s Learning Team. In their own words, “Duolingo is the most popular language-learning platform and the most downloaded education app in the world, with more than 170 million users.”
When teaching a foreign language, accurate pronunciation matters. If exposed to incorrect pronunciation, learners develop their listening and speaking skills poorly, which compromises their ability to communicate effectively. Duolingo uses text-to-speech (TTS) to provide high-quality language education. To some, this approach might seem counterintuitive: shouldn’t people learn by listening to a native speaker?
In this post, we outline why we chose to use TTS instead of human recordings. We also describe our quantitative and qualitative framework for choosing voices to ensure high-quality material for our users. Using this framework, we show that Amazon Polly has provided a superior experience. Finally, we provide an overview of the infrastructure we built for reliably serving audio to millions of language learners every day.
The learning experience for pronunciation
Users learn languages on Duolingo through gamified, bite-sized lessons. Each lesson is composed of a series of exercises, which target different linguistic skills and concepts. In the example following, the user practices how to use the word “leo” (which means “I read” in Spanish) by being exposed to the sentence “I read books.”
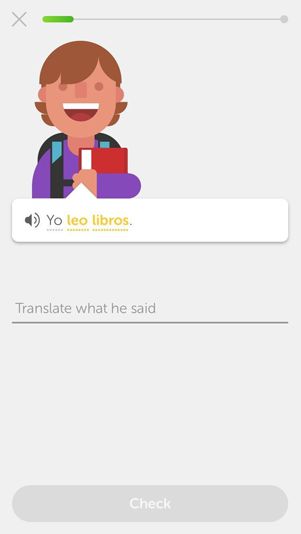
When this exercise shows up, the audio for “Yo leo libros” automatically plays. The user can play the audio again by tapping on the speaker icon. The audio repeat serves as auditory reinforcement for the written text, providing learners the necessary information about pronunciation. This type of multisensory instruction is an effective way of teaching languages because the human memory operates more optimally than when stimulated by a single sensory modality [1][2].
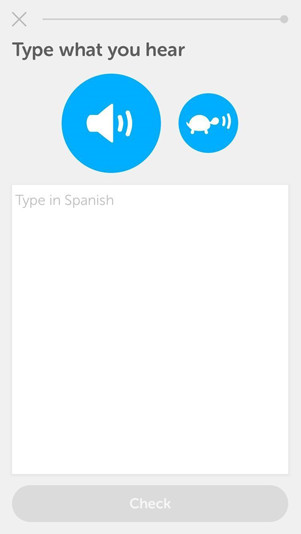
Other exercises test users on their ability to reproduce sentences read by the audio, targeting listening comprehension specifically. In the example following, the user listens to a sentence, with the option of listening to a slow version. The audio then prompts the user to type what is heard. The slow version is geared toward beginner learners, who still find it difficult to grasp phonemes in the language that they’re learning.
Finally, there are exercises that test pronunciation. With the example following, users have to correctly pronounce the sentence they are given.
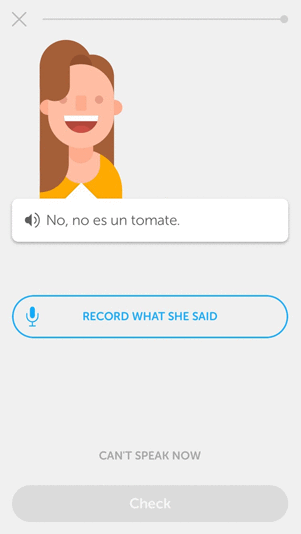
After a user speaks the sentence, we do speech recognition to check whether the user has pronounced it correctly. Although speech recognition is not within the scope of this blog post, this example illustrates all aspects involved in the learning experience for pronunciation:
- Help learners internalize phonemes
- Test how well they can distinguish them
- Test how well they can produce them
Why TTS?
Several arguments exist for and against using TTS over human recordings, some of which we discuss with more details following. In summary, TTS has a clear edge when it comes to operationalizing the audio creation process, and it’s not far behind human recordings for voice quality. In fact, we have observed that current state-of-the-art TTS voices are as good as natural human speech for the purpose of language learning.
On operational complexity
The process of recording audio with a voice actor tends to be slow and cumbersome. Following is an example showing each step needed for recording sentences and exposing them in the production environment:
- Find a company that records audio in the language: The company must find a voice actor who not only speaks the language, but also who speaks with good pronunciation and clarity.
- Find someone to evaluate the quality of pronunciation: We need an independent party from the recording company to create a small sample of sentences, which this party uses to evaluate pronunciation quality of the recordings.
- Record and evaluate the quality of the sample sentences.
- Set up a contract with the recording company.
- Record all sentences.
- Evaluate recordings, providing a data quality assurance check. For example, we need to check if all files are in the proper format and correctly separated. This step is necessary because the industry standard is to record all sentences in a single session and separate them later.
On the other hand, the process when using TTS is much simpler. It involves evaluating the quality of the voice and adding code to your data pipeline so that audio generation is handled automatically. With Amazon Polly and boto3 (in the AWS SDK for Python), just the few lines of code following do the trick in a basic scenario. You can alternatively write a microservice that handles distribution of the audio files, as detailed later in this post.
On speed of iteration
Duolingo is constantly improving the quality of its courses, with new content being added daily. As a result, we need to be able to create audio on a regular basis. This approach is not feasible with the workflow defined preceding, because that workflow typically takes weeks. Such a workflow hurts our ability to iterate quickly, which in turn could compromise our innovative edge.
On scalability
Also, recording audio is not a scalable approach. Aside from the cost and effort required for adding a new language, the resources required to maintain this process grow linearly with the amount of content we produce. We currently teach 25 different languages in 69 courses, each of which consists of tens of thousands of sentences.
On cost
Recording audio is much more costly than generating audio with TTS. As a comparison, one hour of studio rental alone is equivalent to generating audio for tens of millions of characters using Amazon Polly, the TTS provider with the best cost-effectiveness. (This amount of audio is the equivalent of reading A Christmas Carol by Charles Dickens a couple of hundred times.) In addition, recorded audio would require the cost of hiring all the necessary people, including someone in-house to oversee the operation and probably some engineering time. Another cost is the intangible one of slower iterations.
On pronunciation errors
Pronunciation errors directly affect learning outcomes, because learners internalize incorrect phonemes in their mental model of the language. Although we expect that TTS produces audio with more errors, we can easily identify and address these. For example, we can use Speech Synthesis Markup Language (SSML) to control aspects of speech. In addition, the number and severity of pronunciation errors have been steadily decreasing with the latest advancements in AI. Errors in state-of-the-art TTS providers such as Amazon Polly are few and far between.
On natural-sounding voices
As with pronunciation errors, TTS voices have also dramatically improved with the latest machine learning models, without producing awkward intonation or sounding too robotic.
Continuously improving courses: The case for Amazon Polly
At Duolingo, we improve our products continuously and incrementally. In this section, we present our framework for improving language courses, highlighting our quantitative approach for measuring these improvements as well as our qualitative approach for analyzing the impact. We contextualize TTS in this framework, and give insights on our experiments and collected user feedback that attest to the high quality of Amazon Polly voices.
A quantitative framework
As a data-driven company, we use A/B tests to evaluate how all new features improve relevant business metrics. An A/B test is an experiment where users are randomly split into two groups, one that is exposed to the new feature and one that is not. The experiment then measures which group performed significantly better according to statistics evaluated on a certain metric of interest.
Take the example following. Suppose here that 30% of the users in the group exposed to an old feature respond accurately to some task, but 60% exposed to the new feature respond accurately. In this case, the new feature is considered to be an improvement. We can then test whether changing the text in a button leads to improvement in click-through rate, or changing the game mechanics leads to improvement in engagement. We can even test two different versions of a course to see which one provides the highest measured learning outcome.

One way to improve the course is to test which of two or more TTS voices provide the highest gains in engagement and learning outcomes. These gains are important given the advances of the field in recent years.
The process of setting up an A/B test between two voices is the following:
- Choose a voice with opportunity for improvement.
- Choose a new voice that might present gains in metrics.
- Generate audio for all relevant sentences in the new voice.
- Set 50% of users to always be served original audio generated with the old voice, and the other 50% to be served with the new voice.
- Run the A/B test until we have statistically significant results.
- Adopt the voice with higher metrics for all users.
So far, we have run six A/B tests, which tested the introduction of an Amazon Polly voice against the voice we had been using from other TTS providers. We have not run A/B tests against human voices, because the experiment is not feasible to set up, due to the costly, slow, and cumbersome process. For all of these experiments, the winning condition was the Amazon Polly voice, namely:
- Sally (female English voice)
- Carla (female Italian voice)
- Vitoria (female Portuguese voice)
- Hans (male German voice)
- Astrid (female Swedish voice)
- Ruben (male Dutch voice)
From the experiments preceding, one unexpected result was Ruben. This result was interesting because the losing condition was a female voice, and female voices are more effective for learning. We can hypothesize that the gender effect is offset by the difference in overall voice quality.
A qualitative framework
Relying only on a quantitative approach might hide some useful insights. This drawback motivated us to also collect qualitative data. We collected user feedback from our massive user base regarding pronunciation quality, how pleasing the voice is, and other factors.
The feedback was similar to the results of the A/B test. Users responded positively to the new Amazon Polly voices. They said that these voices sounded more natural, were more pleasant to hear, and made fewer pronunciation mistakes.
Building a microservice that serves millions of users
When serving audio files to millions of users, two crucial factors to consider are cost and network latency. These motivated us to build a microservice that focuses on the following:
- Managing TTS creation to avoid generating TTS for the same text multiple times.
- Storing pregenerated TTS.
- Delivering pregenerated TTS in an endpoint geographically close to the user.
The resulting architecture resembles the diagram following:
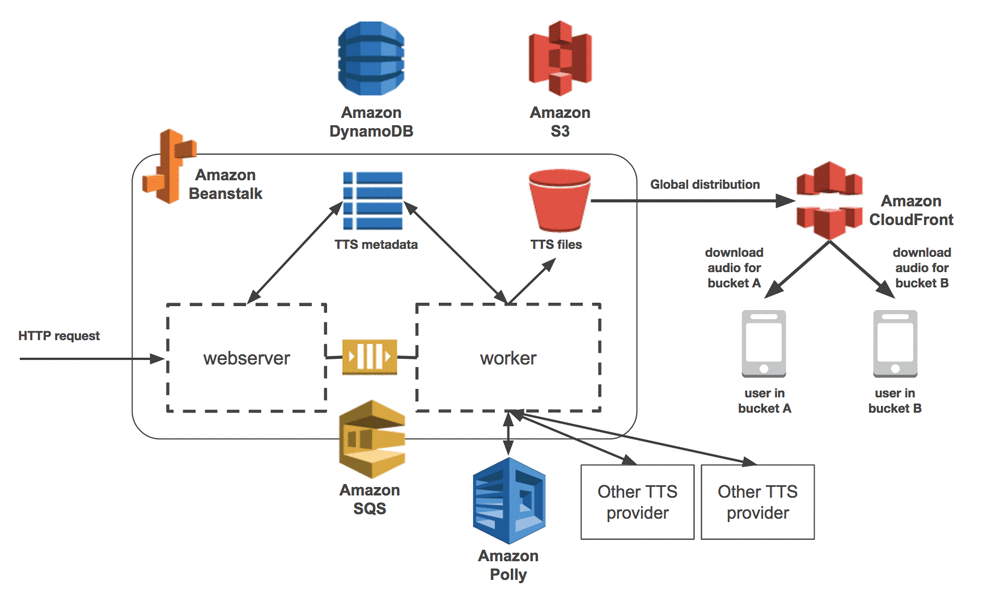
The data flow starts from a microservice client such as the Duolingo Incubator, our crowdsourced platform for course content creation. In the Incubator, the process starts when a contributor prepares a lesson that requires new audio files. The backend then sends an HTTP request to the TTS microservice, with the text of the audio to be generated, language of the text, a callback URL (more on that later), and more.
The TTS microservice, built on top of AWS Elastic Beanstalk, receives the message in its webserver environment. It checks whether an audio file has already been created. This metadata is stored in an Amazon DynamoDB table.
If the metadata indicates that audio has been created, a response is sent back to the Incubator with the creation status “created”. Otherwise, the webserver sends a message via an Amazon SQS queue to the worker environment for asynchronous execution. This message sets the status to “requested”. This status prevents generating audio multiple times for the same sentence.
The worker then receives the message, and requests a TTS provider such as Amazon Polly for the audio file. We use Amazon Polly voices for most languages for which we have learning material, except for a few cases for which we have not run A/B tests yet and are still using the provider we originally picked.
After the audio file is generated, the worker uploads it to Amazon S3. The file is then automatically cached in Amazon CloudFront endpoints, so that it is served more quickly to end users. Finally, the worker sets the status to “created”, and calls the callback URL given in the initial request in order to notify that processing has been finalized and that the file is ready to be used by the application.
This architecture allows the microservice clients (the Incubator, in this case) to only care about the fact that it has been generated. New clients just need to implement sending an HTTP request for audio file creation and an API route for the callback. The microservice is the one responsible for handling all common functionality regarding TTS, which includes asynchronicity of requests, audio file generation, caching, distribution, and more.
Conclusion
In this post, we provided insights on why Duolingo uses text-to-speech over human recordings for language learning. We also talked about our framework for continuous improvement of our courses, which resulted in Amazon Polly voices obtaining higher metrics when A/B tested and receiving better user feedback. In addition, we showed how we architected a microservice that serves audio files for our user base of 170 million language learners.
References
[1] Shams, Ladan, and Aaron R. Seitz. “Benefits of multisensory learning.” Trends in cognitive sciences 12.11 (2008): 411-417.
[2] Dinh, Huong Q., et al. “Evaluating the importance of multi-sensory input on memory and the sense of presence in virtual environments.” Virtual Reality, 1999. Proceedings., IEEE. IEEE, 1999.