AWS Partner Network (APN) Blog
How Tech Mahindra Built a Self-Service Patch Management Process Using AWS Native Services
By Natarajan Ramanathan, Cloud Infrastructure Architect – Tech Mahindra
By Raju Swargam, Cloud infrastructure Architect – Tech Mahindra
By YV Ramesh, DevOps Engineer – Tech Mahindra
By Sathish Arumugam, Partner Solutions Architect – AWS
 |
Patch management is a continuous cybersecurity process that includes identifying, reporting, and fixing the system vulnerabilities. Applying patching to remediate the vulnerabilities are important, as it ensures all of your systems are functioning correctly and in the most efficient way.
An operating system’s patches are part of essential preventative maintenance, necessary to keep machines up-to-date, stable, and safe from malware and other threats. The vast majority of cyberattacks take advantage of known software vulnerabilities. The longer you go without updating or applying patches, the more risk the business assumes.
Applying the patches and updates quickly reduces the chances of attackers accessing your systems.
In this post, we will discuss Tech Mahindra‘s automated patching solution which helps and ensures every server on the infrastructure system’s network is up-to-date by patching quickly and efficiently.
Tech Mahindra is an AWS Advanced Consulting Partner and Managed Service Provider (MSP) that specializes in digital transformation, consulting, and business re-engineering solutions. Their expertise in automation and Amazon Web Services (AWS) helped them to build the IT systems patch management process using AWS native services.
Tech Mahindra’s Automated Patching Solution
Following are the key highlights of Tech Mahindra’s automated patching solution:
- Agility: Patches are installed in a timely manner, which means you can reduce the time it takes to make applications available to the business securely from hours to just minutes, or with zero downtime.
. - Operational excellence: End-to-end patching and reports are automated to keep the business running effectively by gaining insight into the operation, and continuously improve supporting processes and procedures.
. - Self-service maintenance windows: Self-service is one of the key advantage of this patching solution because, until now, the majority of IT industries have applied patching based on defined windows. Asset owners don’t have the ability to change the patching windows, so the organization never compromises with application release (patching exceptions).
.
Many application teams used to postpone their critical application release and features because of the patching, which can impact the business. To overcome this, Tech Mahindra has developed a self-service patching process where asset owners can select the patching window based on the application release and critical testing.
. - Exception process: An exception process exists in case asset or application owners don’t want the system to be updated or patched for a particular time period because of various reason such as audits, biddings, or high-priority releases.
. - Post-patching results dashboard: This helps you understand how many packages are installed on your assets and how many are still available. In legacy patching, asset owners were not typically aware what patching meant and what was the old and new kernel. With Tech Mahindra’s solution, asset owners can directly verify which kernel was updated as part of patching and how many packages were updated.
Customer Benefits
- Tech Mahindra’s automated patching solution improves vulnerability remediation in a faster manner with a streamlined process.
- Enables users to select the self-service patching windows in a cost-effective method.
- Admins and asset owners have access to post-patching data for the respective assets (servers).
- Operational excellence by automating the patching process and reducing system downtime.
Common Problems with the Manual Patching Process
Irrespective of any industry, keeping all of the IT systems updated and patched is important. Executing the patch management process manually is exhaustive task, as there are several common patch problems organizations face.
Monitoring
Manual monitoring is one of the key challenges during the patch management process. Implementing the connectivity between third-party tools to the business systems, obtaining approval from the enterprise infrastructure security team, and managing third-party license tools are some of the tedious tasks.
There’s a higher chance of missing the patches if, for example, you don’t have sufficient disk space, or if the system health is not good the patches will fail.
If you have limited servers, you can still manually monitor the disk space or server health checks proactively. However, when you have hundreds or thousands of systems in an enterprise business, it’s not recommended to do this manually per operational excellence best practices. You should have automated jobs and processes in place to monitor systems and report if something is wrong.
Time
Manual patching processes can take longer than an automated process with less control. It’s also a time-consuming process for admins to understand which system are patched and which are not.
Cost
Using third-party tools to patch the servers can be costly due to license fees and support. This is especially true if you use multiple third-party tools to achieve vulnerable free environment, as managing the tools adds cost to the business.
Flexibility
With the legacy (traditional) patching model, end users and business owners don’t have the ability to schedule patching for their assets whenever they want. Asset owners must go with the standard schedule window, which may or may not work for all of the servers based on application releases and demos.
Architecture
Figure 1 below shows the current high-level architecture and how Jenkins and Chef tools were used in a legacy patching model. The way the current architecture works, system admins used to run the Jenkins patching job manually by logging in to the Jenkins console, and the respective job attaches a tag in Chef nodes.
Based on the tag, Chef server executes the patching process of installing patches, and the respective servers will get updated.
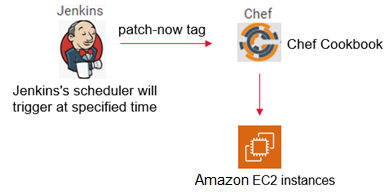
Figure 1 – Manual patch process.
Challenges Faced in the Current Architecture
Patching the IT systems manually are adoptable only in a very small scale environment. In the case of larger enterprise IT infrastructure, vulnerability management becomes complicated as you need different maintenance window times, a different set of operating system versions, and no proper dashboard to analyze the patching metrics.
Following are the challenges faced with the existing manual patch process model.
Manually Triggering the Jenkins job
The system administrator needs to trigger the Jenkins job manually on each window. There is no automated or scheduled process for triggering the patching.
Chef Nodes (Server) Issue
If for any reason the server is not available on Chef, that server will not be patched and will be vulnerable. There is no way to identify which server has Chef issues until and unless the administrator analyze the Enterprise Vulnerability Management (EVM) tool to generate a vulnerable report.
The EVM tool internally uses a Qualys Cloud Agent to collect the data.
Manually Exclude Servers from Patching
With the legacy patching process, there’s no easy way to exclude the servers from patching for any business reason. Administrators have to log in to Chef and attach the exception tag, or create a Jenkins job to attach the exception tag each time (on a weekly basis).
If you miss the exception tag, it could impact the business, so administrators must keep checking if exception tags are added and there is no alert mechanism if any server exception is revoked.
Vulnerabilities Not Remediated
There is high impact with this legacy patching process because the majority of vulnerabilities exist on the systems even after performing monthly patching. Sometimes nodes are not getting registered in Chef due to broken agent. Also, there is no mechanism of pre-patching activities like disk space or server health checks monitoring.
No Post Patching Report or Dashboard
System admins don’t have any control once the Jenkins job is triggered. There will be no post-patching report to analyze how many servers are patched and how many failed. It can also a challenge for business and asset owners to determine whether the systems are patched or not.
High-Level Patching Flow of Proposed Solution
To build a fully automated end-to-end patching solution, different components are needed on the respective stages in the entire process of patch management. The diagram below represents the components included in the patching solution.

Figure 2 – Patching process components.
Qualys Scan
The Qualys Cloud Agent will be installed on all Amazon Elastic Compute Cloud (Amazon EC2) instances. It scans on a daily basis and stores the vulnerability data in the EVM tool, which has a centralized repository for different business units. This will be the source of truth for vulnerable data to do further analysis and remediation.
AMI Hardening
For Auto Scaling enabled instances, an Amazon Machine Image (AMI) will be built and released for all accounts. By running the updated AMI script, brand new instances will be triggered and old instances will be terminated once the new health check is passed.
Patching Exclusion
For any reason, if the business team decides not to patch the server then asset owners should create an exception request in the EVM tool. It needs to be approved by business leaders to exclude the server from patching.
Automated Patching
Patching will be triggered based on Tech Mahindra’s defined maintenance window and based on exception tags; servers will be excluded.
Reporting
Once the patching is done, results will be stored in an Amazon Simple Storage Service (Amazon S3) bucket for further reporting purposes. This is done by comparing the before and after patching results and will be displayed in the dashboard.
Solution Design
To construct an end-to-end automated patching process, respective AWS native services are integrated into Tech Mahindra’s solution.
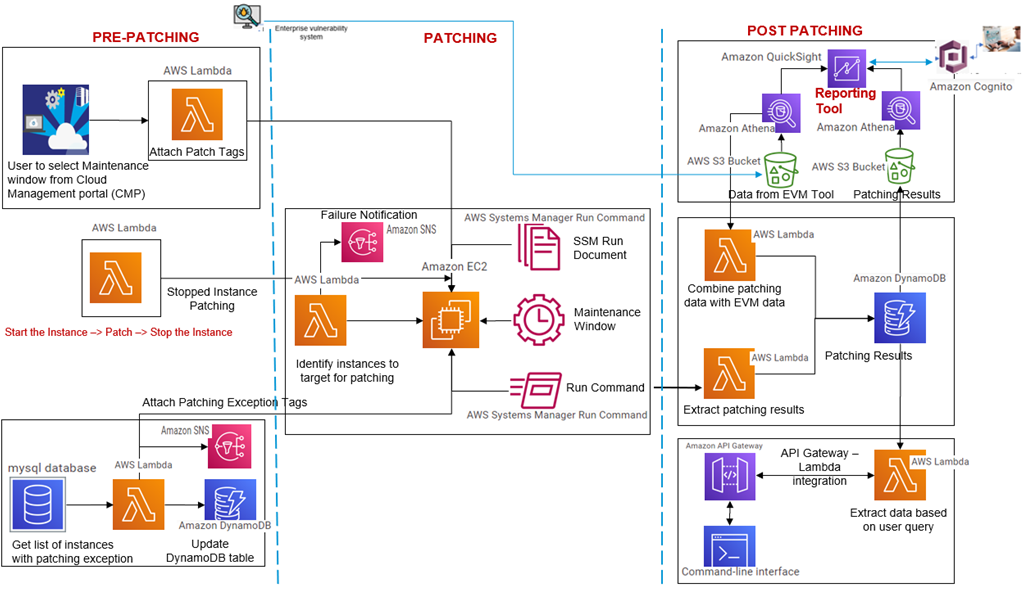
Figure 3 – Automated patching process.
Tech Mahindra used the following AWS services to implement the automated patching solution:
- Amazon CloudWatch: CloudWatch events rules are used to create event-based patch schedulers.
- AWS Lambda: Lambda is an event-driven, serverless computing platform used to make the patching solution more effective. Following are different Lambda functions executed for different functionalities:
- Create or attach the patching tags.
- Attach the exception tags.
- Attach the date of last patching.
- Remove the patching tag once patching is done.
- AWS Systems Manager Run Command: A centralized Run command document is used for both Linux and Windows across the accounts. It’s easy to update and modify based on requirements, and is also easy to deploy. Based on Tech Mahindra’s defined maintenance window, the Run command will trigger the patching on assets belonging to a respective window time.
- Amazon DynamoDB: Patching exception systems that was approved by business leaders are stored in a DynamoDB table.
- Amazon Simple Notification Service (SNS): SNS sends the notification for the servers that are not approved to be part of exceptions list.
- Amazon API Gateway: This is used by administrators to collect the post-patching analysis report via the AWS Command Line Interface (CLI). There’s no need to wait until the data is populated in the dashboard, meaning admins can quickly get the data and analyze the patching results.
- Amazon S3: S3 is used to store pre- and post-patching data as a source of truth for further analysis.
- Amazon Athena: Athena is an interactive query service that makes it easy to analyze data in S3 and visualize the report in an Amazon QuickSight dashboard.
- Amazon QuickSight: Pre-patching data from the EVM tool is pushed to S3, while post-patching data from AWS Systems Manager Run command history is also pushed to S3 and queried for the final patching report in QuickSight for reporting purposes. The QuickSight dashboard is integrated with Amazon Cognito and SAML federation for end users, and helps admins understand how many servers are updated, how many are not updated, and how many packages are updated.
- Amazon Cognito: This provides authentication, authorization, and user management for your web and mobile apps.
Implementing the Automated Patching Solution
The automated patching process is sub-divided in to three stages to execute certain set of tasks.
Stage 1: Pre-Patching
Pre-activity readiness is one of the most important factors to make this activity a success.
- Collect the disk space/health check/repo issue servers: As part of Tech Mahindra’s solution, pre-patching scripts will monitor the disk space, system health check, SSM availability, and more. If any errors are notified, it corrects the issue as a one-time or permanent fix based on the trend before patching, as this could be one of the root cause for failure in patching.
.
The pre-patching script also has the ability to pull the repository issue servers if, for example, any server is configured with incorrect repo URL in the system. In that case, the wrong repo URL is notified the solution corrects the repo issue to avoid the patching failure on system.
. - Self-service patching: Once the user selects the patching window from the self-service portal, a Lambda function (patch Lambda) pulls the data from the portal and the action-bot attaches the patching window tag to the respective systems.
. - Exception tags: Once the asset owner raises the exception request in the EVM tool, it will be approved or rejected. A Lambda is triggered on a scheduled time basis that captures the approved exception data from the DynamoDB table. With the help of the action bot, it assigns the exception tag to the systems. Note that the exception tag will be in date format, like from which date to which date the system should not be patched.
. - Stopped instance patching: The solution uses another Lambda function to start the system which has patching tag but in stopped state. In such cases, the Lambda will start the server 15 minutes before the patching, and it will stop the server once the patching is done. For this, Tech Mahindra added the crontab to the systems.
Stage 2: Patching
Once the pre-requisite for patching activity is completed, the main objective to patch the instances is executed using AWS native services.
- Identify the instance maintenance window: Once the maintenance window kicks in, Lambda identifies instances that are having the patching tags. Based on that, it assigns the
ssm-patch-nowtags and excludes the exception servers. This takes a couple of minutes to complete the tagging process.
. - Run command: The Run command document developed to patch the Linux and Ubuntu systems captures data from each step. For example, it captures the current operating system version, the latest kernel available for update, how many kernels are available after reboot, and more.
.
For Windows, the solution uses theAWS-InstallWindowsUpdatescommand, which will run against the servers that are having thessm-patch-nowtag and install all of the latest updates and patches on the systems. Then, it reboots the systems. This process takes about 15 minutes for Linux/Ubuntu and 40 minutes for Windows.
Stage 3: Post-Patching
Despite automating the patching process, notifications, reports, and dashboards adds value to the client and helps run the IT operations effectively.
- Extracting the patching results: When the patching document is completed, it triggers the Lambda to pull the results from the Run command output and stores it in S3. Lambda captures the vulnerable data during pre-patching and also stores that in S3.
. - Dashboard: Once you have the post-patching data available in S3, Amazon Athena is used to query against to pre- and post-patching data in S3 and display the data in a QuickSight dashboard. Sample patching report is shown below.

Figure 4 – Sample post-patching report.
Summary
Many organization spends high amounts of time, manpower, and cost on vulnerability remediation but are still not having success for a variety of reasons.
It’s important for an organization to have a good patching mechanism, and maintain software and operating system patches with good security posture to avoid cyberthreats for the business to run successfully.
In this post, we showed you how Tech Mahindra designed and developed an AWS Systems Manager patching solution using AWS native services. This solution helps businesses overcome the obstacles of remediating system vulnerabilities by providing end-to-end automated patching with accurate post-patching analysis report via Amazon QuickSight.
.

.
Tech Mahindra – AWS Partner Spotlight
Tech Mahindra is an AWS Advanced Consulting Partner and MSP that specializes in digital transformation, consulting, and business re-engineering solutions.
Contact Tech Mahindra | Partner Overview
*Already worked with Tech Mahindra? Rate the Partner
*To review an AWS Partner, you must be a customer that has worked with them directly on a project.