AWS Partner Network (APN) Blog
Improving Application Performance with No Code Changes Using Heimdall’s Database Proxy for Amazon Redshift
By Sudhir Gupta, Sr. Solutions Architect at AWS
By Erik Brandsberg, CTO at Heimdall Data
 |
 |
Concurrent singleton DML operations, network latency, and slow repetitive queries are often the cause of slow performance of data warehousing applications.
Whether there’s network latency or data latency, operators are looking for solutions that provide fast response time to end-users.
Heimdall Data is an AWS Partner Network (APN) Advanced Technology Partner with the AWS Data & Analytics Competency that offers a database proxy to transparently improve Amazon Redshift response time.
If you want to be successful in today’s complex IT environment, and remain that way tomorrow and into the future, teaming up with an AWS Competency Partner like Heimdall Data is The Next Smart.
In this post, we’ll demonstrate how to use Heimdall Data to improve the performance of an application that connects to Amazon Redshift, without changing the application code.
The Heimdall database proxy improves application performance by three techniques:
- Batch processing
- Automated client-side query caching
- Connection pooling and multiplexing
Batch Processing
Some applications generate a large number of singleton INSERT statements and execute concurrently to load data into Amazon Redshift.
Too many concurrent singleton INSERT statements cause undesirable commit overhead to Redshift, slowing down application response times.
One of most impactful features of the Heimdall proxy for Redshift is batching DML INSERTs at the data access layer in front of Redshift, as shown in Figure 1.
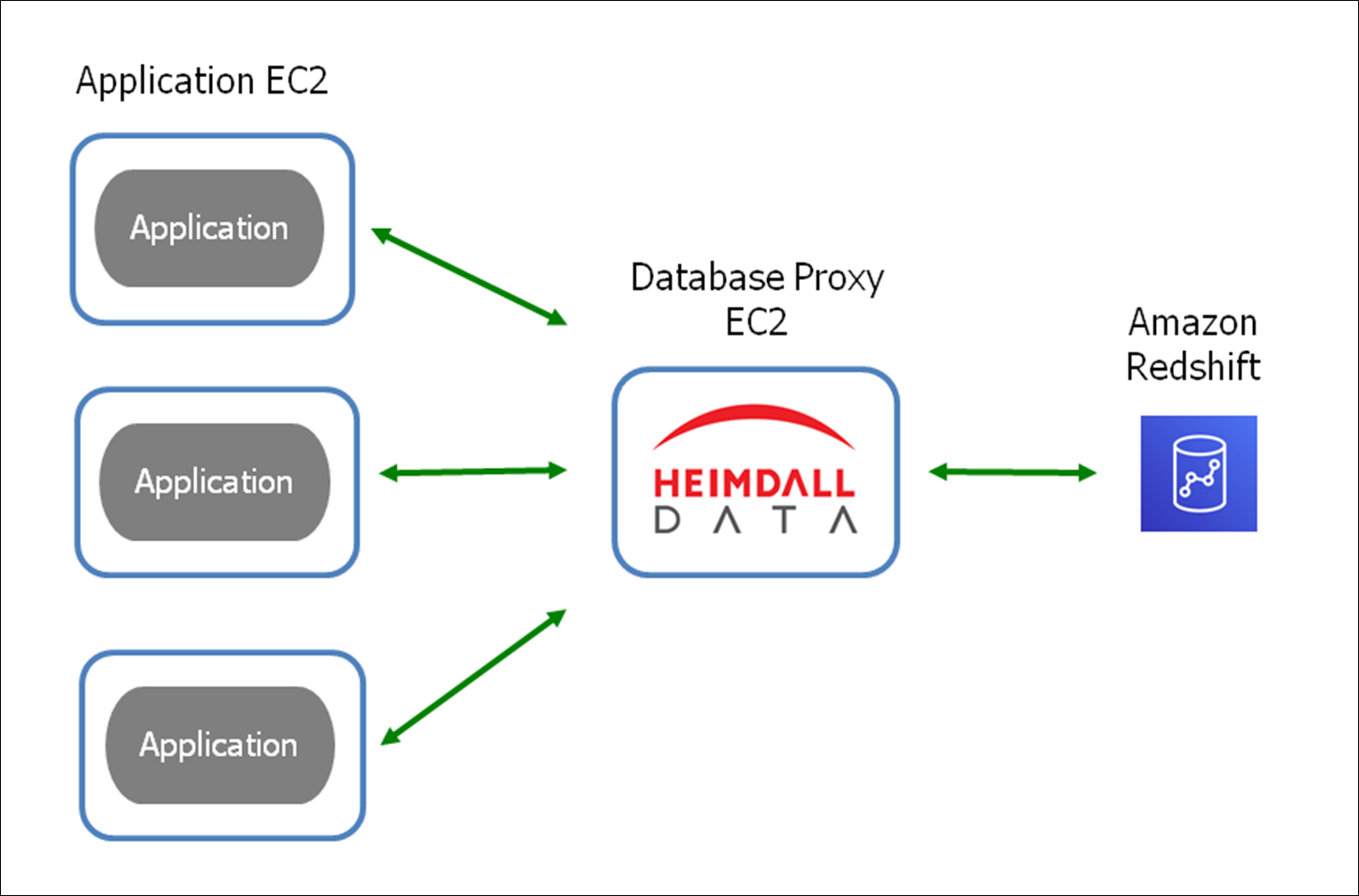
Figure 1 – Heimdall Data high-level diagram.
The Heimdall proxy improves database write performance by transparently batching single-row data ingestion.
Batch processing results in:
- Improved application response time due to fewer commits.
- Improved INSERT throughput performance. To learn more, check out Heimdall’s technical webinar.

Figure 2 – Heimdall Data batch processing flow diagram.
The following steps explain how batch processing works, as shown in Figure 2:
- DML operations are queued up in the Heimdall database proxy.
- Queue is sent to a user-configured batched size (Figure 3 below).
- Batch is sent as a single transaction to Redshift.
If there’s a failure during the batching process, Heimdall detects the faulty SQL statement and restarts the batch excluding that statement. That is, exceptions are logged, removed from batch, and the transaction is restarted.
Note that Heimdall batch processing is not so ideal when concurrent writes and reads happen against the same table, on the same thread.
AWS Installation and Setup
Download the Heimdall proxy from AWS Marketplace. The Amazon Machine Image (AMI) includes both the proxy and Central Console. For more information, see Heimdall’s technical documentation.
To configure batch processing, these fields should be filled out on the Central Console’s Rules tab, as shown in Figure 3:
- Regex rule.
- SpoofedResult: Integer value of how many rows were changed when spoofing.
- HoldUntil: Inserts a condition to hold the thread.
- Action: Batch processing is under the “Async Execute” feature.
- Frequency of batching (in seconds).
- Batch size (number of queries).

Figure 3 – Batch processing configuration.
Check out Heimdall’s technical webinar on how they improved performance 1,000x through INSERT batching.
Automated Client-Side Caching
Business intelligence (BI), dashboard, and visualization tools often execute repetitive queries. These tools will notice a huge performance boost with automated client-side caching feature of Heimdall Data.
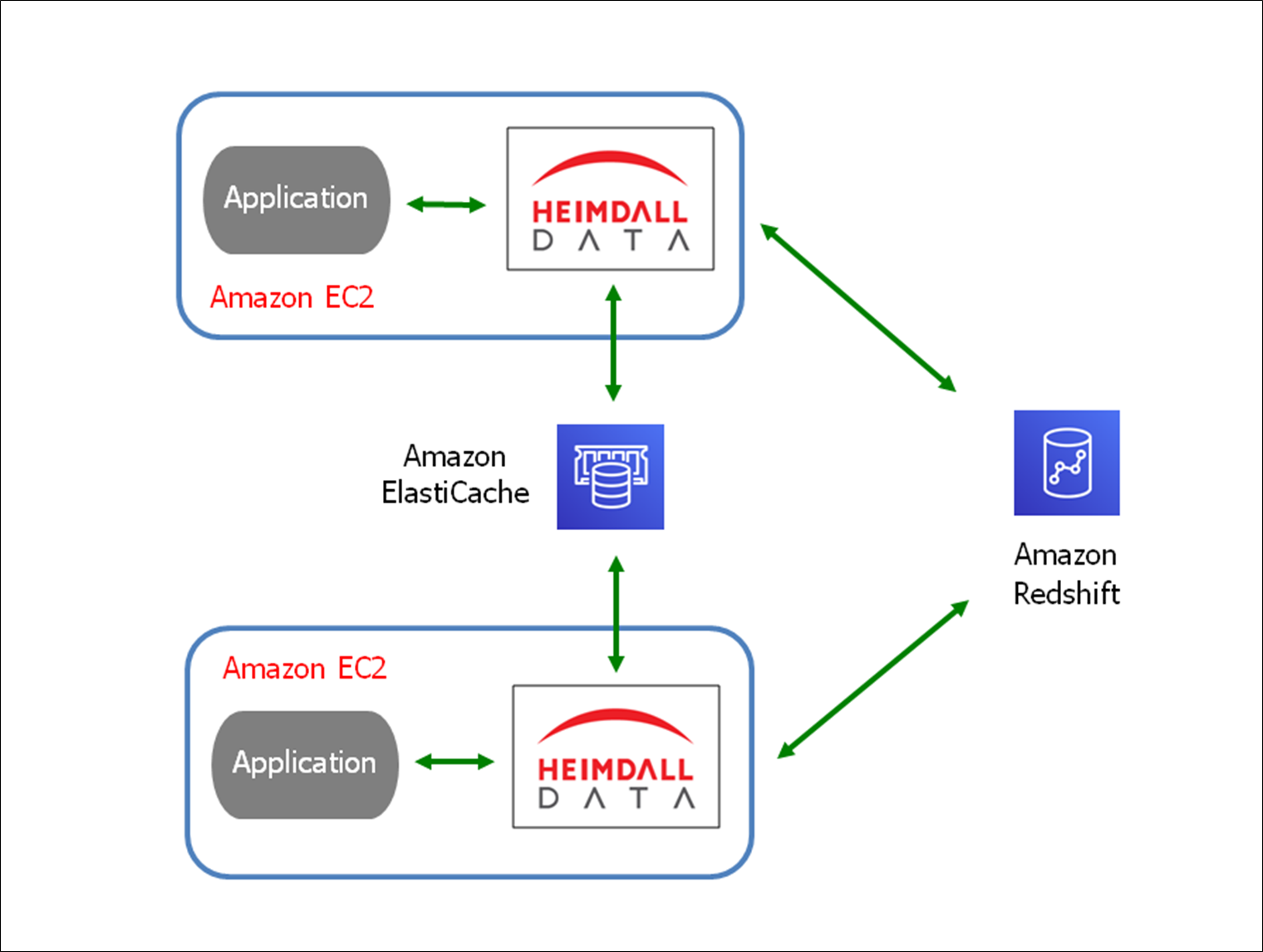
Figure 4 – Client-side query caching.
Amazon Redshift provides query result caching, but Heimdall extends the caching capability one step further. Heimdall complement Redshift’s cache as a “cache in front of cache” with the following benefits:
- Removes network latency by caching data at the client side. The Heimdall database proxy can be distributed and deployed across multiple applications, running on Amazon Elastic Compute Cloud (Amazon EC2) instances. When Heimdall caching is configured in front of Tableau dashboards, for example, customers have seen that response time reduced from 17 seconds to one second.
. - Automating caching and invalidation. Distributed architecture of Heimdall Data allows caching to be scalable, while acting as one cache cluster. Caching can be completely automated and configurable per query.
For more information on how to configure automated SQL caching with Heimdall, read this post on the AWS Database Blog: Automated Query Caching for Amazon RDS, Aurora, and Redshift.
Connection Pooling and Multiplexing
Like Heimdall auto-caching, connection pooling and multiplexing can save you Redshift costs by improving processing power.
It’s important to maintain the correct ratio between application and database resources. Each connection to Redshift takes valuable resources that can be better utilized for active queries. Therefore, it’s desirable to reduce the total number of connections to Redshift.
There are two Heimdall techniques that reduce connection overhead:
- Connection Pooling: This allows multiple client connections to be associated to a Redshift connection. When a connection is established from a client, an existing connection is picked from the existing pool, instead of a new connection being established.
.
While the client connection is open, this mapping remains. When the client-side connection is closed, the Redshift connection is kept open and returned to the pool for reuse. This reduces CPU and latency for backend connection establishment, and does not reduce the total number of connections from clients to the server, but makes the overhead lower on Redshift.
. - Connection Multiplexing: This is an extension of pooling, and instead of associating an entire client connection with the back-end it dispatches individual queries or transactions to connections in the connection pool.
.
As client connections are often idle, multiplexing allows for more “active” client connections to Redshift. The net result is, 1) lower total memory overhead on Redshift; 2) more active queries processed at one time; and 3) reduced Redshift costs. Benefits will vary based on the application workload.
Summary
Rewriting an application code for performance optimization generally requires a significant amount of effort. Also, IT and development groups using third-party applications like Tableau may not have access to the application code.
Heimdall’s database proxy solution offers a flexible and cost-effective alternative to rewriting your application for performance and scale.
Heimdall transparently provides SQL control and visibility to the application owner without (re)writing a single line of code. Our proxy provides various techniques, based on the application traffic pattern, to improve the response time of application connecting to Amazon Redshift.
To get started with Heimdall Data, download a free trial from AWS Marketplace.
Resources and links:
- Heimdall Data website
- AWS Database Blog: Automated Query Caching with Amazon RDS, Aurora, and Redshift
- Heimdall Proxy for Amazon Redshift Technical Webinar
- Contact: info@heimdalldata.com
.
|
Heimdall Data – APN Partner Spotlight
Heimdall Data is an AWS Competency Partner. It is a SQL database proxy for Amazon Redshift, Amazon RDS, Amazon Aurora, and Amazon ElastiCache. Heimdall is transparently deployed to improve your read and write queries. No code changes are required.
Contact Heimdall Data | Solution Overview | AWS Marketplace
*Already worked with Heimdall Data? Rate this Partner
*To review an APN Partner, you must be an AWS customer that has worked with them directly on a project.