AWS Partner Network (APN) Blog
VMware Cloud on AWS Disaster Recovery with Amazon FSx for NetApp ONTAP and SnapMirror
By Ben Lipman, Sr. Solutions Architect – VMware Cloud on AWS
By Jonas Werner, Specialist Solutions Architect – VMware Cloud on AWS
By Kiran Reid, Sr. Partner Solutions Architect – AWS
By Ziv Klempner, Sr. Specialist Solutions Architect, Migration Workloads – VMware
The majority of modern businesses depend on the proper functionality and availability of their IT systems. It is therefore of vital importance to safeguard these systems in order to ensure business continuity in the event of a disaster.
In on-premises data centers, VMware virtualization and NetApp ONTAP storage are widely adopted solutions. The release of Amazon FSx for NetApp ONTAP and support for FSx for NetApp ONTAP for VMware Cloud on AWS give customers a new option for disaster recovery (DR).
These solutions allow for virtual machine (VM) data to be copied from an on-premises environment to AWS using NetApp SnapMirror. Once in AWS, the VMs can be imported into vCenter in a VMware Cloud on AWS environment used as a DR destination.
In a previous AWS blog post, we discussed design considerations for disaster recovery with VMware Cloud on AWS, and we followed that up with a post about addressing multiple DR SLAs with VMware Cloud on AWS using VMware Site Recovery and VMware Cloud Disaster Recovery.
Customers can use VMware hypervisor capabilities to expose virtual disk snapshots, changed block tracking, and API-based data protection access to DR systems. In addition, customers can leverage DR tools such as agents within each virtual machine operating system (OS) for additional functionality.
With the announcement of Amazon FSx for NetApp ONTAP (FSx for ONTAP) integration with VMware Cloud on AWS, customers have the option to provide supplemental storage for datastores and have another DR option for VMware-based workloads.
In this post, we’ll look at how customers can use FSx for ONTAP as a target to replicate their on-premises VMware workloads for both migration and disaster recovery using SnapMirror.
Common Challenges of Disaster Recovery
Let’s review the current challenges when planning for disaster recovery and how SnapMirror can address them. Planning for disaster recovery involves trade-offs between recovery time objective (RTO), recovery point objective (RPO), and cost. As RTO and RPO are reduced, the costs increase. DR decisions should weigh the cost and benefits of each option against business needs.
Traditional DR tools target individual virtual machines which are onboarded to DR protection plans. Protection utilizes agent software or VMware data protection API plugins to seed VM data and maintain changed block updates. In some cases, challenges may arise.
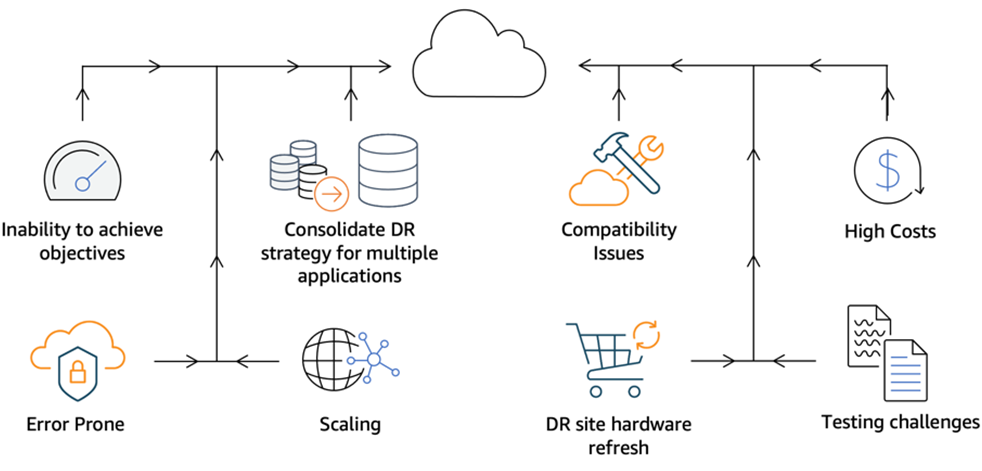
Figure 1 – Common disaster recovery challenges.
Cost
- High costs of duplicate infrastructure and licensing: You may be paying high costs for duplicate compute, network, and software licenses, in order to maintain a secondary DR site—without knowing if you’ll ever need to use it. Utilizing expensive high-performance storage as a DR storage tier (where performance is only needed in case of a disaster) unnecessarily raises costs. Storage copies may not be efficiently deduplicated, compacted, and compressed which leads to further increased cost.
. - Scaling: On-premises DR solutions are often difficult and expensive to scale up or down when there are changes to your primary environment. Organizations usually invest up front to pre-provision DR infrastructure according to expected growth in future years.
Complexity
- Server compatibility issues: When replicating servers across dissimilar infrastructure, such as from on-premises or other clouds into AWS, server conversions are required to ensure the replicated servers can run natively on AWS. This includes modifications to hypervisors, drivers, and other variations.
. - Inability to achieve objectives: Difficulty in achieving the required RTO/RPO during drills, or having unreliable test results.
Reliability and Consistency
- Testing challenges: Many organizations avoid frequent testing due to concerns about complexity of testing, or concerns that drills will disrupt their source environment. Infrequent testing erodes trust in the DR mechanism.
. - Error prone: Risk of missing newly-provisioned VMs in the protection plan and having gaps in protection (manual steps to ensure complete DR coverage). External storage such as in-guest iSCSI and Raw Device Mappings (RDMs) might be invisible to hypervisor-based DR systems.
Disaster Recovery Methodologies
When choosing a recovery solution, customers have different options available. In this section, we’ll discuss agent, agentless, and array-based solutions.
Agent
In this scenario, no hypervisor integration or access is needed, nor is there a reliance on VMware snapshots. Most of today’s image-based backup systems provide the same granular file restoration benefits as nonimage-based systems.
Agent-based backups are loaded in the guest OS stack and offer increased control and visibility of the host system that is not immediately available to an agentless backup. Agent-based backups can facilitate data-consistent protection for locked filesystem objects Volume Shadow Copy (also known as Volume Snapshot Service or VSS) and database snapshots.
Considerations to this approach are agent licensing costs, ensuring the in-guest agent is installed on each server. This should be done when the server is commissioned, otherwise a reboot may be required due to the snapshot driver residing on the OS kernel.
Depending on the agent, it can provide an overhead on the guest but also the hosts and datastore. Concurrency of agent-based jobs can also be limited.
Agentless
All major processes are performed by the hypervisor. Hence, a virtual machine becomes a configuration description accompanied by disk images containing guest data. As a result, it’s possible to back up an entire VM at once, at image level, without traversing the guest file system. All of the resources needed by a backup software can be accessed through a hypervisor.
Additionally, agentless backups require network resources to transmit application commands across the network as well as data between the target and storage device. There is hypervisor integration and compatibility which is not feasible for some hyperscalers due to the VMware Installation Bundle (VIBs) required. Protection is crash-consistent without coordination with the VM guest (VSS, DB snapshots).
Storage Array Replication
Array-based replication is the process of copying data via a storage-based snapshot, and then replicating that snapshot data to store it in additional sites. This type of data replication is performed at the physical or virtual storage array level and doesn’t rely on hypervisor snapshots.
Array-based replication products are provided by a specific storage vendor with most of the overhead placed at the storage array.
Storage array replication can provide storage-level deduplication and compression prior to replication, resulting in less data being replicated. Customers are able to cutover the entire environment when required for testing with little impact to the hypervisors and guests.
Storage array replication is not without considerations. For example, customers usually replicate the entire datastore with a single policy which does not lend itself well for setting granular settings.
Furthermore, there is a cost of running a second storage array in the DR location for the purposes of mirroring data from the protected site. Data synchronization may require agents to quiesce guest operating system and disks to ensure the copied data is viable otherwise it will be crash-consistent.
Building a DR Strategy with NetApp SnapMirror
The foundation for any successful disaster recovery solution is reliable data synchronization between the protected site and the DR location. NetApp provides this in the shape of SnapMirror as a native ONTAP feature.
NetApp SnapMirror employs block-level replication for quick and efficient data transfer, so you get high data availability and fast data replication across ONTAP systems, whether you’re replicating from on-premises to AWS, or between two Amazon FSx file systems across AWS regions.
Replication can be scheduled as frequently as every five minutes, although intervals should be considered based on RPO, bandwidth, and latency considerations.
SnapMirror uses NetApp Snapshot technology as the basis of its replication process, which first replicates a full copy of the source data to the target and subsequently replicates only the changed blocks since the last replication event, thus saving on transfer and storage costs.
Users can specify a synchronization schedule ranging from a few minutes to hours, at which frequency data changes from the source will be transferred over to the copy.
Refer to the below diagram for a sample solution architecture capable of supporting migration of virtual machines through the use of NetApp ONTAP SnapMirror.
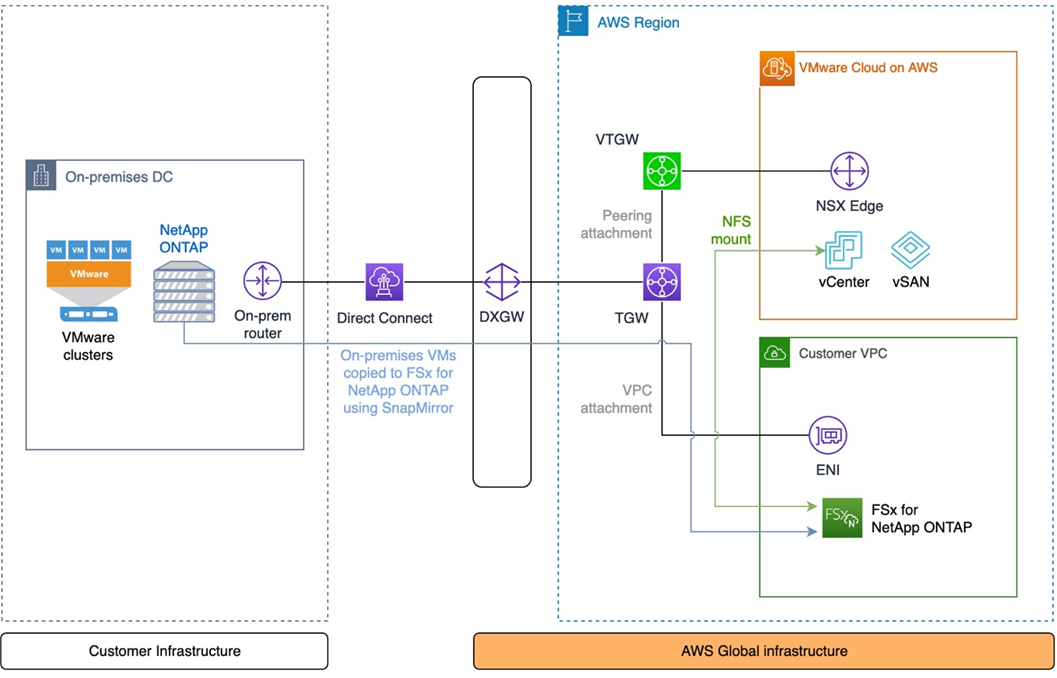
Figure 2 – DR and migrations of VMs through the use of NetApp ONTAP SnapMirror.
NetApp ONTAP is frequently used on premises in conjunction with VMware environments, both for the purpose of storage for virtual machines as well as providing file shares.
VMs and files stored in ONTAP volumes on premises can easily be replicated to FSx for ONTAP in AWS over a private connection like AWS Direct Connect or alternatively over a virtual private network (VPN) connection. This allows for a convenient and painless synchronization of data from on premises with AWS used as the DR location.
Prior to failback, SnapMirror automatically resynchronizes data from the recovery site back to the primary site.
In the event of a disaster in the on-premises location, any volumes synced to the FSx for ONTAP service can be switched from read-only to read/write and mounted over Network File System (NFS) protocol to an existing or newly-created VMware Cloud on AWS environment.
Once a volume has been attached to VMware Cloud on AWS, any virtual machines residing on the volume can be registered with vCenter either manually or automatically by using scripts. For instructions on migrating to FSx for ONTAP using NetApp SnapMirror, see the documentation.
Addressing Common DR Challenges
Cost
Compared with owning or renting a second data center location for disaster recovery, leveraging FSx for ONTAP and VMware Cloud on AWS can be an effective step towards lowering overall total cost of ownership (TCO) while maintaining a high level of DR preparedness.
Virtual machine data can be configured to sync according to the RPO requirements of the business, and the VMware Cloud on AWS environment can be run on a minimum configuration to meet the RTO requirements and still reduce running costs to a minimum.
Alternatively, VMware Cloud on AWS can be deployed on-demand to completely remove the running costs of a second VMware environment.
The ability of FSx for ONTAP to scale throughput, IOPS, as well as storage capacity helps right-size the storage to meet the evolving, changing, and growing needs of the business. It does so by enabling customers to scale throughput up or down, change IOPS, and scale up storage on demand, whether that be for DR purposes or secondary storage for VMware Cloud on AWS.
Note that data transfer through AWS Transit Gateway (TGW) and VMware Transit Connect (VTGW) will be charged according to the AWS Transit Gateway pricelist.
Complexity
In case of a disaster, complexity can have a significant impact on RTO; it can also discourage frequent DR testing which is easy to perform with FlexClones.
Both VMware Cloud on AWS and FSx for ONTAP are offered as managed services and therefore come with support and a reduced need for undifferentiated heavy lifting to maintain infrastructure.
Both services allow IT administrators who are already familiar with VMware and NetApp ONTAP to continue using these solutions also in AWS. The combined use of these services removes the need for a third-party data replication solution. It does still require orchestration of the failover to be done either manually or using other tools.
If customers are not using Amazon FSx for NetApp ONTAP as supplemental datastores, and if a fully managed solution is preferred, consider VMware Cloud on AWS add-ons such as VMware Site Recovery and VMware Cloud Disaster Recovery.
Reliability
When a primary site experiences an outage and the decision is made to failover to the DR location, it’s vital that all components needed to make that transition functions as expected. VMware Cloud on AWS come with an SLA of 99.9% for standard cluster deployments, and FSx for ONTAP is offered with a 99.99% SLA for multi-Availability Zone (AZ) deployments.
It’s also possible and recommended to test DR plans regularly. For testing purposes, virtual machine data can be copied to a separate volume in FSx for ONTAP and paired with a permanent or on-demand VMware Cloud on AWS software-defined data center (SDDC). This ensures DR plans are always kept up to date and steps for implementation are well rehearsed.
Summary
Amazon FSx for NetApp ONTAP provides a reliable, cost-effective, flexible, and familiar solution for on-premises ONTAP storage environments to leverage VMware Cloud on AWS for disaster recovery.
Customers not using Amazon FSx for NetApp ONTAP as supplemental datastores and who prefer a fully managed solution can make use of VMware Cloud Disaster Recovery or VMware Site Recovery for their disaster recovery needs. Most customers have several tiers of workloads and can balance cost optimization with performance by combining several DR methodologies.
Resources: