AWS Partner Network (APN) Blog
Addressing Multiple Disaster Recovery SLAs with VMware Cloud on AWS
By Kiran Reid, Partner Solutions Architect – AWS
By Mike McLaughlin, Technical Marketing Architect – VMware
 |
In a previous post, we discussed design considerations for disaster recovery (DR) with VMware Cloud on AWS and introduced disaster recovery as a service (DRaaS) offerings that VMware has available: VMware Site Recovery and VMware Cloud Disaster Recovery.
In this post, we’ll focus on these two offerings and the potential for deploying either one or both together for a more robust DR to VMware Cloud on AWS solution. Either approach helps you address multiple Service Level Agreements (SLAs) and Service Level Objectives (SLOs) to meet your individual business requirements.
Both solutions provide robust yet simple methods within the DR plans to map existing production networks onto the appropriate DR networks configured in VMware Cloud on AWS.
This provides a documented and orchestrated capability to bring up application virtual machines (VMs) in the Software Defined Data Center (SDDC). It also provides the appropriate connectivity to help your business test DR capabilities or provide business continuity following unplanned outages.
The architecture of the hybrid-cloud VMware DR solution integrates with existing VMware Cloud on AWS architecture. Learn more in this post about diving deep on the foundational blocks of VMware Cloud on AWS.
Understanding the Disaster Recovery Sequence
The diagram below shows the steps involved in executing a recovery of virtualized workloads.

Figure 1 – Disaster recovery sequence.
- Stage 1: Business as usual – At this stage, all systems are running production and working correctly.
. - Stage 2: Disaster occurs – At some given point in time, disaster occurs and systems need to be recovered. At this point, the Recovery Point Objective (RPO) determines the maximum acceptable amount of data loss measured in time. Depending on your application SLA and DR cost requirements, this could be 30 minutes, 4 hours, or longer.
. - Stage 3: Recovery – Here, systems are recovered and back online but not ready for production yet. The Recovery Time Objective (RTO) determines the maximum tolerable amount of time needed to bring all critical systems back online. This could be minutes or hours, or it could be longer and covers powering on VMs from recovery points (backup copies) or fix of a failure.
. - Stage 4: Resume production – At this stage, systems are recovered; integrity of the system or data is verified, and all critical systems can resume normal operations. The Work Recovery Time (WRT) determines the maximum tolerable amount of time needed to verify the system and/or data integrity.
.
Examples include checking databases and logs, making sure applications or services are running and available. Those tasks are usually performed by application administrator, database administrator etc.
The sum of RTO and WRT is the Maximum Tolerable Downtime (MTD), which defines the total amount of time that a business process can be disrupted without causing unacceptable consequences. This value should be defined by the business management team, Chief Technology Officer (CTO), Chief Information Officer (CIO), or IT managers.
VMware DRaaS Deployment Options for VMware Cloud on AWS
When looking at the Protected site, there are two key considerations for businesses that will drive their choice of VMware DR solution and respective SLAs:
- Recovery point cloud storage capacity and location. Will the recovery points be stored on the primary (SDDC vSAN) datastore, or will they be maintained on a secondary Scale-out Cloud Filesystem (SCFS) readily available to the SDDC?
. - Recovery Point Objectives. How often (frequency) will the recovery points be taken, and how long or how many will be retained? Both measures will drive the RPO SLA possibilities.
In turn, these choices will also drive the consumption of cloud-based resources for storage and compute needs and the potential to leverage the inherent elasticity of these cloud-based resources.
VMware Cloud Disaster Recovery
This solution provides a more dynamic and cost-effective, cloud-managed DR site approach that leverages SCFS for maintaining the recovery points and an on-demand and scalable SDDC deployment method.
Failover workloads can begin almost immediately from this recovery point, and storage vMotion proceeds automatically in the background to place the VMs into the VMware Cloud on AWS SDDC vSAN datastore. VMware Cloud DR has the trade-off of slightly larger (longer) RPO, SLAs, and potentially longer RTO logistics to build and scale the failover site.
VMware Cloud DR enables you to start with as little as 2-node Pilot Light environment, which provides an always-on way to run Tier-0 applications as well as critical utility VMs like secondary domain controllers. You can then scale up on-demand during the event of a disaster.
Using this approach, customers pay for 2-nodes until a disaster event requires them to scale up to more nodes and leverage VMware Cloud DR as the means to recover the VMs from the SCFS to recover their workloads.
If you’d like to know more, see the product page for details of the VMware Cloud DR solution and the associated pricing .
VMware Site Recovery
This solution leverages the basics of VMware Site Recovery Manager (SRM) and vSphere Replication (VR) components installed as VMs at each site (Protected and Recovery) to establish VM replication recovery points in the destination VMware Cloud on AWS SDDC vSAN datastore.
This method of protecting the application VMs can provide lower RPO and potentially faster RTO at the cost of a persistent cloud operational footprint.
This approach also requires a provisioned SDDC to support the vSphere replication from the Protected site to the Recovery site. The SDDC will need to be provisioned to the appropriate size for the vSAN datastore to hold the desired recovery points.
Just like with the VMware Cloud DR Pilot Light environment, customers can start with as little as two ESXi hosts, and then provision more capacity when required to further reduce costs.
Details of the Site Recovery solution can be found on the product page.
VMware DRaaS Considerations
Both VMware DRaaS solutions are available to fail over to VMware Cloud on AWS for disaster recovery and provide similar methods for defining the Protected site (either on-premises or in an alternate SDDC).
They also establish Protection Groups (VMs that will be backed up to the cloud), and define DR plans (run books capturing the orchestration steps and details) that can be used to respond to the DR event. Considerations of when either of these solutions can be used can be seen below.
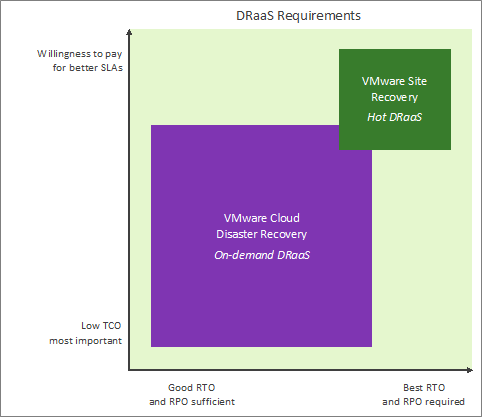
Figure 2 – Choosing the right solution.
Details of the similarities and trade-offs between these two VMware solutions are summarized in the table below.
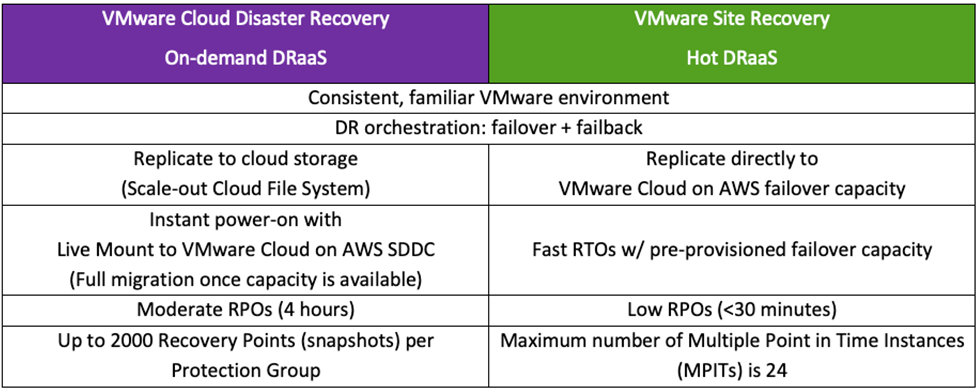
Figure 3 – Similarities and tradeoffs.
Using Both Solutions for Optimal DR Protection
The ideal solution for implementing disaster recovery to VMware Cloud on AWS involves a combination of both approaches. In this scenario, a smaller, always-on SDDC can be provisioned up front through VMware Cloud DR, and then be utilized with VMware Site Recovery to handle the more business-critical workloads that will benefit from lower RPO/RTO options.
This initial SDDC can be used as the Pilot-Light SDDC model for VMware Cloud DR for the remainder of the workloads that need to fail over, and can take advantage of the SCFS and scalable cloud deployment elasticity.
When the DR event has been mitigated, the cloud-based DR site can be reduced back to the smaller base footprint supporting both VMware Site Recovery and VMware Cloud DR.
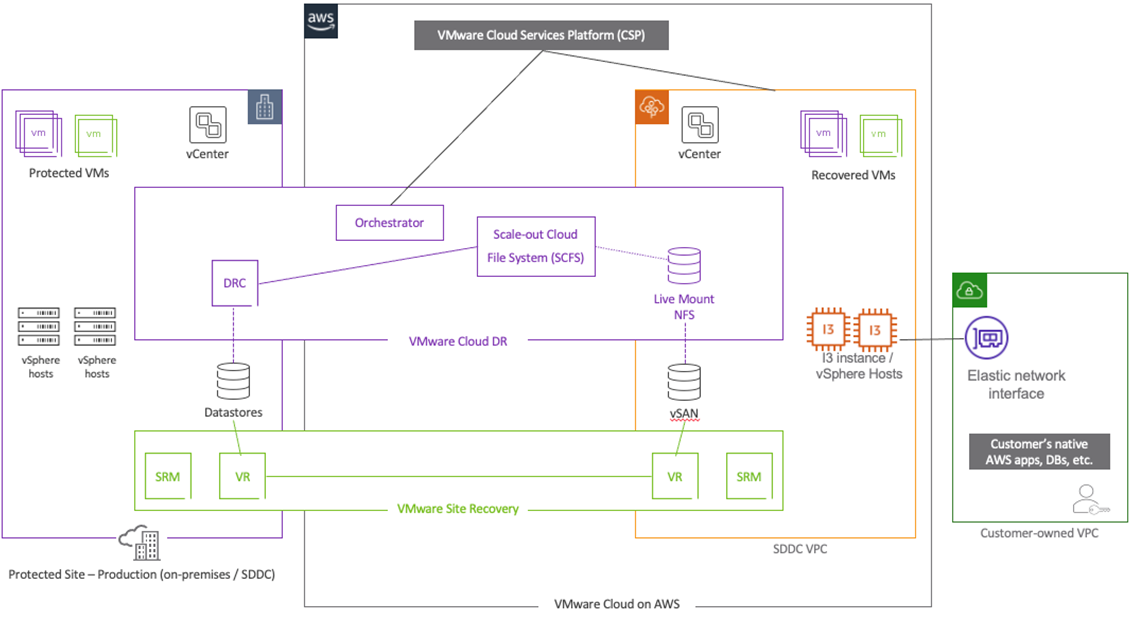
Figure 4 – Disaster recovery architecture diagram.
Summary
When you leverage VMware Cloud on AWS as your secondary data center, you can start small to prove the capabilities and begin providing immediate value and scale with cloud efficient economics to meet even the most demanding needs for a DRaaS solution.
With either, or both, of these disaster recovery solutions from VMware, it’s always best to check the latest information available online from VMware and AWS with respect to compatibility, sizing, and general cost considerations.
For more information, please contact your AWS or VMware account team or visit the AWS or VMware websites.