AWS Partner Network (APN) Blog
Design Considerations for Disaster Recovery with VMware Cloud on AWS
By Schneider Larbi, Sr. Partner Solutions Architect at AWS
By Kiran Reid, Partner Solutions Architect at AWS
 |
Customers who run VMware on-premises are incorporating VMware Cloud on AWS into their hybrid cloud strategy due to the immense benefits of using the AWS Global Infrastructure.
As organizations plan hybrid cloud strategies, disaster recovery (DR) is a vital consideration to ensure business continuity in the event of a disaster.
In this post, we discuss the architectural considerations and best practices for implementing disaster recovery using VMware Cloud on AWS. We’ll focus mainly on VMware Cloud on AWS and the VMware Site Recovery Manager (SRM) add on.
There are cases where disaster recovery is not properly architected which results in loss of service and failure to meet Service Level Agreements (SLAs) when a disaster occurs. This loss of service can cause financial and reputational damage to customers.
Disaster Recovery Options
To help understand what disaster recovery means, let’s refer to the Gartner definition:
“Disaster recovery is defined as (1) The use of alternative network circuits to re-establish communications channels in the event the primary channels are disconnected or malfunctioning, and (2) The methods and procedures for returning a data center to full operation after a catastrophic interruption (including recovery of lost data).”
With the above definition in mind, we’ll discuss the available types of disaster recovery available to customers and how VMware Cloud on AWS and its applicable services fit into this discussion.
VMware Cloud on AWS offers four levels of DR support across a spectrum of complexity and time. We’ll dive deep in these key areas: Backup and Restore, Pilot Light, Warm Standby in AWS, and Hot Standby Active/Active.

Figure 1 – The four DR options when running on AWS.
Backup and Restore
Within 120 minutes, a Software Defined Data Center (SDDC) can be ready to start deploying workloads into, and this is where on-demand disaster recovery is possible. The ability to spin up resources on-demand is a cost-effective approach preventing idle resources waiting for use.
At the on-premises end, backups are configured with backup repositories that can extend to Amazon Simple Storage Service (Amazon S3). To enable this, a VMware Cloud on AWS certified backup is required.
From there, backup data gets offloaded to the S3 bucket based on a zero-day value move policy which dictates the operational restore window.
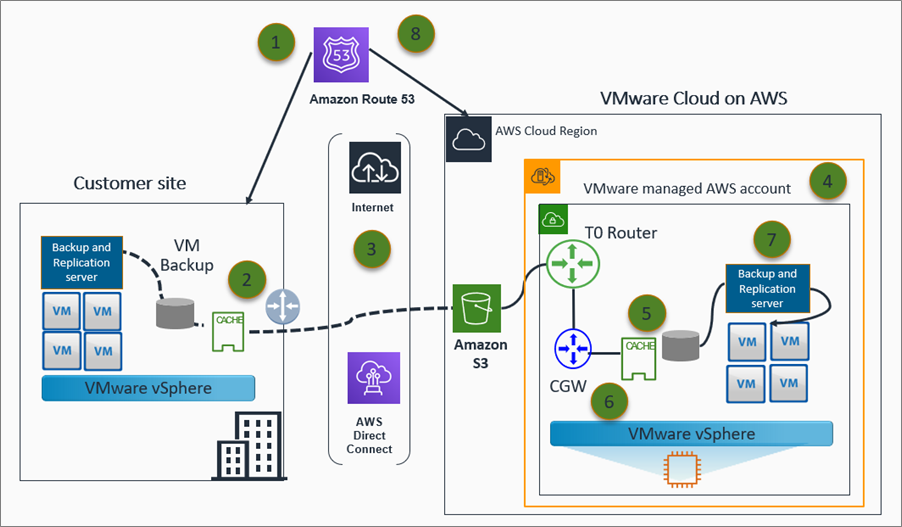
Figure 2 – DR using backup and restore architecture.
Here’s what you see happening in the architecture above:
- Amazon Route 53 handles DNS requests to the primary data center.
- The Backup & Replication server backs up workloads to the backup repository.
- Local data from the backup repository offloads to the Capacity Tier in Amazon S3 through AWS Direct Connect or the internet.
- The recovery process launches and configures the VMware SDDC cluster in the designated AWS recovery region through web portal automation scripts using vRA or vCLI.
- A new backup repository instance deployed and configured within the newly-created SDDC.
- Previous data stored in S3 is detected. The initial metadata and archive index sync is executed.
- Workloads recovered into the SDDC cluster and services are brought back online.
- Amazon Route 53 record setting updates to resolve requests to the new secondary data center in the cloud.
Pilot Light
With a Pilot Light solution, we are protecting an on-premises production environment on VMware Cloud on AWS as the recovery site. VMware Cloud on AWS enables you to start with as little as 2-node Pilot Light environment, which provides an always-on way to run Tier-0 applications as well as critical utility virtual machines (VMs) like secondary domain controllers.
You can then scale up on-demand during the event of a disaster. Using this approach, customers pay for 2-nodes until a disaster event requires them to scale up to more nodes and leverage a supported backup solution to recover their workloads.
Using this method, customers need to add a script to their recovery plans to automatically scale the hosts in your SDDC cluster as a best practice.
Another option is to leverage the new VMware Cloud Disaster Recovery (VCDR) which provides an affordable way to implement a Pilot Light architecture. Using VCDR, you don’t need to have any operational VMware SDDCs until a disaster before VCDR automatically deploys an SDDC and recovers your VMs to the new SDDC.
Additionally, VCDR enables a smaller subnet of SDDC hosts to be deployed ahead of time for recovering critical applications with lower Recovery Time Objective (RTO) requirements than a purely on-demand approach.
This model is more suitable for customers who do not have lower Recovery Point Objective (RPO) and RTO because it could take approximately two hours to set up the SDDC. It could also take time to restore your VMs depending on how many and the size of the virtual machines that need to be recovered.
Warm Standby in AWS
The next option is a warm standby approach, or provisioning the number of resources to recover your Tier1 or business critical services in the recovery site, and then scaling up to recover the less critical services with a longer RTO from backups using Elastic Distributed Resource Scheduler.
The benefits of using this solution are customers can provide protection for their critical business applications while still realizing costs savings. Customers pay for all their DR resources when required, and are able to non-disruptively perform DR testing on their applications with no impact to the business.
As previously mentioned, in the event of a disaster, or during DR testing, the customer can scale up and restore VMs from backups to meet their recovery requirements. VMware SRM can be used to achieve this option with VMware Cloud on AWS.
Hot Standby Active/Active
Active/Active deployments are used when customers choose to deploy all of the resources necessary to operate full production environments. This is useful for customers who wish to run Active/Active data centers and have low RTOs and RPOs.
In the event of a disaster, little or no infrastructure changes are required to ensure you can meet the immediate needs of the business. VMware SRM can be configured between on-premises and VMware Cloud on AWS to support this option.
Architecture Options for Disaster Recovery
Disaster recovery can be achieved using VMware Cloud on AWS as a recovery site with VMware Site Recovery Manager as the DR software.
Some organizations have been intimidated by the cost and complexity of traditional DR and do not have a recovery solution in place. These organizations can now use Site Recovery and VMware Cloud on AWS to implement DR in a cost-effective way.
Below are some supported architectural design patterns for implementing VMware Cloud on AWS with VMware Site Recovery Manager.
Establishing New DR from On-Premises to VMware Cloud on AWS
With the use of VMware Cloud on AWS and VMware Site Recovery Manager, organizations don’t need to have a like-for-like IT infrastructure to implement disaster recovery.
In addition, they do not need to purchase or rent a colocation data center. They can instead use VMware Cloud on AWS as a recovery site and consume resources on-demand or starting with a reservation of the minimum vSphere cluster on the AWS Cloud.
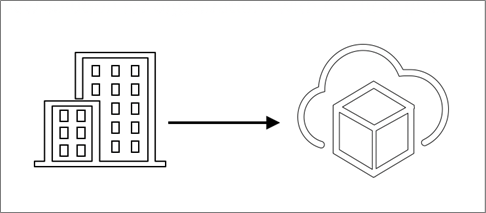
Figure 3 – Using VMware Cloud on AWS as a new DR target.
In this architecture, VMware Site Recovery Manager is enabled on VMware Cloud on AWS and the components are deployed on-premises and paired to the VMware Cloud on AWS SDDC.
This allows for VMs to be replicated to VMware Cloud on AWS over the public internet. Using AWS Direct Connect or a virtual private network (VPN) to connect to VMware Cloud on AWS for virtual machine replication, is also supported.
Replacing Existing DR Site with VMware Cloud on AWS
Organizations with existing DR data centers that have reached full capacity and can no longer procure the necessary hardware or data center space to facilitate their business needs quickly or cost effectively, can use VMware Cloud on AWS as a recovery target for new DR workloads.
As seen in the deployment design below, customers can replace on-premises colocation data centers with VMware Cloud on AWS as their recovery site.
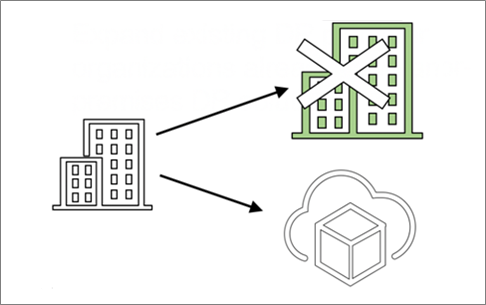
Figure 4 – Replacing on-premises DR site with VMware Cloud on AWS.
Complement Existing DR Solution with VMware Cloud on AWS
For customers who may or may not already be using VMware Site Recovery manager, they can configure a multi-recovery site architecture as depicted in Figure 5 below. In this architecture, customers can complement their existing DR implementations with VMware Cloud on AWS and VMware Site Recovery Manager.
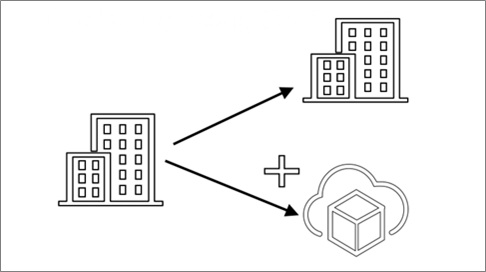
Figure 5 – Complimenting existing DR site with VMware Cloud on AWS.
Disaster Recovery for VMware Cloud on AWS
Finally, organizations who are already running workloads on VMware Cloud on AWS can use Site Recovery Manager for inter-region DR protection, in case one of the regions they are using experiences an outage.
Figure 6 – Using VMware Cloud on AWS for inter region/on-premises DR.
In this architecture, Site Recovery Manager uses another VMware Cloud on AWS in another region and an on-premises location as recovery sites for workloads in the cloud.
Design Considerations
To successfully implement a true functional disaster recovery solution, the underlying infrastructure network that supports your DR infrastructure must be well designed.
It’s a best practice to simplify your network infrastructure by creating new networks in your recovery site. Site Recovery Manager has the capability to re-ip all virtual machines that are recovered in the recovery site, being it VMware Cloud on AWS or on-premises.
This functionality is dependent on VMware tools, so you will need to ensure your critical VMs that need to be failed over have VMware Tools installed.
Some customers use VMware HCX to extend their on-premises networks to VMware Cloud on AWS and use these networks as recovery networks. Customers should be aware that in a disaster recovery event or test, manual intervention will be required to move the gateways from their on-premises data center. Customers should also be aware of the single points of failure for the appliances being used to stretch their networks.
Additionally, DNS resolution is important to ensure that all services are up and running. As a best practice, ensure you have extended your DNS infrastructure to the recovery site to allow for failover and DNS resolution. Amazon Route 53 is an excellent DNS service to use in this scenario and has the capability to automatically failover when the DNS infrastructure on-premises is no longer active during a disaster.

Figure 6 – Generic architecture using Amazon Route 53 with VMware Cloud on AWS for DR.
Using the failover routing policies on Amazon Route 53, DNS can be automatically failed over to your VMware Cloud on AWS cluster in the cloud to allow for continued DNS resolution in the event of a disaster.
Best Practices for Disaster Recovery
When using VMware Cloud on AWS to support your disaster recovery plans, there are several things to keep in mind to ensure a successful and functional plan.
- Have a documented disaster recovery plan: Without a detailed recovery plan, there is often little or no time to think on how to recover your IT infrastructure and business critical applications. Ensure you have a documented plan for DR to help get systems back online after a disaster.
.
Ensure there are processes and procedures in place to allow authorized staff to access to your recovery plans when systems are down. Such documents can be stored offsite, in cloud-based storage such as Amazon S3 or any other cloud storage service.
. - Recovery site location: The recovery site selected for your DR plan should not be a secondary building in the same location or blast radius. As a best practice, the recovery site for your on-premises IT infrastructure should exist in an area that’s not likely to be affected by the disaster affecting the primary site. Sometimes a few miles distance between site is insufficient for a truly secure recovery site.
.
Customers should ensure their DR location meets their business and regulatory requirements. In some areas, considerations should be made to the weather patterns and utility providers. When using VMware Cloud on AWS as a recovery site, it’s recommended not to have it in the same region where your on-premises data center is located.
.
As an example, if your on-premises environment is in the East Coast of the United States, you can choose VMware Cloud on AWS in the Central or West Coast regions as the recovery site for your IT infrastructure.
. - Test your recovery plan frequently: Many organizations have DR plans, but due to lack of testing there are often cases where in a true disaster the recovery process can be a daunting one. We recommend customers test their recovery plans regularly by allowing their IT teams to acquaint themselves with the failover and failback process to ensure their functionality.
.
Using the add on Site Recovery Manager Service that is provided by VMware for VMware Cloud on AWS, customers can run these tests regularly and simulate how a recovery will during a true recovery to VMware Cloud on AWS.
. - Plan for resuming operations: A system recovery is not fully complete until your VMs and applications are running from the recovery site after a disaster or test. The applications need to be operational as they were prior to the disaster. This process can also be challenging, so we recommend you document a plan for the necessary procedures and tests required to get your applications operational on the recovery site.
.
When using Site Recovery Manager and VMware Cloud on AWS as a recovery site, you can automate some of these processes by defining the startup order of your VMs when they are failed over to VMware Cloud on AWS in the cloud.
. - Include DR in your change management process: In many cases, there are several changes that are implemented in IT infrastructure environments. For this reason, the DR plan must be updated whenever there’s a change in the environment, being it a hardware, software, or network change. This ensures a fully functional recovery plan.
Conclusion
Maintaining a separate on-premises site to serve as a disaster recovery target is labor intensive and requires significant investment to deploy and maintain. Many customers realize the importance of implementing a DR solution and are looking at leveraging public clouds.
VMware Site Recovery Manager complements VMware Cloud on AWS and helps customers overcome many of the challenges associated with cloud-based DR. If you’re interested to learn how Site Recovery can help your organization, please refer to the resources below.
AWS Resources:
- Backup and Restore to VMware Cloud on AWS
- Data Domain Cloud Disaster Recovery for VMware Cloud on AWS
- VMware Cloud on AWS and Veeam Cloud Tier
- Backing up VMware Cloud on AWS with Druva Phoenix
VMware Resources: