AWS Architecture Blog
Category: Compute

Serverless Architecture for a Structured Data Mining Solution
Many businesses have an essential need for structured data stored in their own database for business operations and offerings. For example, a company that produces electronics may want to store a structured dataset of parts. This requires the following properties: color, weight, connector type, and more. This data may already be available from external sources. […]

Migrate Resources Between AWS Accounts
Have you ever wondered how to move resources between Amazon Web Services (AWS) accounts? You can really view this as a migration of resources. Migrating resources from one AWS account to another may be desired or required due to your business needs. Following are a few scenarios where this may be of benefit: When you […]

Get Started with Amazon S3 Event Driven Design Patterns
Event driven programs use events to initiate succeeding steps in a process. For example, the completion of an upload job may then initiate an image processing job. This allows developers to create complex architectures by using the principle of decoupling. Decoupling is preferable for many workflows, as it allows each component to perform its tasks […]
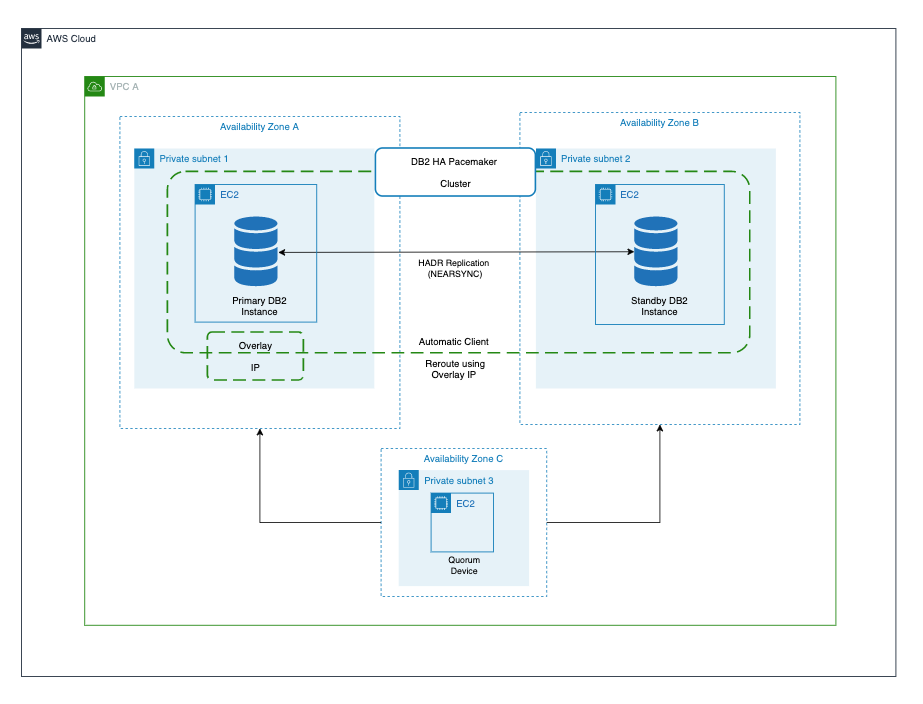
Field Notes: Set Up a Highly Available Database on AWS with IBM Db2 Pacemaker
Many AWS customers need to run mission-critical workloads—like traffic control system, online booking system, and so forth—using the IBM Db2 LUW database server. Typically, these workloads require the right high availability (HA) solution to make sure that the database is available in the event of a host or Availability Zone failure. This HA solution for […]

Build Your Own Game Day to Support Operational Resilience
Operational resilience is your firm’s ability to provide continuous service through people, processes, and technology that are aware of and adaptive to constant change. Downtime of your mission-critical applications can not only damage your reputation, but can also make you liable to multi-million-dollar financial fines. One way to test operational resilience is to simulate life-like […]

What to Consider when Selecting a Region for your Workloads
The AWS Cloud is an ever-growing network of Regions and points of presence (PoP), with a global network infrastructure that connects them together. With such a vast selection of Regions, costs, and services available, it can be challenging for startups to select the optimal Region for a workload. This decision must be made carefully, as […]

Optimizing Cloud Infrastructure Cost and Performance with Starburst on AWS
Amazon Web Services (AWS) Cloud is elastic, convenient to use, easy to consume, and makes it simple to onboard workloads. Because of this simplicity, the cost associated with onboarding workloads is sometimes overlooked. There is a notion that when an organization moves its workload to the cloud, agility, scalability, performance, and cost issues will disappear. […]

Disaster Recovery (DR) for a Third-party Interactive Voice Response on AWS
Voice calling systems are prevalent and necessary to many businesses today. They are usually designed to provide a 24×7 helpline support across multiple domains and use cases. Reliability and availability of such systems are important for a good customer experience. The thoughtful design of a cost-optimized solution will allow your business to sustain the system […]

Speed Up Translation Jobs with a Fully Automated Translation System Assistant
Like other industries, translation and localization companies face the challenge of providing fast delivery at a low cost. To address this challenge, organizations use Machine Translation (MT) to complement their translator teams. MT is the use of automated software that translates text without the need of human involvement. One of the most recent advancements is […]

How The Mill Adventure Implemented Event Sourcing at Scale Using DynamoDB
This post was co-written by Joao Dias, Chief Architect at The Mill Adventure and Uri Segev, Principal Serverless Solutions Architect at AWS The Mill Adventure provides a complete gaming platform, including licenses and operations, for rapid deployment and success in online gaming. It underpins every aspect of the process so that you can focus on […]