AWS for SAP
Agentic AI Assistant for SAP with AWS Generative AI
Introduction
SAP systems are the backbone of many enterprises, managing critical business processes and generating vast amounts of valuable data. These critical business processes and data usually extend beyond Enterprise SAP Systems, requiring customers to interact with external systems as well. As organizations seek to leverage this data for deeper insights and improved decision-making, there’s a growing need to transform how SAP customers interact with their data and systems.
Generative AI’s Natural Language Processing (NLP) capabilities offer SAP users a powerful tool to interact with their complex ERP systems using natural language queries, eliminating the need for specialized technical knowledge or complex SQL queries. This democratizes data access across the organization, allowing business users to ask questions, generate reports and gain insights in real-time using conversational interfaces.
Integrating Generative AI with SAP systems allows organizations to bridge the gap between structured ERP data and unstructured information from various SAP and non-SAP sources, providing a more comprehensive view of their business landscape. This integration can lead to more accurate forecasting, personalized customer experiences, and data-driven decision-making that spans the entire enterprise ecosystem.
AWS and SAP empowers customers at every stage of their Generative AI adoption journey with a comprehensive suite of cutting-edge generative AI services, robust infrastructure, and extensive implementation resources. These offerings can integrate with SAP systems and complement AWS’s and SAP’s vast ecosystem of cloud services.
In this blog(Part 1 of a 2 part series), I will describe and illustrate how you can leverage Amazon Bedrock and other AWS services to gain insights from SAP and Non-SAP data sources with human natural language in a unified view through MS Teams, Slack and Streamlit user interfaces.
In Part 2 of this blog series, I will describe and illustrate how you can leverage SAP BTP services [SAP Build Apps, SAP Generative AI Hub] to gain insights from SAP and Non-SAP system with human natural language in a unified view with SAP Build Apps user interfaces.
Overview
I will begin by developing the business logic necessary for extracting data from the SAP system. I will create two AWS Lambda functions that will execute the business logic, supported by various AWS services including Bedrock Knowledge Bases and AWS Secrets Manager. Then, I will focus on creating business logic to process data from an additional non-SAP data source, implementing another lambda function specifically designed to extract data from Amazon DynamoDB, which contains logistics information. To enhance the system’s capabilities, I will establish a knowledge base that will serve as a third data source, facilitating general user queries. Following this, I will implement a Amazon Bedrock Agents responsible for orchestrating the flow between these different data sources based on user queries. In the final stage, I will create a user interface using Streamlit, while also providing an alternative integration option with MS Teams and Slack for enhanced accessibility.
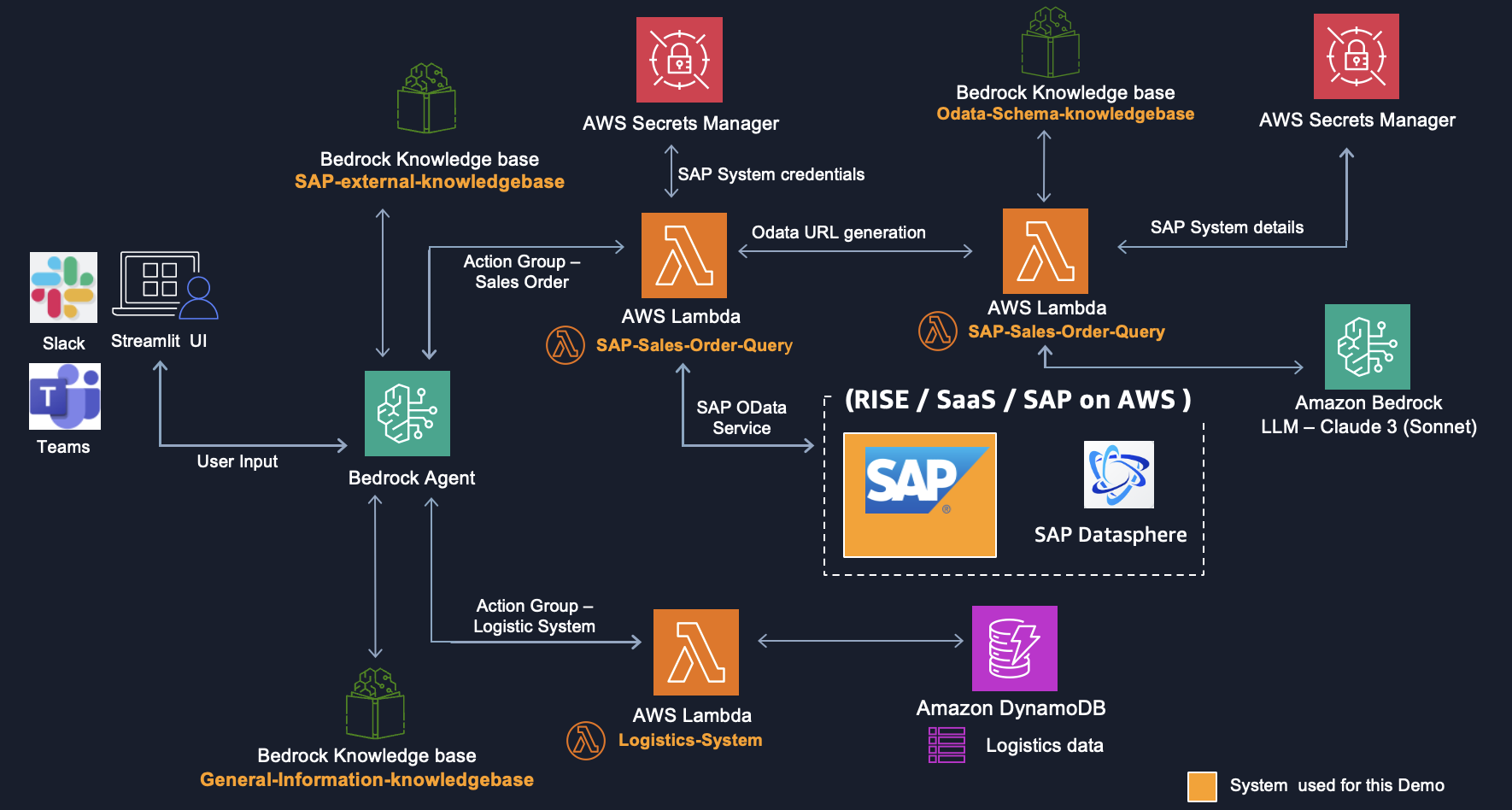
Figure 1. High Level Architecture
Walkthrough
I have structured the solution into 5 steps. Let me walk you through each step:
Step 1 – Create business logic to fetch data from an SAP system.
Step 2 – Create business logic to fetch data from a non-SAP system.
Step 3 – Create Bedrock Knowledge Bases for general queries.
Step 4 – Create Bedrock Agents to orchestrate between different data sources.
Step 5 – Create a user interface with Microsoft Teams, Slack and Streamlit.
Prerequisites-
An AWS account with appropriate IAM permission to work with Amazon S3, AWS Lambda, Amazon Bedrock Agents, Amazon Bedrock Knowledge Bases, Amazon Bedrock LLM(Claude), AWS Secrets Manager, Amazon DynamoDB. If you are not familiar with these services, it’s highly recommend reviewing them before proceeding further.
- An SAP system that supports SAP ODATA service as data source for SAP Sales Order.
- I have used a standard OData service, SAP Sales Order Service:
API_SALES_ORDER_SRVand Entity Set:A_SalesOrderfor this demo however you may use any OData service of your choice based on your use case. I have exposed the OData over internet but based on your scenarios where your SAP system is located you may or may not expose it to internet. However, we recommend to setup a private connectivity for better performance and security posture. For more information, see How to Enable OData Services in SAP S/4HANA and Connecting to RISE from your AWS account.
- Slack account for Slack integration and MS Teams account for MS Teams integration[optional]
Step 1 – Create business logic to fetch data from an SAP system
I. I will start with creating secrets in the AWS Secrets Manager to store S4 systems credentials and system connection details.
Select Choose secret type as Other type of secret and then add the below details under Key/value pairs. Put the secrets value as applicable to your environment.
| Secret key | Secret value |
S4_host_details |
https://<hostname>:<port> |
S4_username |
xxxx |
S4_password |
xxxx |
For more information, see Create an AWS Secrets Manager secret.
II. As a second step, I will create two Bedrock Knowledge Bases to complement and supplement SAP data as needed.
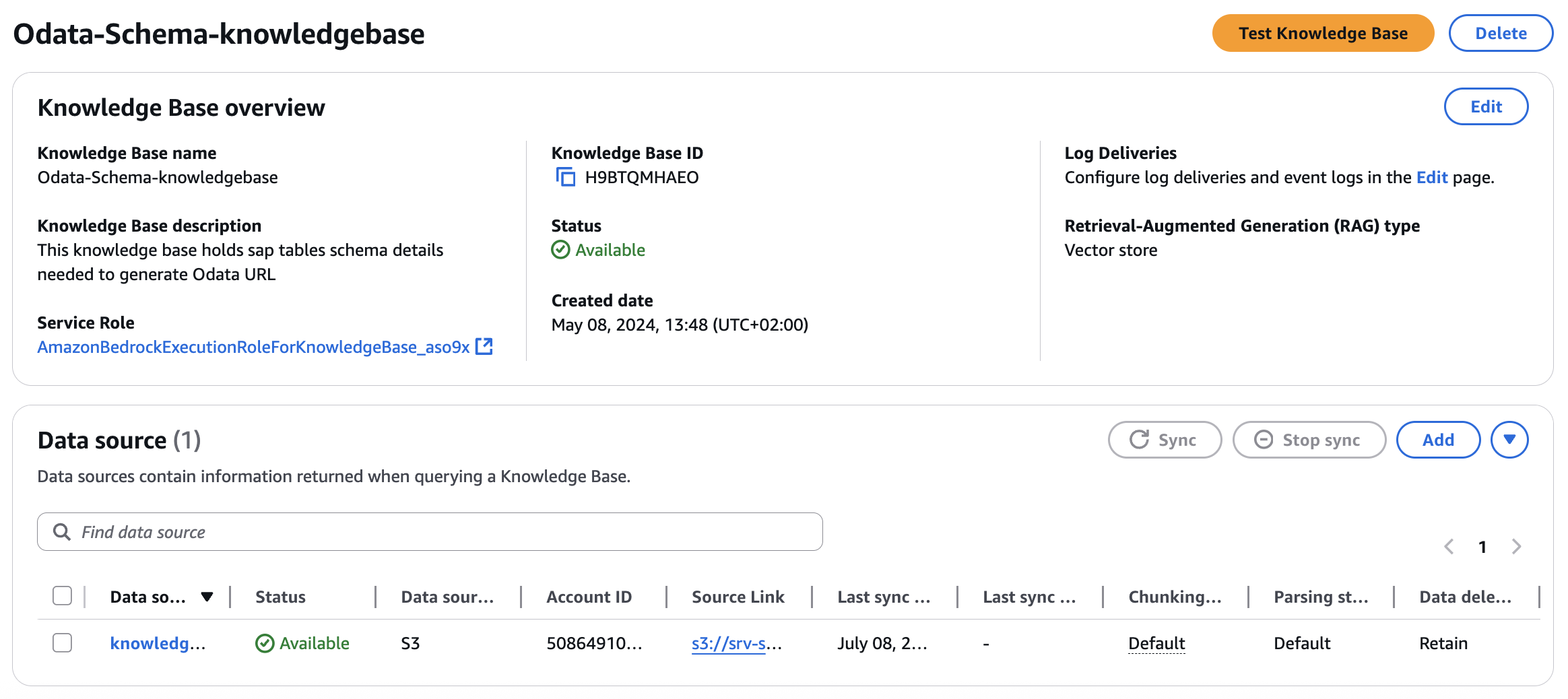
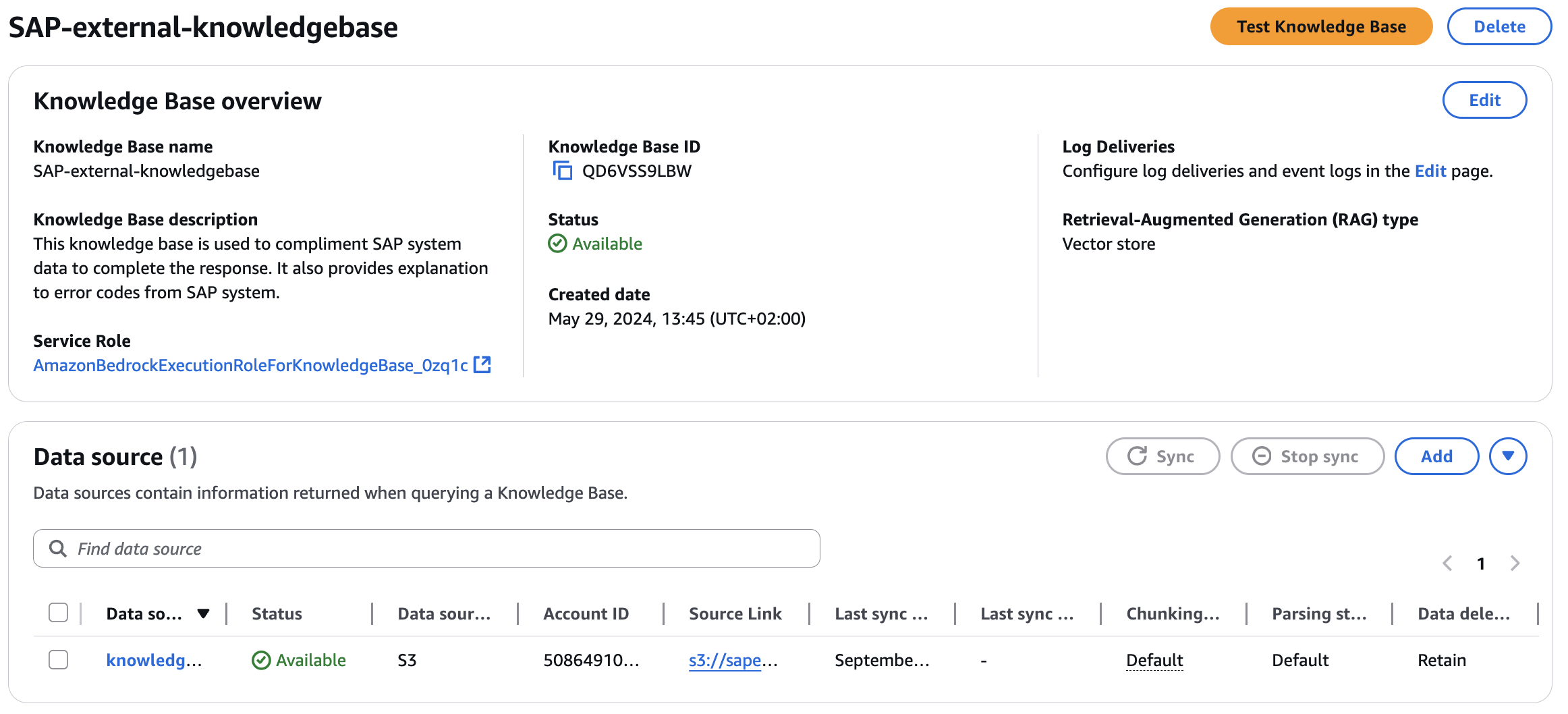
Odata-Schema-knowledgebaseI will use this Knowledge Bases to provide schema details to the LLM, so that the model has enough knowledge about the attributes to be used while creating the Odata URL based on the user query.SAP-external-knowledgebaseI will use this Knowledge Bases to provide supplementary details to non-SAP data.
I have considered the following inputs while creating the two Knowledge Bases, while keeping all other settings at their default values.
- Provide Bedrock Knowledge Base details
- Knowledge Base name: Choose a name for each Knowledge Bases with a user-friendly description. I have used
Odata-Schema-knowledgebaseandSAP-external-knowledgebase. - Knowledge Base description : Provide a description that uniquely defines your knowledge base.
- Knowledge Base name: Choose a name for each Knowledge Bases with a user-friendly description. I have used
- IAM permissions: Choose
Create and use a new service role - Configure data source
- Data source: Choose
Amazon S3 - Data source name: Choose a name for each data source.
- S3 URI: Create two S3 buckets, one for each Knowledge Bases. Upload the
Sales_Order_Schema.jsonfile for Odata-Schema-knowledgebase andShipping_Policy.pdffor SAP-external-knowledgebase from GitHub repository to corresponding S3 buckets and provide the S3 URI.
- Data source: Choose
- Configure data storage and processing
- Embeddings model:
Amazon Titan Text Embeddings V2 - Vector Database: Vector creation method as
Quick create a new vector storeand vector store asAmazon OpenSearch Serverless.
- Embeddings model:
For more information, see Create a knowledge base by connecting to a data source in Amazon Bedrock Knowledge Bases
Here’s what my final entry looks like:
III. Now I will create will two Lambda functions to extract data from SAP systems based on user query.
SAP-Odata-URL-GenerationThis Lambda executes the business logic to generate Odata URL based on the user queries with the help of LLM supported by schema details from the Knowledge Bases and host details from AWS Secrets Manager.SAP-Sales-Order-QueryThis Lambda function executes the core business logic for retrieving data from the SAP system. It utilizes the OData URL provided by the SAP-Odata-URL-Generation Lambda and securely accesses system credentials stored in AWS Secrets Manager. The function then processes the fetched data, leveraging LLM through bedrock, and finally presents the structured information to the Bedrock Agent for further use.
I have considered the below inputs while creating the functions, while keeping all other settings at their default values.
- Choose
Author from scratch - Function name: Choose a name for each function with a user-friendly description. I have chosen
SAP-Odata-URL-GenerationandSAP-Sales-Order-Query. - Runtime:
Python 3.13 - Architecture:
x86_64 - Code: Copy the code
SAP-Odata-URL-Generation.pyfor function SAP-Odata-URL-Generation andSAP-Sales-Order-Query.pyfor SAP-Sales-Order-Query from GitHub repository . Note: Adapt the code with values specific to your deployment like kb_id, SecretId etc. - Configuration: Memory :
1024MB, Timeout :15min - Layers: Add the layer
requests-layer.zipto addrequestsmodule to the lambda function from GitHub repository - Permissions : We need to configure the below permissions for the Lambda functions.
- SAP-Odata-URL-Generation: Execution role – In addition to lambda basic role, create a new IAM policy with the following actions
bedrock:InvokeModel,bedrock-agent-runtime:Retrieve,secretsmanager:GetSecretValue, Resource-based policy statements –lambda:InvokeFunctionaccess to Bedrock Agent ARN that we will create in Step4. - SAP-Sales-Order-Query: Execution role – In addition to lambda basic role, create a new IAM policy with the following actions
bedrock:InvokeModel,secretsmanager:GetSecretValueResource-based policy statements –lambda:InvokeFunctionaccess to Bedrock Agent ARN that we will create in Step4.
- SAP-Odata-URL-Generation: Execution role – In addition to lambda basic role, create a new IAM policy with the following actions
For more information, see Building Lambda functions with Python and Working with layers for Python Lambda functions
Step 2 – Create the business logic to fetch data from a non-SAP system
I. I will start with creating a DynamoDB table, with the below inputs.
- Table name:
logistics - Partition key:
order_id
Use the Items.json file from the GitHub repository to create item in the DynamoDB table. For more information, see Creating Amazon DynamoDB Table Items from a JSON File
II. I will now create a Lambda function to extract data from the DynamoDB table based on user query.
- Choose
Author from scratch - Function name: Choose a name for the function with a user-friendly description. I have chosen
Logistics-System - Runtime:
Python 3.13 - Architecture:
x86_64 - Configuration: Memory :
1024MB, Timeout :15min - Code: Copy the code
Logistics-System.pyfrom GitHub repository. - Permissions : Add the following permissions for the Lambda function. Execution role – In addition to lambda basic role, create a new IAM policy with the following actions
dynamodb:Query,dynamodb:DescribeTable, Resource-based policy statements –lambda:InvokeFunctionaccess to Bedrock Agent ARN that we will create in Step4.
Step 3 – Create a Knowledge Bases for general queries
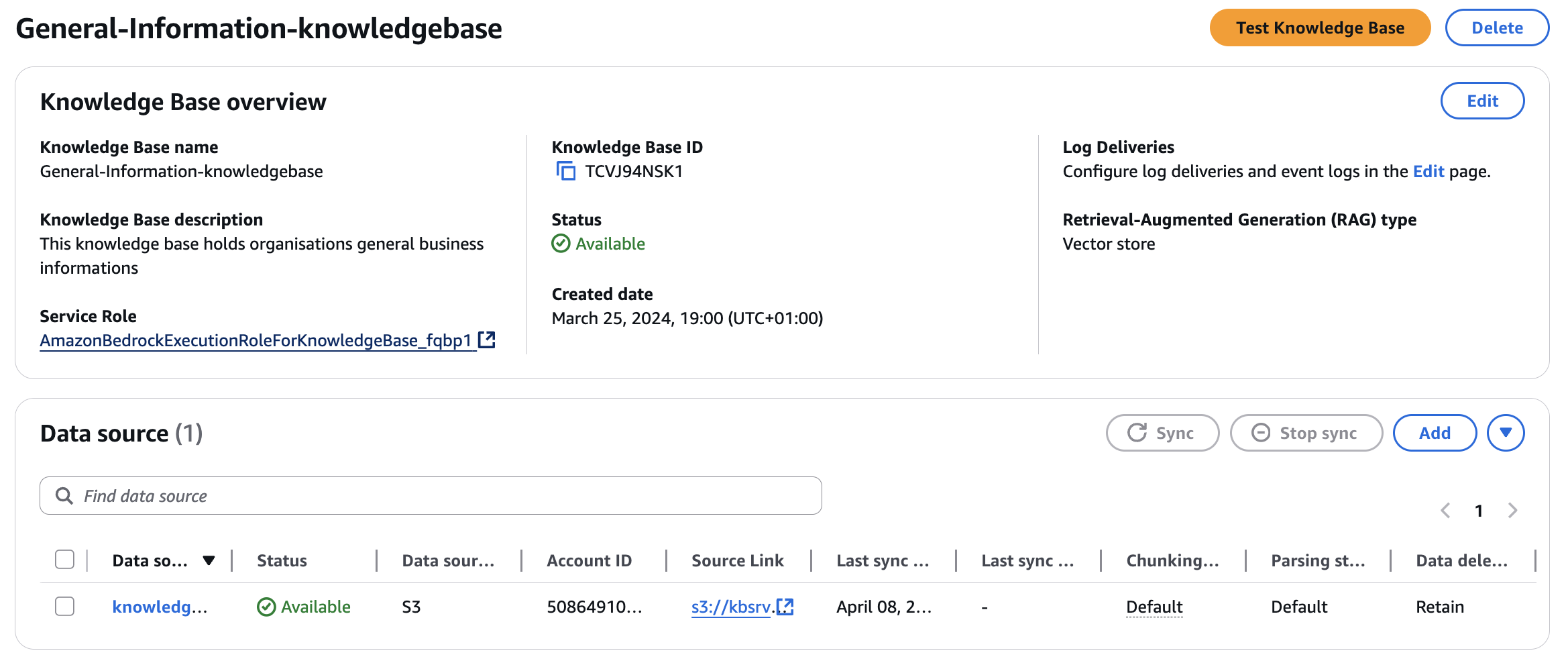
Now I will create a third knowledge base. This knowledge base will serve as a general information repository. Users can access this resource to learn about various topics, ranging from organizational information to specific subject matter expertise, as required.
General-information-knowledgebase: In this demo, I will use this knowledge base to provide guidance on SAP business processes.
I have considered the below inputs while creating the Knowledge Bases, keeping the rest as default.
- Provide Knowledge Base details
- Knowledge Base name: Choose a name for each Knowledge Bases, I have used
General-information-knowledgebasewith a user-friendly description. - IAM permissions: Choose
Create and use a new service role
- Knowledge Base name: Choose a name for each Knowledge Bases, I have used
- Configure data source
- Data source: Choose
Amazon S3 - Data source name: Choose a name for the data source as per your choice.
- S3 URI: Create a S3 buckets, upload the “
How to create SAP Sales Order pdf” from GitHub repo and provide the correspondingS3 URI.
- Data source: Choose
- Configure data storage and processing
- Embeddings model:
Amazon Titan Text Embeddings V2 - Vector Database: Vector creation method as
Quick create a new vector storeand vector store asAmazon OpenSearch Serverless.
- Embeddings model:
Here’s what my final entry looks like:
Step 4 – Create Bedrock Agent : In this step I will create a Bedrock Agent to help us orchestrate between different data sources we’ve created in previous steps to respond to user queries.
I have considered the below inputs while creating the bedrock agent, while keeping all other settings at their default values.
- Agent details :
- Agent name: Choose a name for the agent and a user-friendly description. I have named it
Business-Query-System. - Agent resource role: Choose
Create and use a new service role - Select model: Choose
Claude 3 Sonnet v1. You may choose a different LLM, but you need to modify the prompts accordingly to have the desired response. - Instructions for the Agent: Give precise, step-by-step directions that clearly explain what you want the Agent to do.
- Agent name: Choose a name for the agent and a user-friendly description. I have named it
You are an AI assistant helping users in querying SAP sales data directly from SAP system and shipping details from logistic system. You also help users with general queries about business process from the company knowledge base.
-
- Additional settings: User input choose
Enabled
- Additional settings: User input choose
-
- Action groups : Action groups define the tasks that agents should be able to help users fulfil.
- Action Group:
SAP-Sales-Order. I will use this action group to process any queries related to SAP Sales order.- Action group name: Choose a name for the action group and put a user-friendly description. I have named it
SAP-Sales-Order - Action group type:
Define with function details - Action group invocation:
Select an existing Lambda functionand select the lambda function we created in Step 1,SAP-Sales-Order-Query - Action group function1 name:
SalesOrderand provide a description for the function.
- Action group name: Choose a name for the action group and put a user-friendly description. I have named it
- Action Group:
Logistics-System. I will use this action group to process any queries related to Logistics information for sales order.- Action group name: Choose a name for the action group and put a user-friendly description. I have named it
Logistics-System - Action group type:
Define with API schemas - Action group invocation:
Select an existing Lambda functionand select the lambda function we created in Step 2,Logistics-System. - Action group schema:
Select an existing API schema. - S3 Url: Create a S3 bucket and upload the file
logistics.jsonfrom GitHub repository to S3 bucket and provide the S3 Url of the bucket.
- Action group name: Choose a name for the action group and put a user-friendly description. I have named it
- Action Group:
- Memory : Choose
Enabledwith Memory duration to2 daysand Maximum no of recent sessions to20. - Knowledge Bases : Add the knowledge bases created before
- Select Knowledge Base:
SAP-external-knowledgebase
- Select Knowledge Base:
- Action groups : Action groups define the tasks that agents should be able to help users fulfil.
Knowledge Base instructions for Agent: Use this knowledge base when you need some information outside of SAP system and combine it with SAP system data to complete the response
-
-
- Select Knowledge Base:
General-Information-knowledgebase
- Select Knowledge Base:
-
Knowledge Base instructions for Agent: Use this knowledge base to answer generic business question from the user which is not available from SAP system.
-
- Orchestration strategy details –
Default orchestration. Bedrock agents provide default prompt templates, but they can be tailored to meet specific requirements. I will customize the below prompt templates to align with our specific use case requirements.
- Orchestration strategy details –
-
-
- Pre-processing: Choose
Override pre-processing template defaults. Add the below section to the prompt template.
- Pre-processing: Choose
-
-Category F: Questions that can be answered or assisted by our function calling agent using the functions it has been provided and arguments from within conversation history or relevant arguments it can gather using the askuser function AND also needs external data from the knowledge base to complete the response. Combine data from the SAP or non-SAP Logistic system and the external knowledge base to prepare the final answer
-
-
- Orchestration: Choose
Override orchestration template defaults. Add the below text under the corresponding sections in the prompt template.
- Orchestration: Choose
-
$knowledge_base_guideline$
- If any data is not updated in the Logistic system like order shipping date, then check the knowledge base named 'SAP-external-knowledgebase' to look for the estimated delivery timeline as per the shipping category. Then consider that timeline and add the timeline to the date of 'Order Received' and share the estimated the shipping date with the user
- If the SAP system throws any error due to unavailability of the requested data, check the knowledge base named 'SAP-external-knowledgebase' to look for the explanation of the ERROR CODE. Respond to the user with the explanation of the error code ONLY
$tools_guidelines$ [This section doesn’t exist, we need to create it]
- Invoke tool 'SAP-Sales-Order' ONLY for any questions related to sales order
- Invoke tool 'Logistics-System' ONLY for any shipping details for the sales order
- Do NOT invoke both tools 'SAP-Sales-Order' and 'Logistics-System' unless user requested for both the information.
$multiple_tools_guidelines$ [This section doesn’t exist, we need to create it]
- If user asks question which needs to invoke more than one tool. Invoke the tools one by one. Collect the response from both the tools and then combine them before responding to the users.
For example, if user requests for both Sales order and Logistic information. First fetch the Sales Order details with Sales Order tool. Then fetch logistic details from Logistic tool. Finally combine both responses into one when responding to the user.
Once we have entered all the details I will Save and then choose Prepare to update the latest changes. To navigate to the agent overview page choose Save and exit.
Finally, create an Aliases to have a specific snapshot, or version of the agent to be used in the application.
Choose Create, provide a Alias name with a user friendly Description.
Choose Create a new version and associate it to this alias for version with throughput as default to On-demand.
For more information, see Create and configure agent manually
Here’s what my final entry looks like:
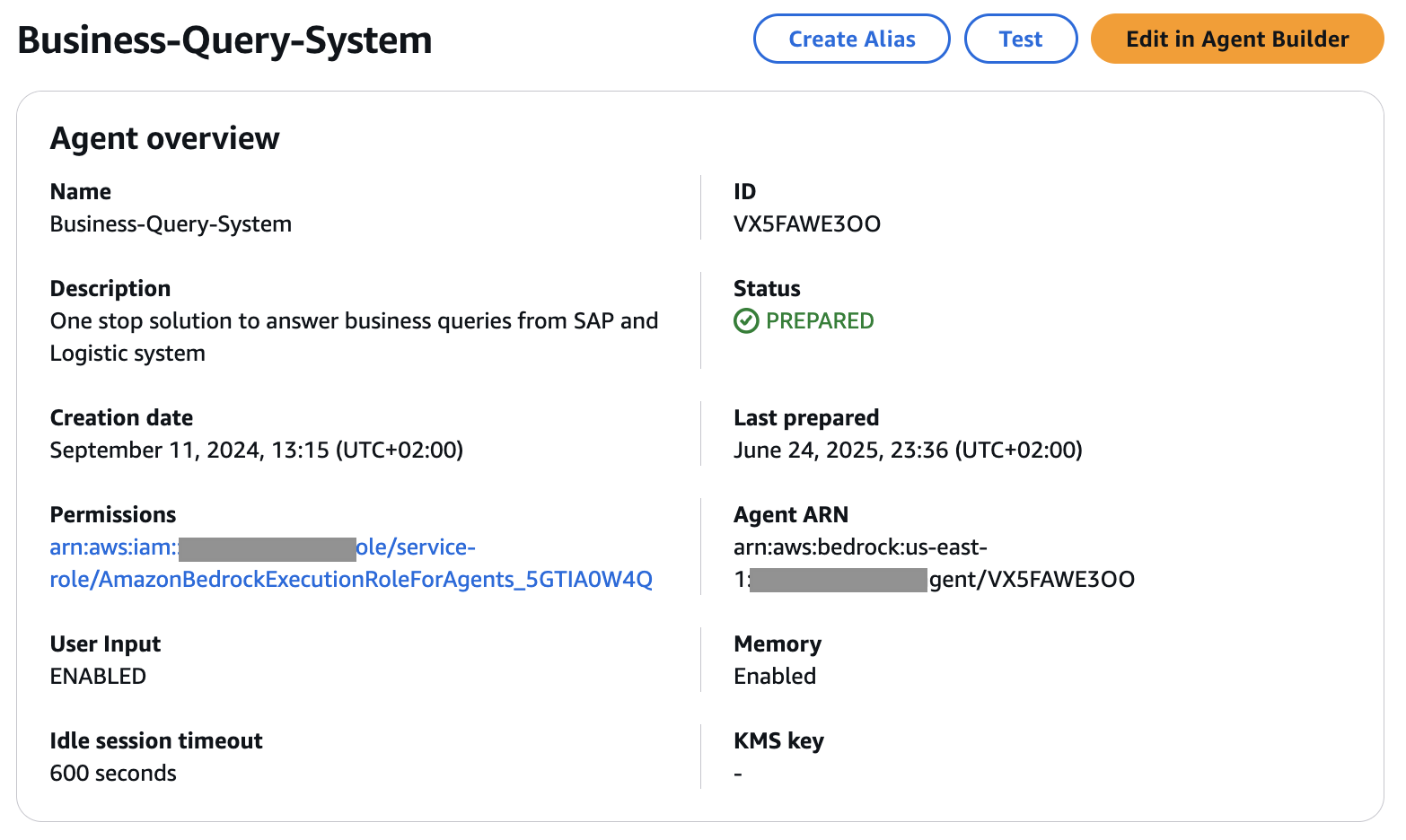
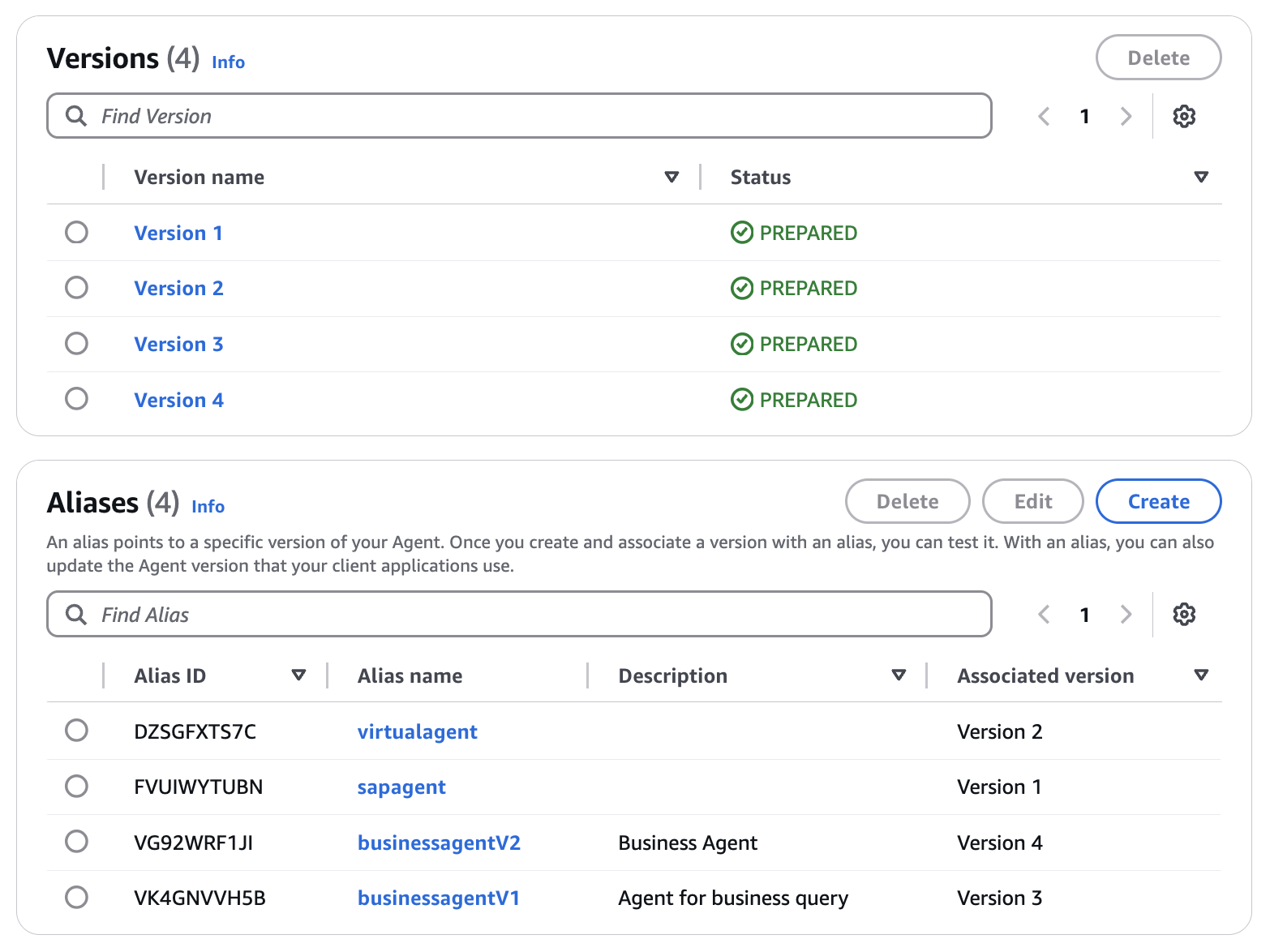
As you see, I have created multiple aliases and versions of my agent, allowing me to select any alias to integrate a specific snapshot or version into my application.
Now I need to adjust the IAM roles for the Lambda function so that the bedrock agent could invoke them.
Follow the steps at Using resource-based policies for Lambda and attach the following resource-based policy to a Lambda function to allow Amazon Bedrock to access the Lambda function for your agent’s action groups, replacing the ${values} as necessary.
{
"Version": "2012-10-17",
"Statement": [
{
"Sid": "AccessLambdaFunction",
"Effect": "Allow",
"Principal": {
"Service": "bedrock.amazonaws.com"
},
"Action": "lambda:InvokeFunction",
"Resource": "arn:aws:lambda:${region}:${account- id}:function:function-name",
"Condition": {
"StringEquals": {
"AWS:SourceAccount": "${account-id}"
},
"ArnLike": {
"AWS:SourceArn": "arn:aws:bedrock:${region}:${account-id}:agent/${agent-id}"
}
}
}
]
}
Here’s what my policy looks like
{ "Version": "2012-10-17", "Id": "default", "Statement": [ { "Sid": "bedrock-agent-sales", "Effect": "Allow", "Principal": { "Service": "bedrock.amazonaws.com" }, "Action": "lambda:InvokeFunction", "Resource": "arn:aws:lambda:us-east-1:1234567xxxx:function:SAP-Sales-Order-Query", "Condition": { "StringEquals": { "AWS:SourceAccount": "1234567xxxx" }, "AWS:SourceArn": { "arn:aws:bedrock:us-east-1: 1234567xxxx:agent/VX5FAWE3OO" } } } ] } Step 5 – Create user interface with Microsoft Teams, Slack and Streamlit
This step involves developing an user interface that allows users to interact with the Bedrock agent.
- Microsoft Teams – This integration requires access to both MS Teams (with appropriate permissions) and Amazon Q Developer in chat application. Amazon Q Developer in chat applications (previously AWS Chatbot) enables you to interact with GenAI Bedrock Agents in Microsoft Teams.
Step1: Configure App access:
Microsoft Teams is installed and approved by your organization administrator.
Step2: Configure a Teams channel:
Create a MS Teams standard channel or use an existing one and add Amazon Q Developer to the channel.[Note: We need Standard channel as Microsoft Teams doesn’t currently support Amazon Q Developer in private channels]
-
-
- In Microsoft Teams, find your team name and choose , then choose Manage team.
- Choose Apps, then choose More apps.
- Enter Amazon Q Developerin the search bar to find Amazon Q Developer.
- Select the bot.
- Choose Add to a team and complete the prompt
-
Step3: Configure Amazon Q Developer for Teams client
This step provides Amazon Q Developer in chat Applications access to your MS Teams channel.
-
-
- Open the Amazon Q Developer in chat applications in AWS console.
- Under Configure a chat client, choose Microsoft Teams, copy and paste your Microsoft Teams channel URL which we created in previous step then choose Configure. [You’ll be redirected to Teams authorization page to request permission for Amazon Q Developer to access your information].
- On the Microsoft Teams authorization page, choose Accept. On the left side, now you should see your Teams Channel listed under Microsoft Teams.
-
Next, I will associate a MS Teams channel to my configuration.
On the Teams details page in the Amazon Q Developer console, choose Configure new channel. I have the below inputs for my configuration, keeping rest as default.
-
-
- Configuration details:
-
Configuration name: Choose a name for your configuration. I named it aws-sap-demos-team
-
-
- Microsoft Teams channel
-
Channel URL: Copy and paste your Microsoft Teams channel URL which we created in step2.
-
-
- Permissions
- Role settings: Choose Channel role
- Channel role: Choose Create an IAM role using a template
- Role name: Choose a name of your choice. I have named it awschatbot-sap-genai-teams-role
- Policy templates: Amazon Q Developer access permissions
- Channel guardrail policies[Policy name]: AWSLambdaBasicExecutionRole , AmazonQDeveloperAccess. You may adjust the IAM policies as per your requirement but it is always recommended to follow the best practice of least-privilege permissions.
- Permissions
-
Step4: Now we will connect an agent to the chat channel
The Amazon Q Developer Bedrock Agent connector requires the bedrock:InvokeAgent IAM action.
Add the below policy to the IAM role : awschatbot-sap-genai-teams-role created in previous step.
{
"Sid": "AllowInvokeBedrockAgent",
"Effect": "Allow",
"Action": "bedrock:InvokeAgent",
"Resource": [
"arn:aws:bedrock:aws-region:<AWS Account ID>:agent-alias/<Bedrock Agent ID>/<Agent Alias ID>/"
]
}To add Amazon Bedrock agent to your chat channel, enter @Amazon Q connector add connector_name arn:aws:bedrock:aws-region:AWSAccountID:agent/AgentID AliasID. Choose a connector name of your choice.
My entry looks like this.
@Amazon Q connector add order_assistant arn:aws:bedrock:us-east-1:xxxxxxx:agent/VX5FAWE3OO VG92WRF1JI
For more information, see Tutorial: Get started with Microsoft Teams
The Teams interface looks like this
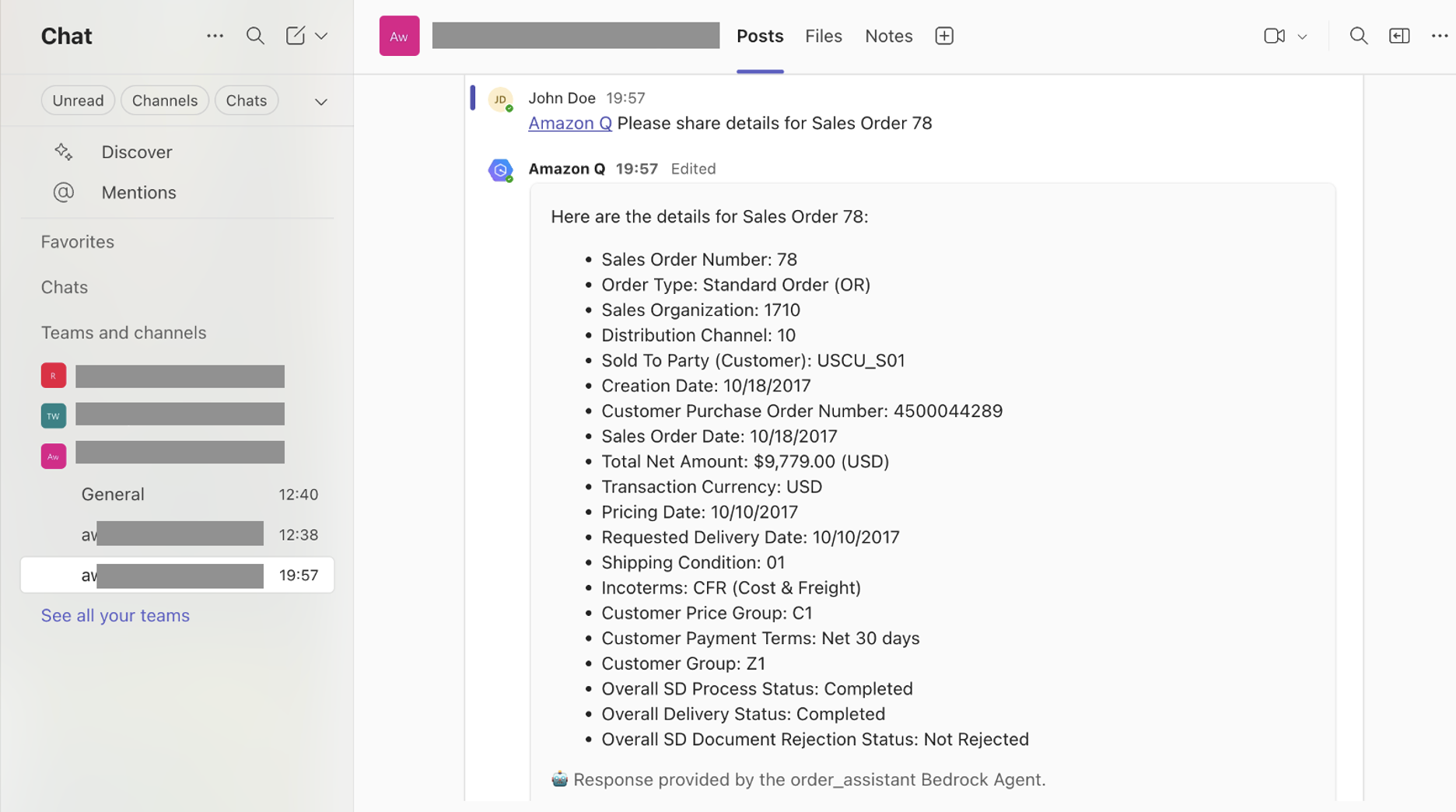
- Slack – This integration requires access to both Slack (with appropriate permissions) and Amazon Q Developer in chat application. Amazon Q Developer in chat applications (previously AWS Chatbot) enables you to interact with GenAI Bedrock Agents in Slack.
Step1: Configure App access:
Workspace administrators need to approve the use of the Amazon Q Developer app within the workspace.
Step2: Configure a Slack channel:
Create a slack channel or use an existing one and add Amazon Q Developer to the Slack channel.
In your Slack channel, enter /invite @Amazon Q and choose Invite Them
Step3: Configure Amazon Q Developer for Slack client
This step provides Amazon Q Developer in chat Applications access to your Slack workspace.
-
-
- Open the Amazon Q Developer in chat applications in AWS console. Under Configure a chat client, choose Slack, then choose Configure. [You’ll be redirected to Slack’s authorization page to request permission for Amazon Q Developer to access your information].
- Choose the Slack workspace that you want to use with Amazon Q Developer and Choose Allow.
- On the left side, now you should see your Slack workspace listed under Slack.
-
Next I will associate a channel to my configuration.
On the Workspace details page in the Amazon Q Developer console, choose Configure new channel. I have the below inputs for my configuration, keeping rest as default.
-
-
- Configuration details:
-
Configuration name: Choose a name for your configuration. I named it sap-genai-slack-chatbot
-
-
- Amazon Internal Preferences
-
Account Classification: Choose Non-Production
-
-
- Slack channel
-
Channel ID: Provide the channel ID of the slack channel you configured in step2.
-
-
- Permissions
- Role settings: Choose Channel role
- Channel role: Choose Create an IAM role using a template
- Role name: Choose a name of your choice. I have named it aws-sap-genai-chatbot-role
- Policy templates: Amazon Q Developer access permissions
- Channel guardrail policies[Policy name]: AWSLambdaBasicExecutionRole , AmazonQDeveloperAccess. You may adjust the IAM policies as per your requirement but it is always recommended to follow the best practice of least-privilege permissions.
- Permissions
-
Step4: Now we will connect an agent to the chat channel
The Amazon Q Developer Bedrock Agent connector requires the bedrock:InvokeAgent IAM action.
Add the below policy to the IAM role : awschatbot-sap-genai-teams-role created in previous step.
{
"Sid": "AllowInvokeBedrockAgent",
"Effect": "Allow",
"Action": "bedrock:InvokeAgent",
"Resource": [
"arn:aws:bedrock:aws-region:<AWS Account ID>:agent-alias/<Bedrock Agent ID>/<Agent Alias ID>/"
]
}
To add Amazon Bedrock agent to your chat channel, enter as below. Choose a connector name of your choice.
@Amazon Q connector add connector_name arn:aws:bedrock:aws-region:AWSAccountID:agent/AgentID AliasID. .
My entry looks like this.
@Amazon Q connector add order_assistant arn:aws:bedrock:us-east-1:xxxxxxx:agent/VX5FAWE3OO VG92WRF1JI
For more information, see Tutorial: Get started with Slack
The Slack interface looks like this
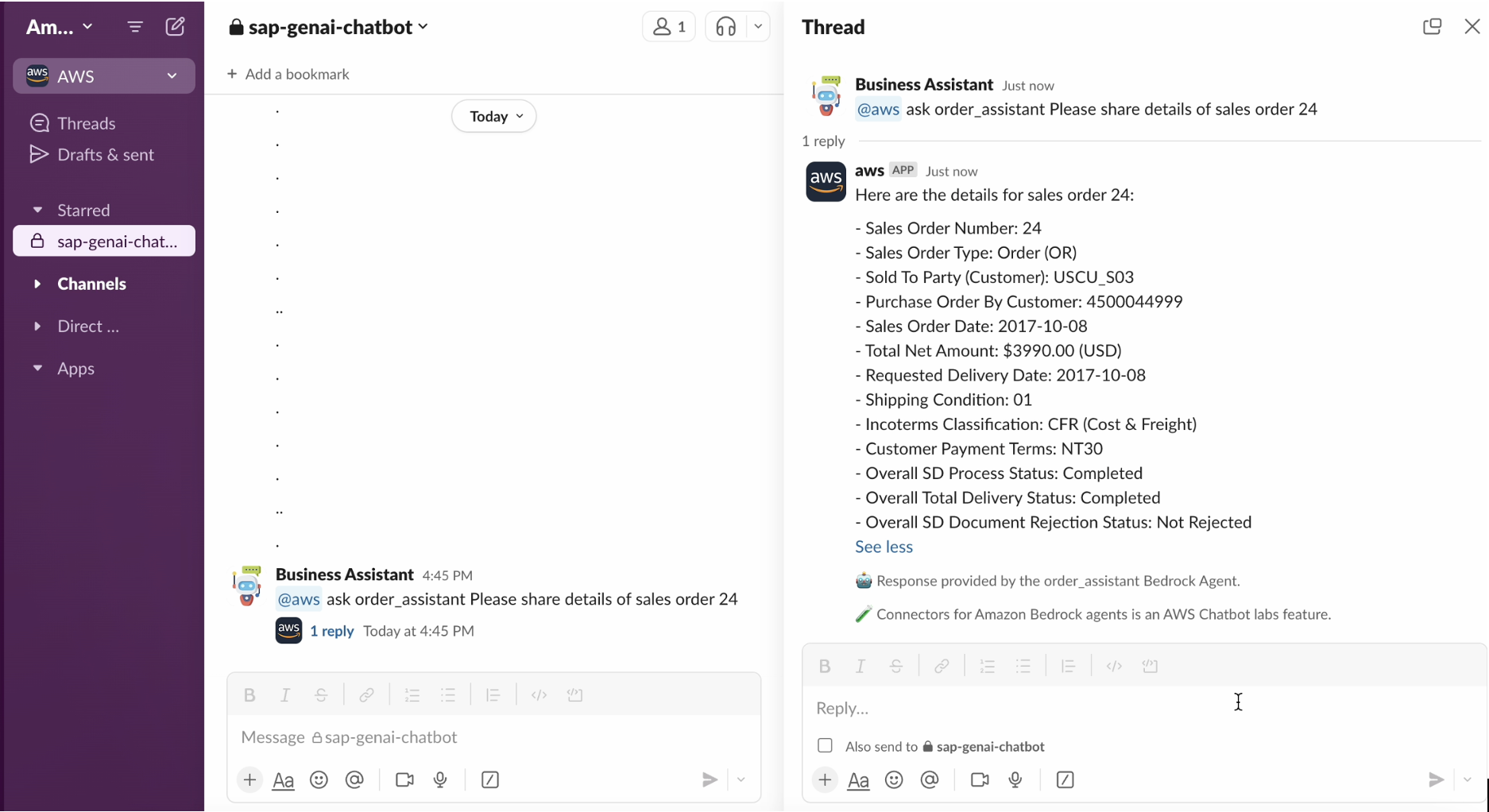
- Streamlit – Streamlit is an open-source Python framework generally used to build interactive web apps for python scripts. I have followed the below steps to host the application on an amazon EC2 instance.
- Spin up a EC2 instance, I have considered an Amazon Linux t2.micro instance.
- Setup the EC2 instance with needed security group allowing HTTP/HTTPS traffic (port 80/443/8501 or any other port you have chosen to use)
- Prepare the environment as below
Install Required Packages
$sudo apt update
$sudo apt-get install python3-venv
Set Up a Virtual Environment
$mkdir streamlit-demo
$cd streamlit-demo
$python3 -m venv venv
$source venv/bin/activate
-
- Install Streamlit
$pip install streamlit
-
- Create a file named streamlit-app.py using Vi/Vim/nano editor and copy the code in
streamlit-app.pyfrom GitHub repository.
- Create a file named streamlit-app.py using Vi/Vim/nano editor and copy the code in
-
- Run the Streamlit app with the below command
$streamlit run streamlit-app.py
-
- Run the streamlit app in background with the below command
$nohup streamlit run streamlit-app.py &
-
- Streamlit assigns the available port from 8501 in increments of 1. If you want streamlit to consider a specific port, you may use the below command
$streamlit run streamlit-app.py --server.port XXXX
After I ran the above commands, I could see the URL to open the Streamlit application in my browser, as shown below
The Streamlit application looks like this

Cost
Operating Large Language Models (LLMs) involves substantial infrastructure, development, and maintenance costs. However, AWS services like Amazon Bedrock can significantly reduce expenses through simplified infrastructure management, streamlined development processes, flexible pricing models, and various cost optimization options for accessing the LLM’s of your choice.
| AWS Service – US East (N. Virginia) | Cost | Estimates [ running for an hr.] |
| Bedrock – Foundation Model LLM Inference[Claude 3.5 Sonnet] | 100K Input, 200K Output | $3.3 |
| Bedrock – Embedding Model Inference[Amazon Titan Text Embeddings v2] | 100 documents, each avg. 500 words | $0.10 |
| OpenSearch Compute Unit (OCU) – Indexing | 2 OCU[min. 2 OCU] | $0.48 |
| OpenSearch Compute Unit (OCU) – Search and Query | 2 OCU[min. 2 OCU] | $0.48 |
| OpenSearch Managed Storage | 10GB | $0.24 |
| EC2 Instance[Streamlit App] | t2.micro | $ 0.0116 |
| Lambda, Secrets Manager, DynamoDB | $ 0.2 | |
| Estimated cost for using application for an hr. – $4.8116 | ||
For more information, see Amazon Bedrock pricing, Amazon OpenSearch Service Pricing, Amazon EC2 On-Demand Pricing, AWS Lambda pricing, AWS Secrets Manager pricing, Amazon DynamoDB pricing
Conclusion
This blog post demonstrates how to create an intelligent virtual assistant that seamlessly interacts with both SAP and non-SAP systems using AWS services, with a focus on Amazon Bedrock. The solution integrates SAP systems for sales order data, non-SAP systems for logistics information, and Knowledge Bases for supplementary details, all accessible through multiple user interfaces including Streamlit, Microsoft Teams, and Slack. By leveraging a suite of AWS services like Lambda, Bedrock, Secrets Manager, and DynamoDB, the implementation enables natural language interaction with complex enterprise systems, providing unified access to diverse data sources while maintaining robust security. The serverless architecture and pay-as-you-go pricing model make this an accessible and cost-effective solution for organizations looking to enhance their data access capabilities through conversational AI interfaces. The blog post provides a detailed, step-by-step guide to implementing this solution, paving the way for enterprises to leverage generative AI in their SAP and non-SAP environments.
Get hands-on experience in transforming how you interact with your enterprise data by implementing this solution. Accelerate your digital transformation by exploring our comprehensive suite of machine learning services, including Amazon AgentCore(Preview) to deploy and operate AI agents securely at scale, Amazon Forecast for predictive analytics, Amazon Textract for intelligent document processing, Amazon Translate for language translation, and Amazon Comprehend for natural language processing. These services seamlessly integrate with SAP to address various business needs and unlock new possibilities for your organization.
Visit the AWS for SAP page to learn why thousands of customers trust AWS to migrate and innovate with SAP.