AWS Big Data Blog
Author: Sandeep Adwankar
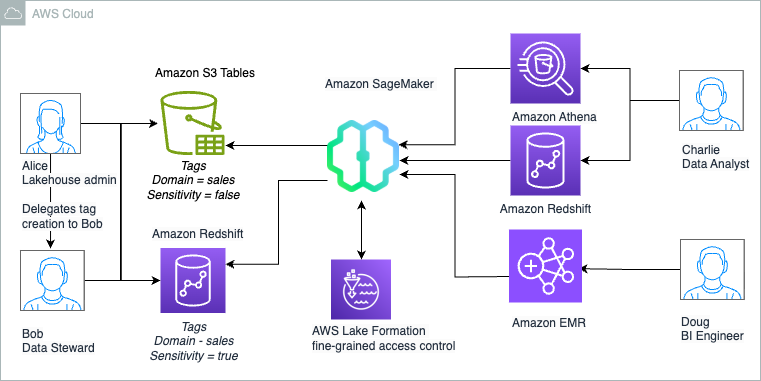
The Amazon SageMaker Lakehouse Architecture now supports Tag-Based Access Control for federated catalogs
We are now announcing support for Lake Formation tag-based access control (LF-TBAC) to federated catalogs of S3 Tables, Redshift data warehouses, and federated data sources such as Amazon DynamoDB, MySQL, PostgreSQL, SQL Server, Oracle, Amazon DocumentDB, Google BigQuery, and Snowflake. In this post, we illustrate how to manage S3 Tables and Redshift tables in the lakehouse using a single fine-grained access control mechanism of LF-TBAC. We also show how to access these lakehouse tables using your choice of analytics services, such as Athena, Redshift, and Apache Spark in Amazon EMR Serverless.

Amazon SageMaker Lakehouse now supports attribute-based access control
Amazon SageMaker Lakehouse now supports attribute-based access control (ABAC) with AWS Lake Formation, using AWS Identity and Access Management (IAM) principals and session tags to simplify data access, grant creation, and maintenance. In this post, we demonstrate how to get started with SageMaker Lakehouse with ABAC.

Accelerate your analytics with Amazon S3 Tables and Amazon SageMaker Lakehouse
Amazon SageMaker Lakehouse is a unified, open, and secure data lakehouse that now seamlessly integrates with Amazon S3 Tables, the first cloud object store with built-in Apache Iceberg support. In this post, we guide you how to use various analytics services using the integration of SageMaker Lakehouse with S3 Tables.

Catalog and govern Amazon Athena federated queries with Amazon SageMaker Lakehouse
In this post, we show how to connect to, govern, and run federated queries on data stored in Redshift, DynamoDB (Preview), and Snowflake (Preview). To query our data, we use Athena, which is seamlessly integrated with SageMaker Unified Studio. We use SageMaker Lakehouse to present data to end-users as federated catalogs, a new type of catalog object. Finally, we demonstrate how to use column-level security permissions in AWS Lake Formation to give analysts access to the data they need while restricting access to sensitive information.

The AWS Glue Data Catalog now supports storage optimization of Apache Iceberg tables
The AWS Glue Data Catalog now enhances managed table optimization of Apache Iceberg tables by automatically removing data files that are no longer needed. Along with the Glue Data Catalog’s automated compaction feature, these storage optimizations can help you reduce metadata overhead, control storage costs, and improve query performance. Iceberg creates a new version called […]

Enhance query performance using AWS Glue Data Catalog column-level statistics
Today, we’re making available a new capability of AWS Glue Data Catalog that allows generating column-level statistics for AWS Glue tables. These statistics are now integrated with the cost-based optimizers (CBO) of Amazon Athena and Amazon Redshift Spectrum, resulting in improved query performance and potential cost savings. Data lakes are designed for storing vast amounts […]

Introducing AWS Glue crawler and create table support for Apache Iceberg format
Apache Iceberg is an open table format for large datasets in Amazon Simple Storage Service (Amazon S3) and provides fast query performance over large tables, atomic commits, concurrent writes, and SQL-compatible table evolution. Iceberg has become very popular for its support for ACID transactions in data lakes and features like schema and partition evolution, time […]

AWS Glue crawlers support cross-account crawling to support data mesh architecture
Data lakes have come a long way, and there’s been tremendous innovation in this space. Today’s modern data lakes are cloud native, work with multiple data types, and make this data easily available to diverse stakeholders across the business. As time has gone by, data lakes have grown significantly and have evolved to data meshes […]

Introducing AWS Glue crawlers using AWS Lake Formation permission management
Data lakes provide a centralized repository that consolidates your data at scale and makes it available for different kinds of analytics. AWS Glue crawlers are a popular way to scan data in a data lake, classify it, extract schema information from it, and store the metadata automatically in the AWS Glue Data Catalog. AWS Lake […]