AWS Big Data Blog
Category: Amazon Athena

Create real-time clickstream sessions and run analytics with Amazon Kinesis Data Analytics, AWS Glue, and Amazon Athena
April 2024: The content of this post is no longer relevant and deprecated. August 30, 2023: Amazon Kinesis Data Analytics has been renamed to Amazon Managed Service for Apache Flink. Read the announcement in the AWS News Blog and learn more. Clickstream events are small pieces of data that are generated continuously with high speed […]
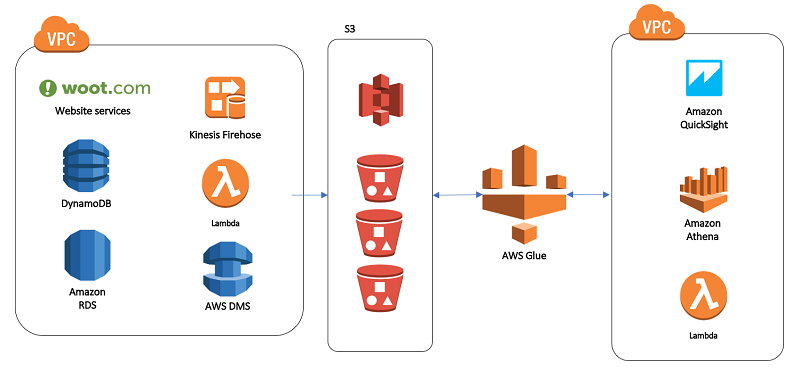
Our data lake story: How Woot.com built a serverless data lake on AWS
February 9, 2024: Amazon Kinesis Data Firehose has been renamed to Amazon Data Firehose. Read the AWS What’s New post to learn more. In this post, we talk about designing a cloud-native data warehouse as a replacement for our legacy data warehouse built on a relational database. At the beginning of the design process, the […]

Analyze and visualize nested JSON data with Amazon Athena and Amazon QuickSight
April 2024: This post was reviewed for accuracy. Although structured data remains the backbone for many data platforms, increasingly unstructured or semi-structured data is used to enrich existing information or create new insights. Amazon Athena enables you to analyze a wide variety of data. This includes tabular data in CSV or Apache Parquet files, data […]

Chasing earthquakes: How to prepare an unstructured dataset for visualization via ETL processing with Amazon Redshift
As organizations expand analytics practices and hire data scientists and other specialized roles, big data pipelines are growing increasingly complex. Sophisticated models are being built using the troves of data being collected every second. The bottleneck today is often not the know-how of analytical techniques. Rather, it’s the difficulty of building and maintaining ETL (extract, transform, and load) jobs using tools that might be unsuitable for the cloud. In this post, I demonstrate a solution to this challenge.
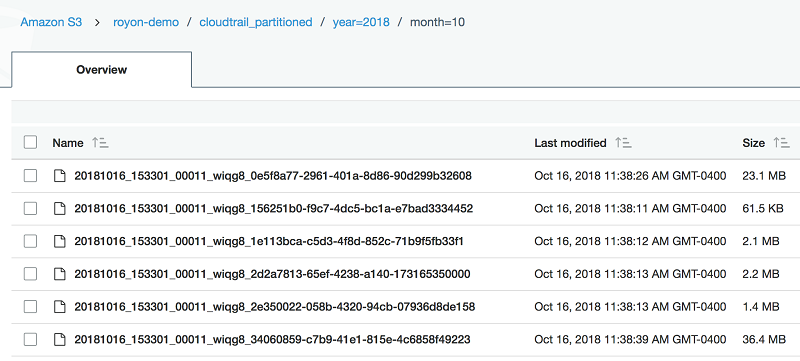
Use CTAS statements with Amazon Athena to reduce cost and improve performance
This blog post shows how to use the CREATE TABLE AS SELECT (CTAS statement) in Athena. It also shows how to automate the creation of unique tables that represent a subset of the AWS CloudTrail data. This helps us audit Amazon Athena usage.
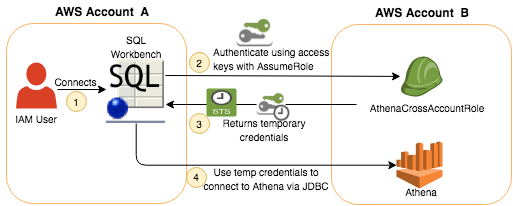
Connect to Amazon Athena with federated identities using temporary credentials
This post walks through three scenarios to enable trusted users to access Athena using temporary security credentials. First, we use SAML federation where user credentials were stored in Active Directory. Second, we use a custom credentials provider library to enable cross-account access. And third, we use an EC2 Instance Profile role to provide temporary credentials for users in our organization to access Athena.

Analyze and visualize your VPC network traffic using Amazon Kinesis and Amazon Athena
In this blog post, we describe the complete solution for collecting, analyzing, and visualizing VPC flow log data. In addition, we created a single AWS CloudFormation template that lets you efficiently deploy this solution into your own account.

How to build a front-line concussion monitoring system using AWS IoT and serverless data lakes – Part 2
August 2024: This post was reviewed and updated for accuracy. In part 1 of this series, we demonstrated how to build a data pipeline in support of a data lake. We used key AWS services such as Amazon Kinesis Data Streams, Kinesis Data Analytics, Kinesis Data Firehose, and AWS Lambda. In part 2, we discuss […]

How to build a front-line concussion monitoring system using AWS IoT and serverless data lakes – Part 1
In this two-part series, we show you how to build a data pipeline in support of a data lake. We use key AWS services such as Amazon Kinesis Data Streams, Kinesis Data Analytics, Kinesis Data Firehose, and AWS Lambda. In part 2, we focus on generating simple inferences from that data that can support RTP parameters.
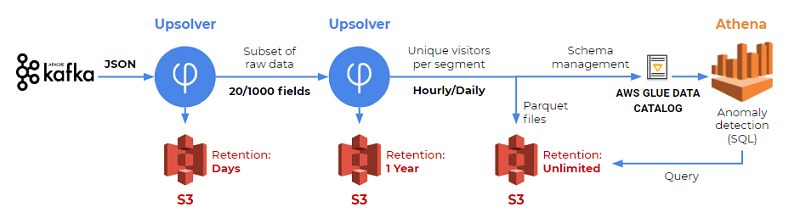
How SimilarWeb analyze hundreds of terabytes of data every month with Amazon Athena and Upsolver
This is a guest post by Yossi Wasserman, a data collection & innovation team leader at Similar Web. SimilarWeb, in their own words: SimilarWeb is the pioneer of market intelligence and the standard for understanding the digital world. SimilarWeb provides granular insights about any website or mobile app across all industries in every region. SimilarWeb […]