AWS Big Data Blog
Category: Amazon Athena
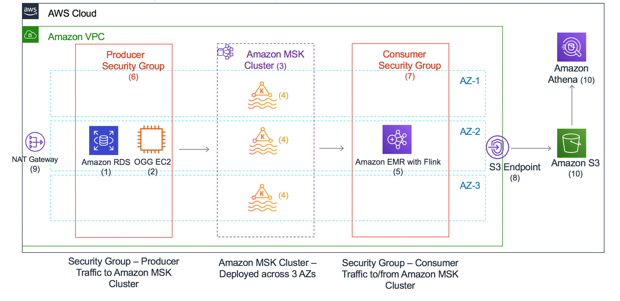
Extract Oracle OLTP data in real time with GoldenGate and query from Amazon Athena
This post describes how you can improve performance and reduce costs by offloading reporting workloads from an online transaction processing (OLTP) database to Amazon Athena and Amazon S3. The architecture described allows you to implement a reporting system and have an understanding of the data that you receive by being able to query it on arrival.
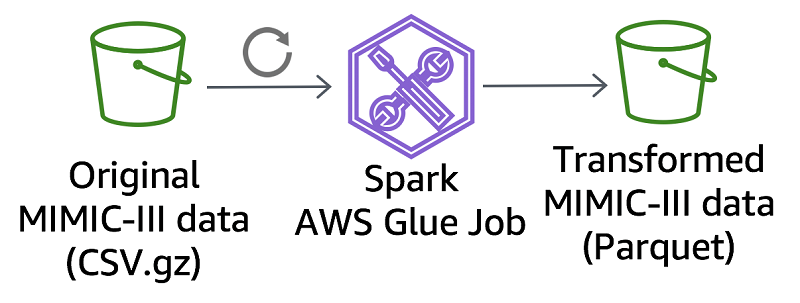
Perform biomedical informatics without a database using MIMIC-III data and Amazon Athena
This post describes how to make the MIMIC-III dataset available in Athena and provide automated access to an analysis environment for MIMIC-III on AWS. We also compare a MIMIC-III reference bioinformatics study using a traditional database to that same study using Athena.

Analyzing AWS WAF logs with Amazon OpenSearch, Amazon Athena, and Amazon QuickSight
This post presents a simple approach to aggregating AWS WAF logs into a central data lake repository, which lets teams better analyze and understand their organization’s security posture. I walk through the steps to aggregate regional AWS WAF logs into a dedicated S3 bucket. I follow that up by demonstrating how you can use Amazon ES to visualize the log data. I also present an option to offload and process historical data using AWS Glue ETL. With the data collected in one place, I finally show you how you can use Amazon Athena and Amazon QuickSight to query historical data and extract business insights.
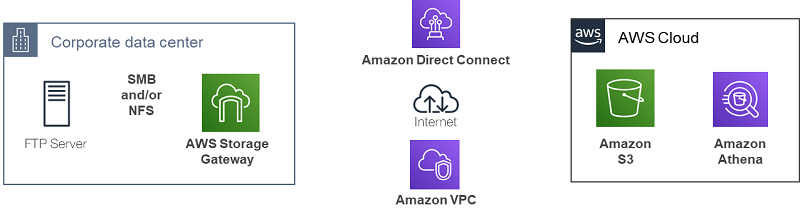
Query your data created on-premises using Amazon Athena and AWS Storage Gateway
In this blog post, I use this architecture to demonstrate the combined capabilities of Storage Gateway and Athena. AWS Storage Gateway is a hybrid storage service that enables your on-premises applications to seamlessly use AWS cloud storage. The File Gateway configuration of the AWS Storage Gateway offers you a seamless way to connect to the cloud in order to store application data files and backup images as durable objects on Amazon S3 cloud storage.
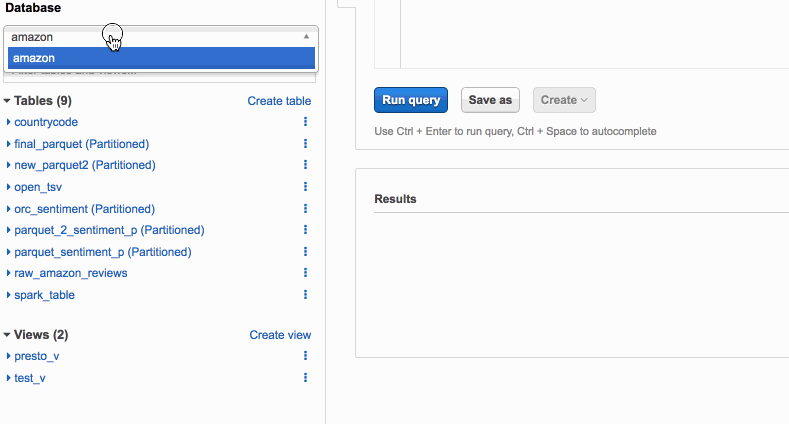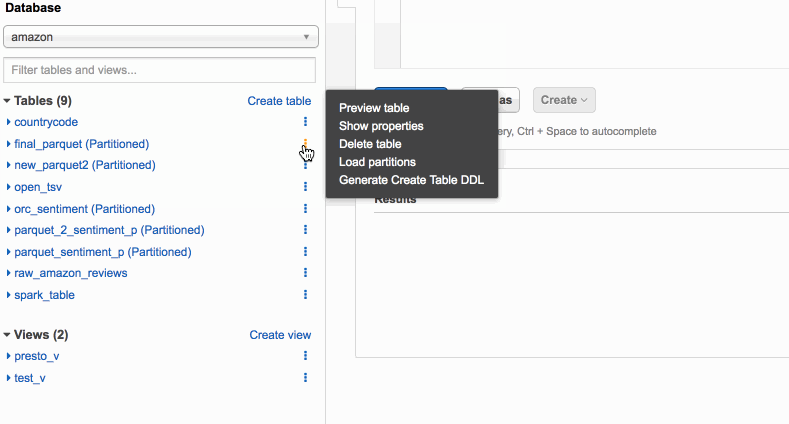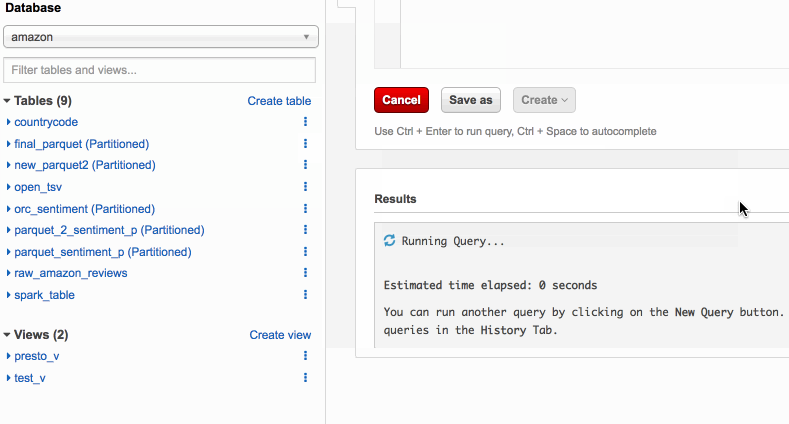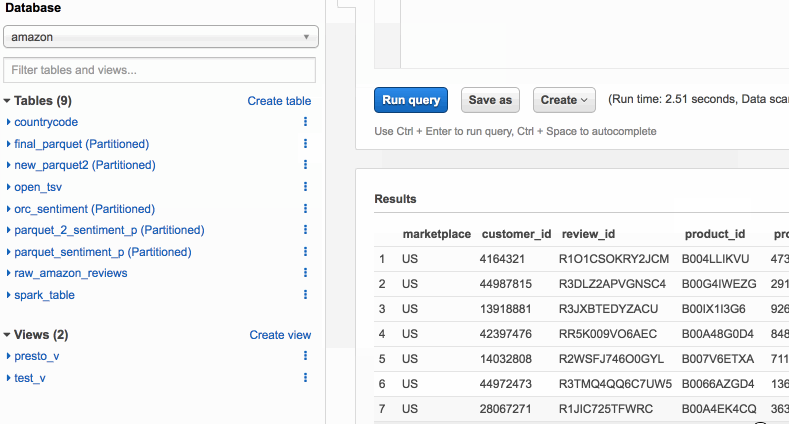
Separate queries and managing costs using Amazon Athena workgroups
Amazon Athena is a serverless query engine for data on Amazon S3. Many customers use Athena to query application and service logs, schedule automated reports, and integrate with their applications, enabling new analytics-based capabilities. Different types of users rely on Athena, including business analysts, data scientists, security, and operations engineers. In this post, I show you how to use workgroups to separate workloads, control user access, and manage query usage and costs.
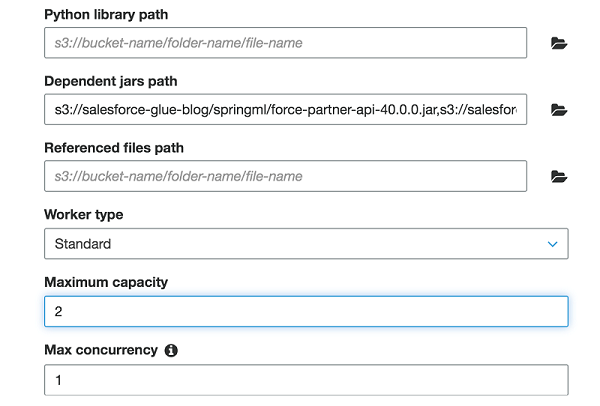
Extract Salesforce.com data using AWS Glue and analyzing with Amazon Athena
In this post, I show you how to use AWS Glue to extract data from a Salesforce.com account object and save it to Amazon S3. You then use Amazon Athena to generate a report by joining the account object data from Salesforce.com with the orders data from a separate order management system.

Detect fraudulent calls using Amazon QuickSight ML insights
The financial impact of fraud in any industry is massive. According to the Financial Times article Fraud Costs Telecoms Industry $17bn a Year (paid subscription required), fraud costs the telecommunications industry $17 billion in lost revenues every year. Fraudsters constantly look for new technologies and devise new techniques. This changes fraud patterns and makes detection […]

Trigger cross-region replication of pre-existing objects using Amazon S3 inventory, Amazon EMR, and Amazon Athena
In Amazon Simple Storage Service (Amazon S3), you can use cross-region replication (CRR) to copy objects automatically and asynchronously across buckets in different AWS Regions. CRR is a bucket-level configuration, and it can help you meet compliance requirements and minimize latency by keeping copies of your data in different Regions. CRR replicates all objects in […]

Easily query AWS service logs using Amazon Athena
In this post, we’re open-sourcing a Python library known as Athena Glue Service Logs (AGSlogger). This library has predefined templates for parsing and optimizing the most popular log formats. The library provides a mechanism for defining schemas, managing partitions, and transforming data within an extract, transform, load (ETL) job in AWS Glue. AWS Glue is a serverless data transformation and cataloging service. You can use this library in conjunction with AWS Glue ETL jobs to enable a common framework for processing log data.

Visualize over 200 years of global climate data using Amazon Athena and Amazon QuickSight
Climate Change continues to have a profound effect on our quality of life. As a result, the investigation into sustainability is growing. Researchers in both the public and private sector are planning for the future by studying recorded climate history and using climate forecast models. To help explain these concepts, this post introduces the Global […]