AWS Big Data Blog
Category: Amazon Redshift

Simplify data loading into Type 2 slowly changing dimensions in Amazon Redshift
Thousands of customers rely on Amazon Redshift to build data warehouses to accelerate time to insights with fast, simple, and secure analytics at scale and analyze data from terabytes to petabytes by running complex analytical queries. Organizations create data marts, which are subsets of the data warehouse and usually oriented for gaining analytical insights specific […]

How gaming companies can use Amazon Redshift Serverless to build scalable analytical applications faster and easier
This post provides guidance on how to build scalable analytical solutions for gaming industry use cases using Amazon Redshift Serverless. It covers how to use a conceptual, logical architecture for some of the most popular gaming industry use cases like event analysis, in-game purchase recommendations, measuring player satisfaction, telemetry data analysis, and more. This post […]

How Tricentis unlocks insights across the software development lifecycle at speed and scale using Amazon Redshift
This is a guest post co-written with Parag Doshi, Guru Havanur, and Simon Guindon from Tricentis. Tricentis is a global leader in continuous testing for DevOps, cloud, and enterprise applications. It has been well published since the State of DevOps 2019 DORA Metrics were published that with DevOps, companies can deploy software 208 times more […]
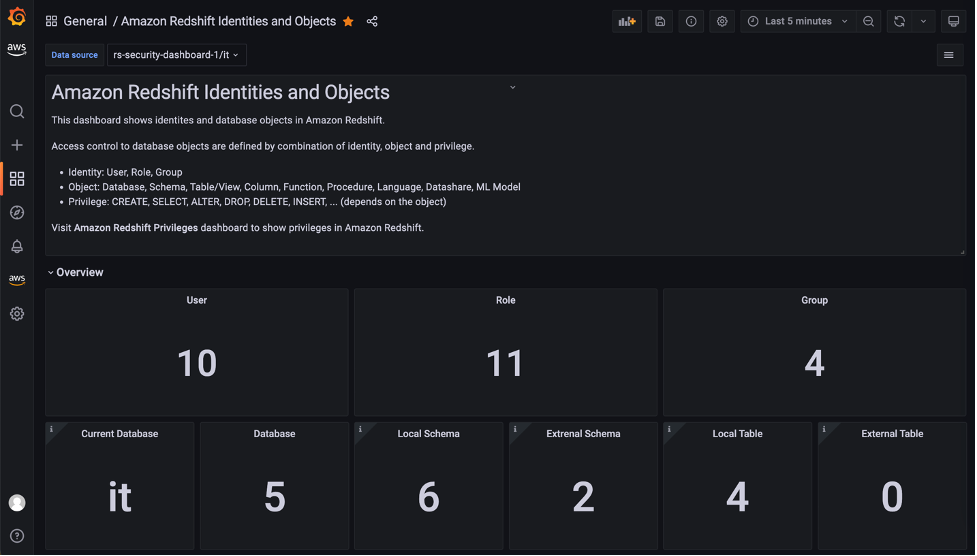
Visualize database privileges on Amazon Redshift using Grafana
Amazon Redshift is a fully managed, petabyte-scale data warehouse service in the cloud. Amazon Redshift enables you to use SQL for analyzing structured and semi-structured data with best price performance along with secure access to the data. As more users start querying data in a data warehouse, access control is paramount to protect valuable organizational […]

Simplify Online Analytical Processing (OLAP) queries in Amazon Redshift using new SQL constructs such as ROLLUP, CUBE, and GROUPING SETS
Amazon Redshift is a fully managed, petabyte-scale, massively parallel data warehouse that makes it fast, simple, and cost-effective to analyze all your data using standard SQL and your existing business intelligence (BI) tools. We are continuously investing to make analytics easy with Redshift by simplifying SQL constructs and adding new operators. Now we are adding […]

Patterns for enterprise data sharing at scale
Data sharing is becoming an important element of an enterprise data strategy. AWS services like AWS Data Exchange provide an avenue for companies to share or monetize their value-added data with other companies. Some organizations would like to have a data sharing platform where they can establish a collaborative and strategic approach to exchange data […]

A hybrid approach in healthcare data warehousing with Amazon Redshift
Data warehouses play a vital role in healthcare decision-making and serve as a repository of historical data. A healthcare data warehouse can be a single source of truth for clinical quality control systems. Data warehouses are mostly built using the dimensional model approach, which has consistently met business needs. Loading complex multi-point datasets into a […]

Build a data storytelling application with Amazon Redshift Serverless and Toucan
This post was co-written with Django Bouchez, Solution Engineer at Toucan. Business intelligence (BI) with dashboards, reports, and analytics remains one of the most popular use cases for data and analytics. It provides business analysts and managers with a visualization of the business’s past and current state, helping leaders make strategic decisions that dictate the […]

How OLX Group migrated to Amazon Redshift RA3 for simpler, faster, and more cost-effective analytics
This is a guest post by Miguel Chin, Data Engineering Manager at OLX Group and David Greenshtein, Specialist Solutions Architect for Analytics, AWS. OLX Group is one of the world’s fastest-growing networks of online marketplaces, operating in over 30 countries around the world. We help people buy and sell cars, find housing, get jobs, buy […]

Synchronize your Salesforce and Snowflake data to speed up your time to insight with Amazon AppFlow
This post was co-written with Amit Shah, Principal Consultant at Atos. Customers across industries seek meaningful insights from the data captured in their Customer Relationship Management (CRM) systems. To achieve this, they combine their CRM data with a wealth of information already available in their data warehouse, enterprise systems, or other software as a service […]