AWS Big Data Blog
Category: Amazon Comprehend

Unstructured data management and governance using AWS AI/ML and analytics services
In this post, we discuss how AWS can help you successfully address the challenges of extracting insights from unstructured data. We discuss various design patterns and architectures for extracting and cataloging valuable insights from unstructured data using AWS. Additionally, we show how to use AWS AI/ML services for analyzing unstructured data.
Simplify data discovery for business users by adding data descriptions in the AWS Glue Data Catalog
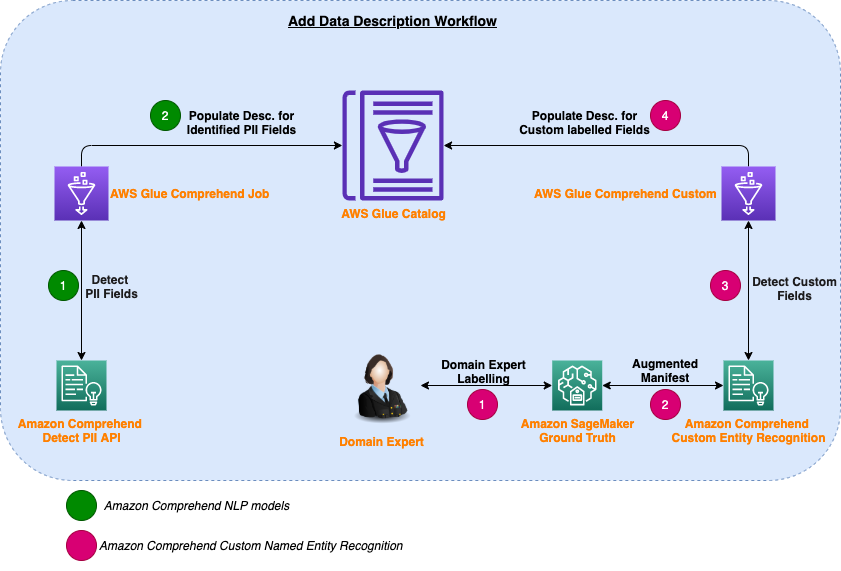
In this post, we discuss how to use AWS Glue Data Catalog to simplify the process for adding data descriptions and allow data analysts to access, search, and discover this cataloged metadata with BI tools. In this solution, we use AWS Glue Data Catalog, to break the silos between cross-functional data producer teams, sometimes also known […]

Create a secure data lake by masking, encrypting data, and enabling fine-grained access with AWS Lake Formation
You can build data lakes with millions of objects on Amazon Simple Storage Service (Amazon S3) and use AWS native analytics and machine learning (ML) services to process, analyze, and extract business insights. You can use a combination of our purpose-built databases and analytics services like Amazon EMR, Amazon OpenSearch Service, and Amazon Redshift as […]