AWS Big Data Blog
Category: AWS Big Data

Developing, testing, and deploying custom connectors for your data stores with AWS Glue
AWS Glue is a serverless data integration service that makes it easy to discover, prepare, and combine data for analytics, machine learning, and application development. AWS Glue already integrates with various popular data stores such as the Amazon Redshift, RDS, MongoDB, and Amazon S3. Organizations continue to evolve and use a variety of data stores that best fit […]

Migrating data from Google BigQuery to Amazon S3 using AWS Glue custom connectors
July, 2022: This post was reviewed and updated to include a mew data point on the effective runtime with the latest version, explaining Glue 3,0 and autoscaling. October, 2024: In Glue 4.0 we have introduced a native and managed connector for Google BigQuery. You can follow the instruction in the blog postUnlock scalable analytics with […]

Building AWS Glue Spark ETL jobs using Amazon DocumentDB (with MongoDB compatibility) and MongoDB
AWS Glue is a fully managed extract, transform, and load (ETL) service that makes it easy to prepare and load your data for analytics. AWS Glue has native connectors to connect to supported data sources on AWS or elsewhere using JDBC drivers. Additionally, AWS Glue now supports reading and writing to Amazon DocumentDB (with MongoDB […]

Amazon Redshift 2020 year in review
Today, more data is created every hour than in an entire year just 20 years ago. Successful organizations are leveraging this data to deliver better service to their customers, improve their products, and run an efficient and effective business. As the importance of data and analytics continues to grow, the Amazon Redshift cloud data warehouse […]

Writing to Apache Hudi tables using AWS Glue Custom Connector
December 2022: This post was reviewed for accuracy. In today’s world, most organizations have to tackle the 3 V’s of variety, volume and velocity of big data. In this blog post, we talk about dealing with the variety and volume aspects of big data. The challenge of dealing with the variety involves processing data from […]

Building a cost efficient, petabyte-scale lake house with Amazon S3 lifecycle rules and Amazon Redshift Spectrum: Part 1
The continuous growth of data volumes combined with requirements to implement long-term retention (typically due to specific industry regulations) puts pressure on the storage costs of data warehouse solutions, even for cloud native data warehouse services such as Amazon Redshift. The introduction of the new Amazon Redshift RA3 node types helped in decoupling compute from […]

Run Apache Spark 3.0 workloads 1.7 times faster with Amazon EMR runtime for Apache Spark
With Amazon EMR release 6.1.0, Amazon EMR runtime for Apache Spark is now available for Spark 3.0.0. EMR runtime for Apache Spark is a performance-optimized runtime for Apache Spark that is 100% API compatible with open-source Apache Spark. In our benchmark performance tests using TPC-DS benchmark queries at 3 TB scale, we found EMR runtime […]

Building fast ETL using SingleStore and AWS Glue
Disparate data systems have become a norm in many companies. The reasons for this vary: different teams in the organization select data system best suited for its primary function, the responsibility for choosing these data systems may have been decentralized across different departments, a merged company may still use separate data systems from the formerly […]
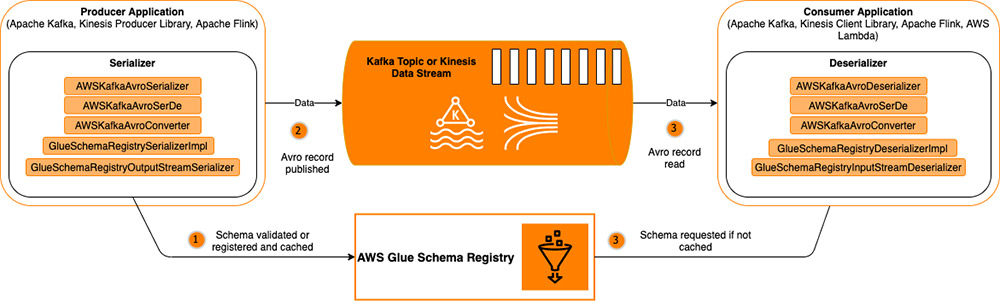
Validate, evolve, and control schemas in Amazon MSK and Amazon Kinesis Data Streams with AWS Glue Schema Registry
August 30, 2023: Amazon Kinesis Data Analytics has been renamed to Amazon Managed Service for Apache Flink. Read the announcement in the AWS News Blog and learn more. Data streaming technologies like Apache Kafka and Amazon Kinesis Data Streams capture and distribute data generated by thousands or millions of applications, websites, or machines. These technologies […]
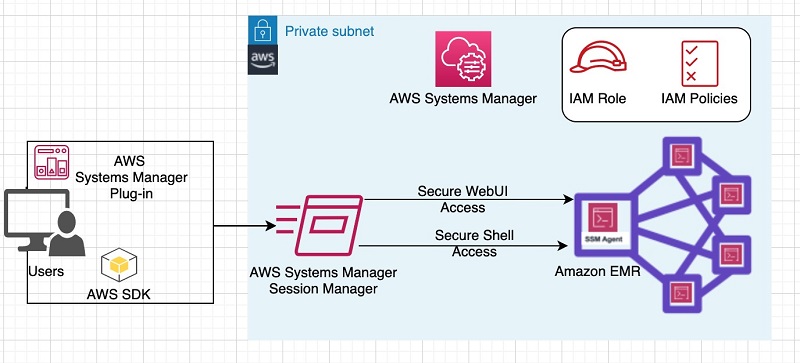
Securing access to EMR clusters using AWS Systems Manager
Organizations need to secure infrastructure when enabling access to engineers to build applications. Opening SSH inbound ports on instances to enable engineer access introduces the risk of a malicious entity running unauthorized commands. Using a Bastion host or jump server is a common approach used to allow engineer access to Amazon EMR cluster instances by […]