AWS Big Data Blog
Amazon Redshift 2020 year in review
Today, more data is created every hour than in an entire year just 20 years ago. Successful organizations are leveraging this data to deliver better service to their customers, improve their products, and run an efficient and effective business. As the importance of data and analytics continues to grow, the Amazon Redshift cloud data warehouse service is evolving to meet the needs of our customers. Amazon Redshift was the first data warehouse built for the cloud in 2012, and we’ve constantly listened to our customers to deliver on our promise of a fast, scalable, and easy-to-use service that makes it possible to deliver insight across an organization with a single and consistent view of your data—even with the enormous growth in data we’re experiencing. That’s why tens of thousands of customers like Nasdaq, Dollar Shave Club, and VOO are betting on Amazon Redshift to gain the insight they need. You can hear from customers about how they’re using Amazon Redshift in the AWS re:Invent 2020 sessions How Twilio scaled business intelligence with a data lake powered by AWS and How Vyaire uses AWS analytics to scale ventilator product and save lives.
In 2020, we continued to innovate at a fast clip, releasing dozens of new features and capabilities to make it easier to analyze all your data with a Lake House Architecture, get fast performance at any scale, and lower your costs with predictable pricing. Some of these new features were major efforts that required extensive development and engineering work, and others were relatively minor, but when considered as an aggregate make a big difference to our customers’ ability to do things like migrate to Amazon Redshift from legacy on-premises data warehouses, or support new use cases.
Lake House and AWS integrated
At AWS, we believe in adopting a Lake House Architecture so you can easily integrate your data warehouse with the data lake on Amazon Simple Storage Service (Amazon S3), purpose-built data stores, and with other analytics services without moving and transforming your data explicitly. For more information about this approach, see the post Harness the power of your data with AWS Analytics by Rahul Pathak, and watch his AWS re:Invent 2020 analytics leadership session.
The following image shows how Amazon Redshift integrates with the data lake and other services.
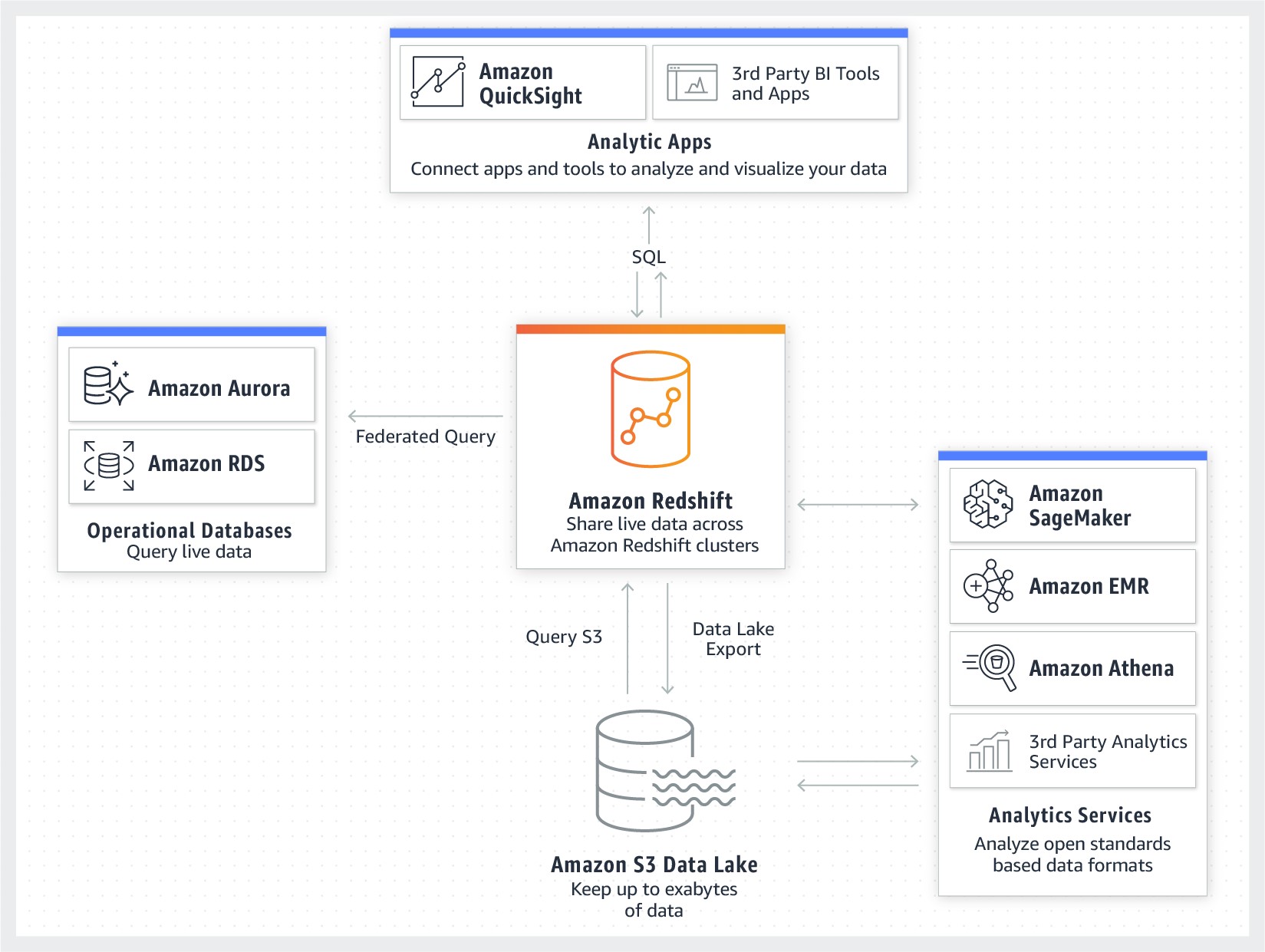
Since we released the Amazon Redshift Spectrum feature a couple years ago, customers have been querying exabytes of data directly in the lake in Apache Parquet, an open file format. With data lake export released in 2019, you can save the results of an Amazon Redshift query back into the lake. This means you can take advantage of (or be ready to evolve to) real-time analytics and machine learning (ML) and AI use cases without re-architecture, because Amazon Redshift is fully integrated with your data lake. In 2020, we also released new capabilities like Amazon Redshift data sharing (preview), so you can easily share data across Amazon Redshift clusters (both internally and externally) so every user has a live and consistent view of data.
Customers like Warner Bros. Interactive Entertainment, Yelp, Fannie Mae, and many more are benefitting from data sharing. Steven Moy from Yelp shared, “The data sharing feature seamlessly allows multiple Redshift clusters to query data located in our RA3 clusters and their managed storage. This eliminates our concerns with delays in making data available for our teams, and reduces the amount of data duplication and associated backfill headache. We now can concentrate even more of our time making use of our data in Redshift and enable better collaboration instead of data orchestration.”
With Amazon Redshift Federated Query, you can combine operational data that is stored in popular databases such as Amazon Relational Database Service (Amazon RDS) and Amazon Aurora PostgreSQL. We also offer Amazon RDS for MySQL and Amazon Aurora MySQL support in preview. For more information, see Announcing Amazon Redshift federated querying to Amazon Aurora MySQL and Amazon RDS for MySQL.
We also launched a native integration with Amazon SageMaker, Amazon Redshift ML (preview), to make it easy to do more with your data with predictive analytics. Now you can create, train, and deploy ML models with SQL on your Amazon Redshift data without relying on an ML expert or learning new tools and languages.
Customers and partners like Datacoral, ZS Associates, Rackspace, and Slalom are benefiting from Amazon Redshift ML. Raghu Murthy from Datacoral shared, “We are really excited about the new Amazon Redshift ML feature. Typically, our mutual customers need to extract data from Amazon Redshift to perform inference for ML. Now that this can be done natively within Amazon Redshift, we see the potential for a huge performance and productivity improvement. We look forward to helping more customers use ML on the data in their Amazon Redshift data warehouse, and to speeding up the inference pipelines our customers are already using ML with this new capability.”
In addition to querying semi-structured data using Amazon Redshift Spectrum in the lake, in 2020 we launched native support for semi-structured data processing with the SUPER data type (preview). This new data type, SUPER, supports nested data formats such as JSON and enables you to ingest, store, and query nested data natively in Amazon Redshift. SUPER data can be queried using PartiQL, a SQL extension used for easily querying both semi-structured and structured data.
Other features we released in 2020 that support the Lake House Architecture and AWS integrations include AWS Lambda UDF, partner console integration (preview), support for writing to external tables in Amazon S3, the ability to query open-source Apache Hudi and Delta Lake, and much more.
Learn more about the Lake House Architecture in the AWS re:Invent 2020 session The lake house approach to data warehousing with Amazon Redshift, and dive deep into the new data sharing features in the sessions New use cases for Amazon Redshift and Introducing Amazon Redshift ML.
Performance at scale
Amazon Redshift has always been built for fast performance at scale—we know this is important to our customers because you want a data warehouse you can trust to deliver results quickly across all your data. With Amazon Redshift, you get up to 3x better price performance than other cloud data warehouses, and we recently published our benchmark results so you can learn more and even replicate the tests. The benchmarking test was performed with a single cluster, and for customers that have high concurrency workloads, we offer concurrency scaling to scale out your read workloads.
We know you count on Amazon Redshift to deliver consistently fast results from gigabytes to petabytes of data, and from a few users to thousands. As your users scale, the concurrency scaling capability of Amazon Redshift automatically deploys the necessary compute resources to manage the additional load. And, because we know your workloads are growing fast, we’re building Amazon Redshift for the new scale of data with features like AQUA (Advanced Query Accelerator), a new hardware accelerated cache that boosts queries up to 10x faster than other cloud data warehouses. AQUA is available in preview on RA3 4xl and 16xl nodes in select Regions, and will be generally available in January, 2021.
In 2020, we also invested a lot in making it easier to get the best performance by releasing new capabilities for Amazon Redshift to be a self-tuning and self-learning system. This allows you to get the best performance for your workloads without the undifferentiated heavy lifting of tuning your data warehouse with tasks such as defining sort keys, and distribution keys and new capabilities like materialized views, and automatic refresh and query rewrite of materialized views.
Based on internal benchmarking, optimizations made by the automatic table optimization feature have been shown to increase cluster performance by 24% and 34% using the 3 TB and 30 TB TPC-DS benchmarks, respectively, versus a cluster without automatic table optimization. When professional services firm ZS Associates started using automatic table optimizations, Nishesh Aggarwal shared, “When we tested ATO in our development environment, the performance of our queries was 25% faster than our production workload not using ATO, without requiring any additional effort by our administrators.”
Other features delivered in 2020 that support performance at scale include query compilation improvements, 100k table support, HyperLogLog, and much more.
Find out more about how Amazon.com uses Amazon Redshift to perform analytics at scale in the following AWS re:Invent 2020 session, dive deep into the new features with the session Getting the most out of Amazon Redshift automation, and learn more about AQUA with AQUA for Amazon Redshift (Preview).
Best value
We focus on our customers and innovate to ensure Amazon Redshift provides great value, whether you’re starting small at $0.25 per hour or committing with Reserved Instances that allow you save up to 75% compared to on-demand prices when you commit to a 1- or 3-year term. In 2020, we heard from many new and existing customers about the value and performance gains they experienced from the new generation instance type, RA3 with managed storage. By scaling and paying for storage and compute separately, you get the optimal amount of storage and compute for diverse workloads. RA3 allows you to choose the size of your Amazon Redshift cluster based on your performance requirements, and Amazon Redshift managed storage automatically scales your data warehouse storage capacity without you having to add and pay for additional compute instances. In early 2020, we released RA3.4xl, and more recently completed the family with the new and smallest instance size, RA3.xlplus.
Unlike other cloud DWs where you need premium versions for additional enterprise capabilities, Amazon Redshift pricing includes built-in security-like encryption, audit logs, and compliance, and launches within your virtual private cloud (VPC), as well as data compression and data transfer. Amazon Redshift also provides predictability in month-to-month cost even when you have unpredictable or highly concurrent workloads. Each Amazon Redshift cluster earns up to an hour of free concurrency scaling credits per day, which can be used to offset the cost of the transient clusters that are automatically added to handle high concurrency. Additionally, in 2020 we released new cost control features for Amazon Redshift Spectrum and concurrency scaling.
The automatic workload manager (WLM) was updated in 2020 to make it even more effective to help you run a complex mix of applications. A successful workload management scheme ensures SLAs for high-priority workloads, ensures highly efficient resource utilization, and maximizes return on investment (ROI). One approach to solve this problem is to simply add more resources, but this approach is problematic because it leads to unpredictable spend and high invoices. WLM in Amazon Redshift helps you maximize query throughput and get consistent performance for the most demanding analytics workloads, all while optimizing the resources that you’re already paying for. For example, with query priorities, you can now ensure that higher-priority workloads get preferential treatment in Amazon Redshift, including more resources during busy times for consistent query performance. Query monitoring rules provides ways to manage unexpected situations like detecting and preventing runaway or expensive queries from consuming system resources.
We also improved automatic WLM in several ways. It now uses ML to predict the amount of resources a query needs, allowing us to improve overall throughput. In addition, WLM now scales concurrency dynamically, and we enhanced SQA (short query acceleration) with what we call “turbo boost mode,” a feature that is automatically activated when queue buildup is detected and waiting queries don’t require a lot of resources. This allows for more consistent query performance for all queries regardless of priority, as well as more efficient utilization of resources overall.
Many of our customers have started using the Data API released in 2020 to build web services-based applications and to integrate with services like AWS Lambda, AWS AppSync, and AWS Cloud9. The Data API simplifies data access, ingest, and egress from languages supported with AWS SDK such as Python, Go, Java, Node.js, PHP, Ruby, and C++, so you can focus on building applications versus managing infrastructure.
Other features delivered in 2020 that make sure you get the best value out of Amazon Redshift include cross-AZ cluster recovery, open-source JDBC and Python drivers, spatial data processing enhancements, TIME and TIMETZ data types, scheduling of SQL queries, pause and resume, and much more.
Summary
For an overview of the new features, check out the AWS re:Invent 2020 session What’s new with Amazon Redshift and go deeper with the deep dive on best practices for Amazon Redshift. If you’re still evaluating whether a move to the cloud makes sense, learn more about migrating a legacy data warehouse to Amazon Redshift.
Thanks for all your feedback over the years and cheers to the insights you’ll be gaining from your AWS analytics solutions in 2021.
About the Authors
 Corina Radovanovich leads product marketing for cloud data warehousing at AWS. She’s worked in marketing and communications for the biggest tech companies worldwide and specializes in cloud data services.
Corina Radovanovich leads product marketing for cloud data warehousing at AWS. She’s worked in marketing and communications for the biggest tech companies worldwide and specializes in cloud data services.
 Eugene Kawamoto is a director of product management for Amazon Redshift. Eugene leads the product management and database engineering teams at AWS. He has been with AWS for ~8 years supporting analytics and database services both in Seattle and in Tokyo. In his spare time, he likes running trails in Seattle, loves finding new temples and shrines in Kyoto, and enjoys exploring his travel bucket list.
Eugene Kawamoto is a director of product management for Amazon Redshift. Eugene leads the product management and database engineering teams at AWS. He has been with AWS for ~8 years supporting analytics and database services both in Seattle and in Tokyo. In his spare time, he likes running trails in Seattle, loves finding new temples and shrines in Kyoto, and enjoys exploring his travel bucket list.