AWS Big Data Blog
Category: AWS Big Data

Building complex workflows with Amazon MWAA, AWS Step Functions, AWS Glue, and Amazon EMR
Amazon Managed Workflows for Apache Airflow (Amazon MWAA) is a fully managed service that makes it easy to run open-source versions of Apache Airflow on AWS and build workflows to run your extract, transform, and load (ETL) jobs and data pipelines. You can use AWS Step Functions as a serverless function orchestrator to build scalable […]
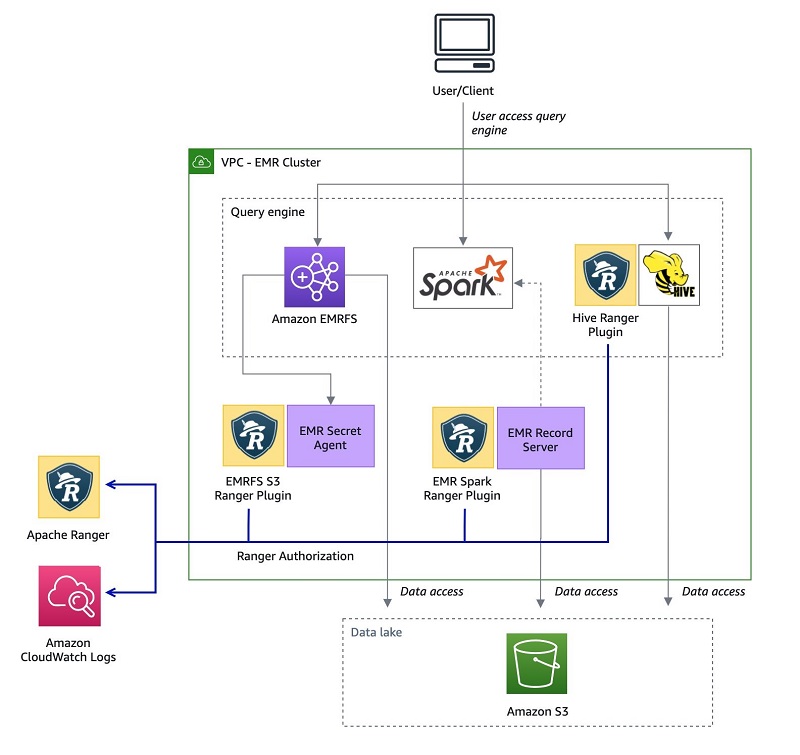
Introducing Amazon EMR integration with Apache Ranger
This post was last updated July 2022. Data security is an important pillar in data governance. It includes authentication, authorization , encryption and audit. Amazon EMR enables you to set up and run clusters of Amazon Elastic Compute Cloud (Amazon EC2) instances with open-source big data applications like Apache Spark, Apache Hive, Apache Flink, and Presto. You may […]
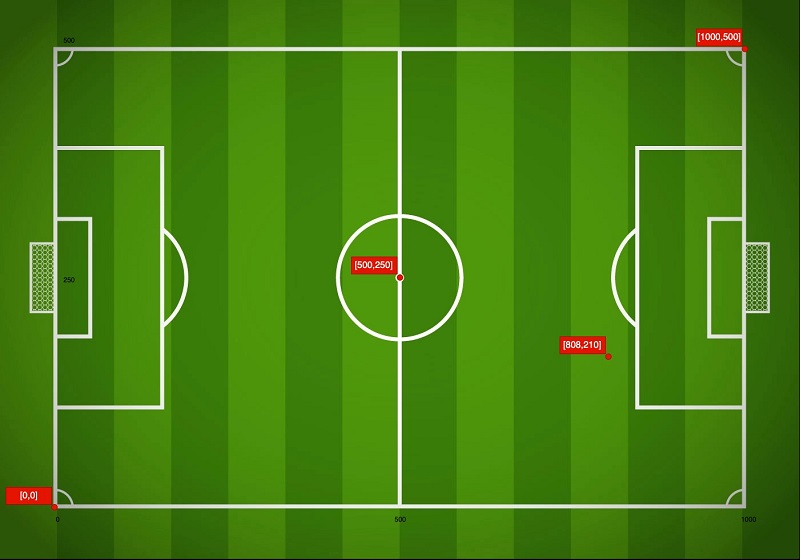
Estimating scoring probabilities by preparing soccer matches data with AWS Glue DataBrew
In soccer (or football outside of the US), players decide to take shots when they think they can score. But how do they make that determination vs. when to pass or dribble? In a fraction of a second, in motion, while chased from multiple directions by other professional athletes, they think about their distance from […]
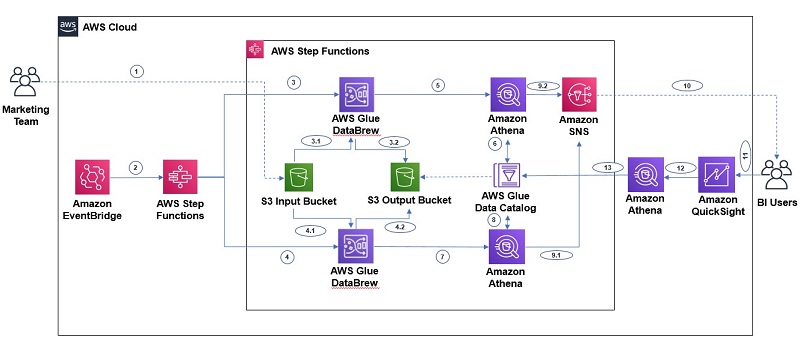
Orchestrating an AWS Glue DataBrew job and Amazon Athena query with AWS Step Functions
As the industry grows with more data volume, big data analytics is becoming a common requirement in data analytics and machine learning (ML) use cases. Also, as we start building complex data engineering or data analytics pipelines, we look for a simpler orchestration mechanism with graphical user interface-based ETL (extract, transform, load) tools. Recently, AWS […]
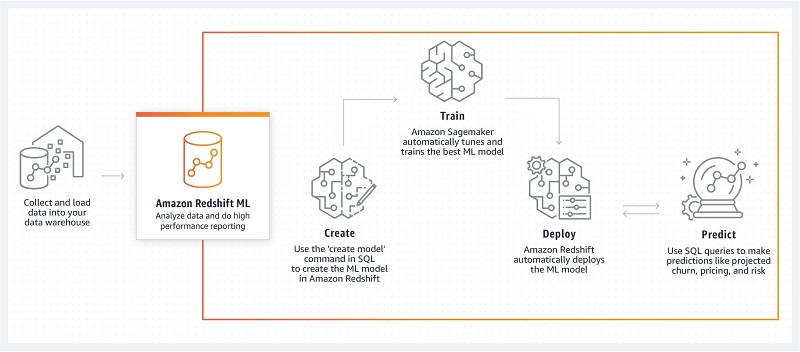
The best new features for data analysts in Amazon Redshift in 2020
This is a guest post by Helen Anderson, data analyst and AWS Data Hero Every year, the Amazon Redshift team launches new and exciting features, and 2020 was no exception. New features to improve the data warehouse service and add interoperability with other AWS services were rolling out all year. I am part of a […]
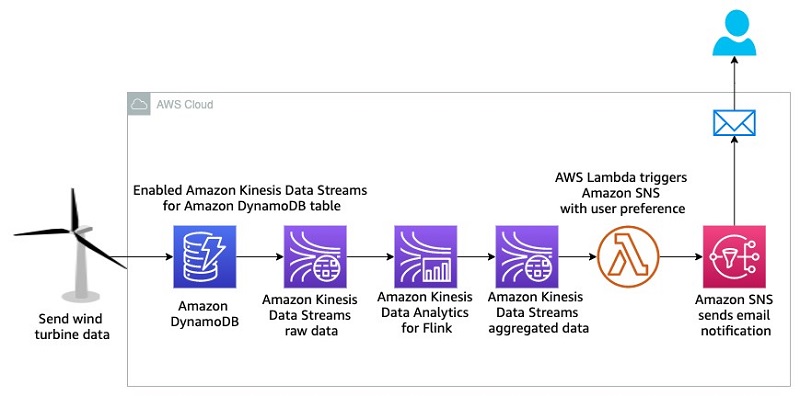
Building a real-time notification system with Amazon Kinesis Data Streams for Amazon DynamoDB and Amazon Kinesis Data Analytics for Apache Flink
August 30, 2023: Amazon Kinesis Data Analytics has been renamed to Amazon Managed Service for Apache Flink. Read the announcement in the AWS News Blog and learn more. Amazon DynamoDB helps you capture high-velocity data such as clickstream data to form customized user profiles and Internet of Things (IoT) data so that you can develop […]

Accessing and visualizing data from multiple data sources with Amazon Athena and Amazon QuickSight
Amazon Athena now supports federated query, a feature that allows you to query data in sources other than Amazon Simple Storage Service (Amazon S3). You can use federated queries in Athena to query the data in place or build pipelines that extract data from multiple data sources and store them in Amazon S3. With Athena […]
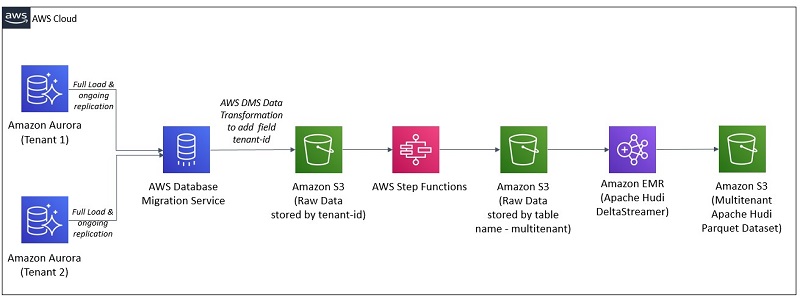
Multi-tenant processing pipelines with AWS DMS, AWS Step Functions, and Apache Hudi on Amazon EMR
Large enterprises often provide software offerings to multiple customers by providing each customer a dedicated and isolated environment (a software offering composed of multiple single-tenant environments). Because the data is in various independent systems, large enterprises are looking for ways to simplify data processing pipelines. To address this, you can create data lakes to bring […]
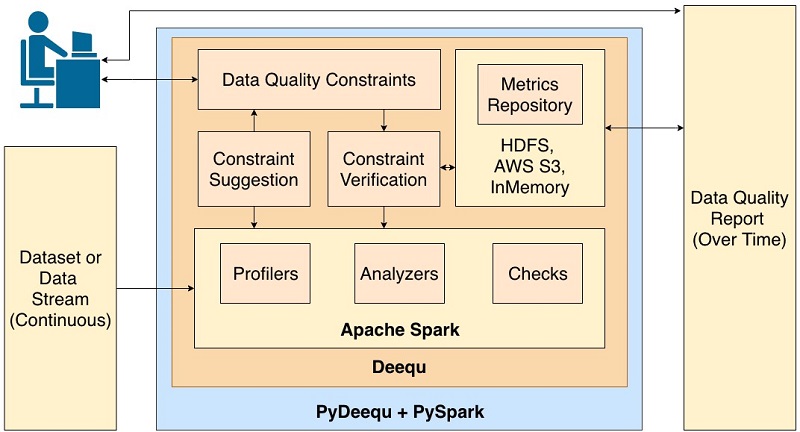
Testing data quality at scale with PyDeequ
June 2024: This post was reviewed and updated to add instructions for using PyDeequ with Amazon SageMaker Notebook, SageMaker Studio, EMR, and updated the examples against a new dataset. March 2023: You can now use AWS Glue Data Quality to measure and manage the quality of your data. AWS Glue Data Quality is built on Deequ […]

Running queries securely from the same VPC where an Amazon Redshift cluster is running
Customers who don’t need to set up a VPN or a private connection to AWS often use public endpoints to access AWS. Although this is acceptable for testing out the services, most production workloads need a secure connection to their VPC on AWS. If you’re running your production data warehouse on Amazon Redshift, you can […]