AWS Big Data Blog
Migrating data from Google BigQuery to Amazon S3 using AWS Glue custom connectors
July, 2022: This post was reviewed and updated to include a mew data point on the effective runtime with the latest version, explaining Glue 3,0 and autoscaling.
October, 2024: In Glue 4.0 we have introduced a native and managed connector for Google BigQuery. You can follow the instruction in the blog postUnlock scalable analytics with AWS Glue and Google BigQuery to implement your solution using Glue 4.0.
In today’s connected world, it’s common to have data sitting in various data sources in a variety of formats. Even though data is a critical component of decision making, for many organizations this data is spread across multiple public clouds. Organizations are looking for tools that make it easy to ingest data from these myriad data sources and be able to customize the data ingestion to meet their needs.
AWS Glue is a fully managed extract, transform, and load (ETL) service that makes it easy to prepare and load your data for analytics. AWS Glue provides all the capabilities needed for data integration and analysis can be done in minutes instead of weeks or months. AWS Glue custom connectors, a new capability in AWS Glue and AWS Glue Studio that makes it easy for you to transfer data from SaaS applications and custom data sources to your data lake in Amazon S3. With just a few clicks, you can search and select connectors from the AWS Marketplace and begin your data preparation workflow in minutes. You can also build custom connectors and share them across teams, and integrate open source Spark connectors and Athena federated query connectors into you data preparation workflows. Google BigQuery Connector for AWS Glue allows migrating data cross-cloud from Google BigQuery to Amazon Simple Storage Service (Amazon S3). AWS Glue Studio is a new graphical interface that makes it easy to create, run, and monitor extract, transform, and load (ETL) jobs in AWS Glue. You can visually compose data transformation workflows and seamlessly run them on AWS Glue’s Apache Spark-based serverless ETL engine.
In this post, we focus on using AWS Glue Studio to query BigQuery tables and save the data into Amazon Simple Storage Service (Amazon S3) in Parquet format, and then query it using Amazon Athena. To query BigQuery tables in AWS Glue, we use the new Google BigQuery Connector for AWS Glue from AWS Marketplace.
Solution Overview:
The following architecture diagram shows how AWS Glue connects to Google BigQuery for data ingestion.
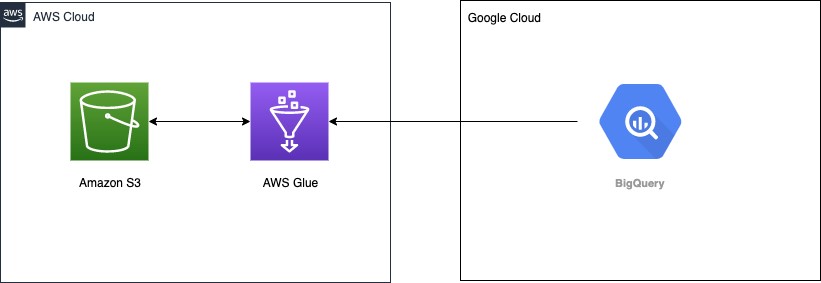
Prerequisites
Before getting started, make sure you have the following:
- An account in Google Cloud, specifically a service account that has permissions to Google BigQuery
- An AWS Identity and Access Management (IAM) user with an access key and secret key to configure the AWS Command Line Interface (AWS CLI)
- The IAM user also needs permissions to create an IAM role and policies
Configuring your Google account
We create a secret in AWS Secrets Manager to store the Google service account file contents as a base64-encoded string.
- Download the service account credentials JSON file from Google Cloud.
For base64 encoding, you can use one of the online utilities or system commands to do that. For Linux and Mac, you can use base64 <<service_account_json_file>> to print the file contents as a base64-encoded string.
- On the Secrets Manager console, choose Store a new secret.
- For Secret type, select Other type of secret.
- Enter your key as
credentialsand the value as the base64-encoded string. - Leave the rest of the options at their default.
- Choose Next.

- Give a name to the secret
bigquery_credentials. - Follow through the rest of the steps to store the secret.
For more information, see Tutorial: Creating and retrieving a secret.
Creating an IAM role for AWS Glue
The next step is to create an IAM role with the necessary permissions for the AWS Glue job. Attach the following AWS managed policies to the role:
Create and attach a policy to allow reading the secret from Secrets Manager and write access to the S3 bucket.
The following sample policy demonstrates the AWS Glue job as part of this post. Always make sure to scope down the policies before using in a production environment. Provide your secret ARN for the bigquery_credentials secret you created earlier and the S3 bucket for saving data from BigQuery:
Subscribing to the Glue BigQuery Connector
To subscribe to the connector, complete the following steps:
- Navigate to the Google BigQuery Connector for AWS Glue on AWS Marketplace.
- Choose Continue to Subscribe.
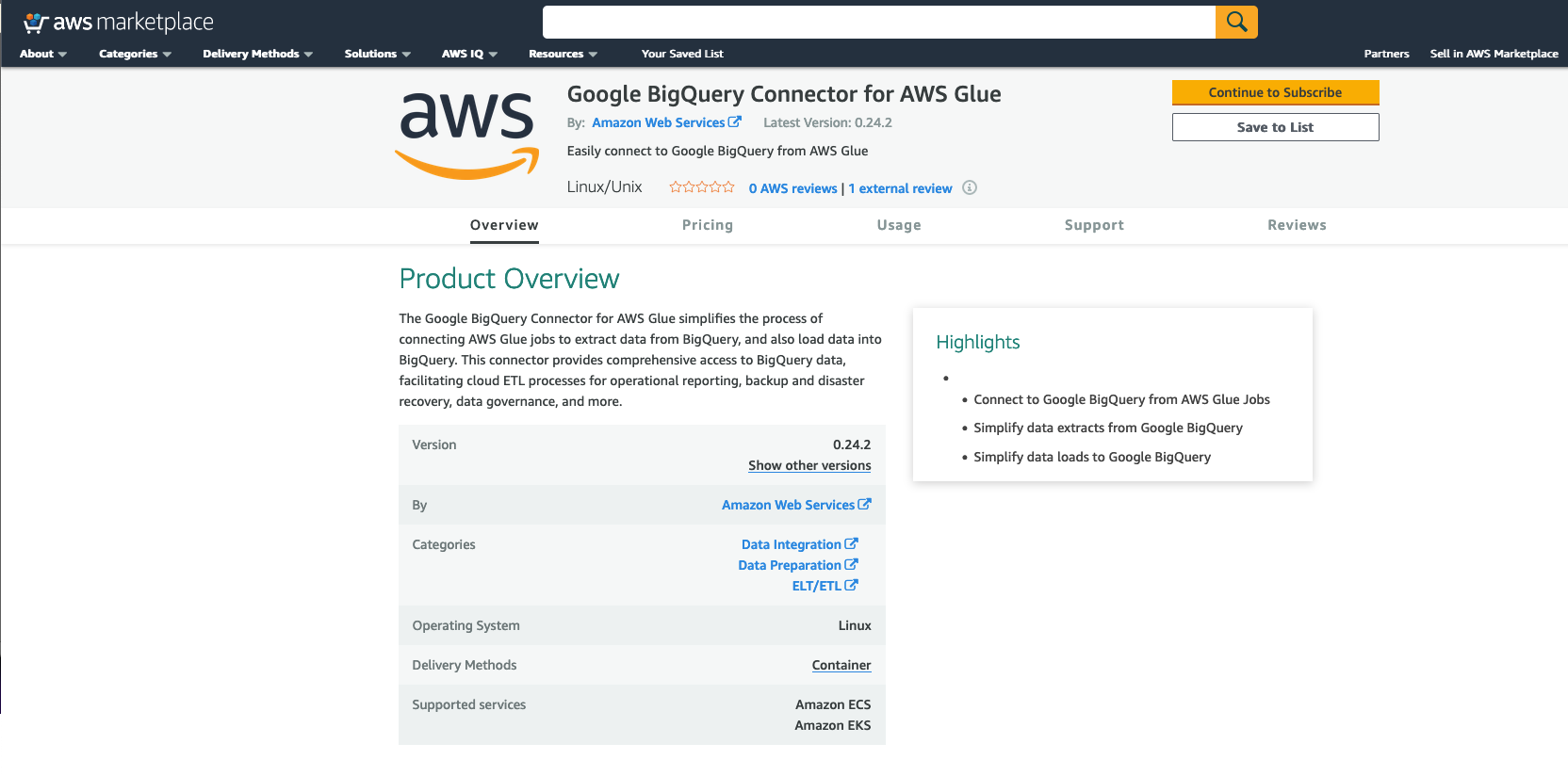
- Review the terms and conditions, pricing, and other details.
- Choose Continue to Configuration.
- For Fulfillment option, choose the AWS Glue Version you are using (3.0 or 1.0/2.0).
- For Software Version, choose your software version.
- Choose Continue to Launch.
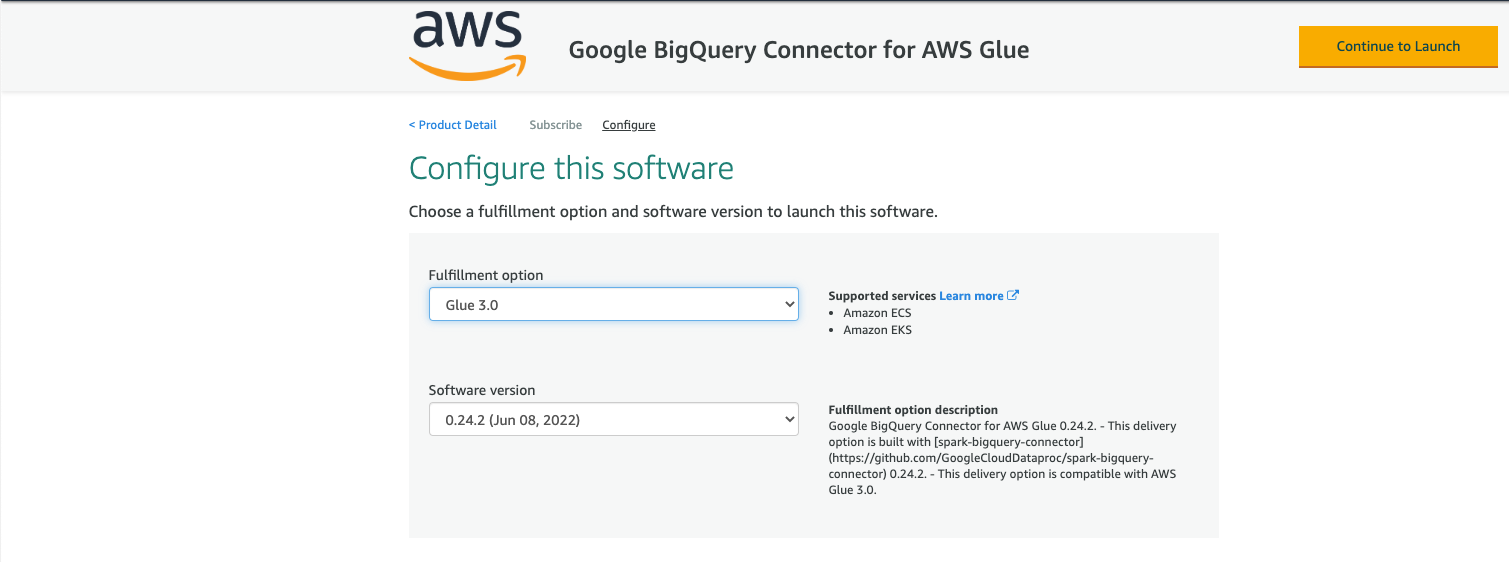
- Under Usage instructions, review the documentation then choose Activate the Glue connector from AWS Glue Studio.

You’re redirected to AWS Glue Studio.
- For Name, enter a name for your connection (for example,
bigquery). - Optionally, choose a VPC, subnet, and security group.
- For AWS Secret, choose
bigquery_credentials. - Choose Create connection and activate connector.
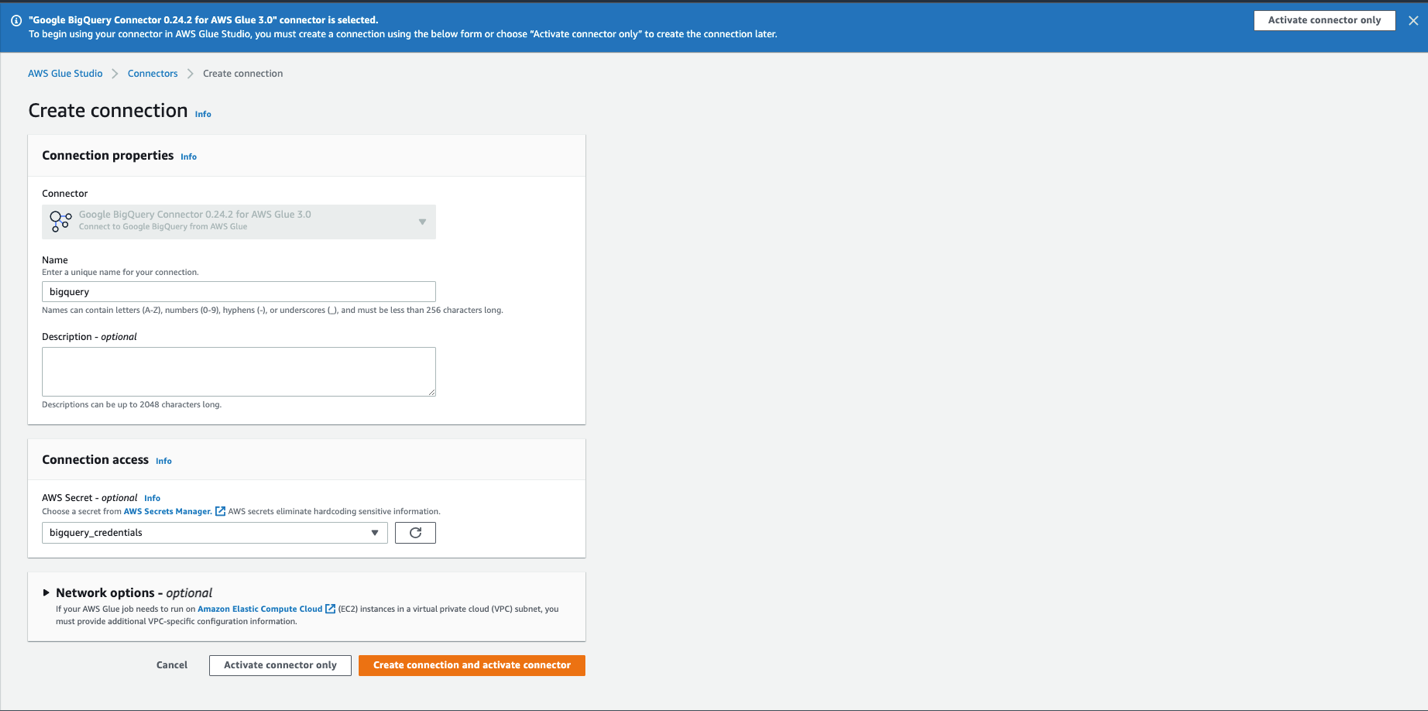
A message appears that the connection was successfully created, and the connection is now visible on the AWS Glue Studio console.
Creating the ETL job in AWS Glue Studio
- On Glue Studio, choose View jobs.
- For Source, choose
Google BigQuery Connector 0.24.2 for AWS Glue 3.0. - For Target, choose
Amazon S3. - Choose Create.

- Choose ApplyMapping and delete it.
- Choose Google BigQuery Con…
- For Connection, choose
bigguery. - Expand Connection options.
- Choose Add new option.
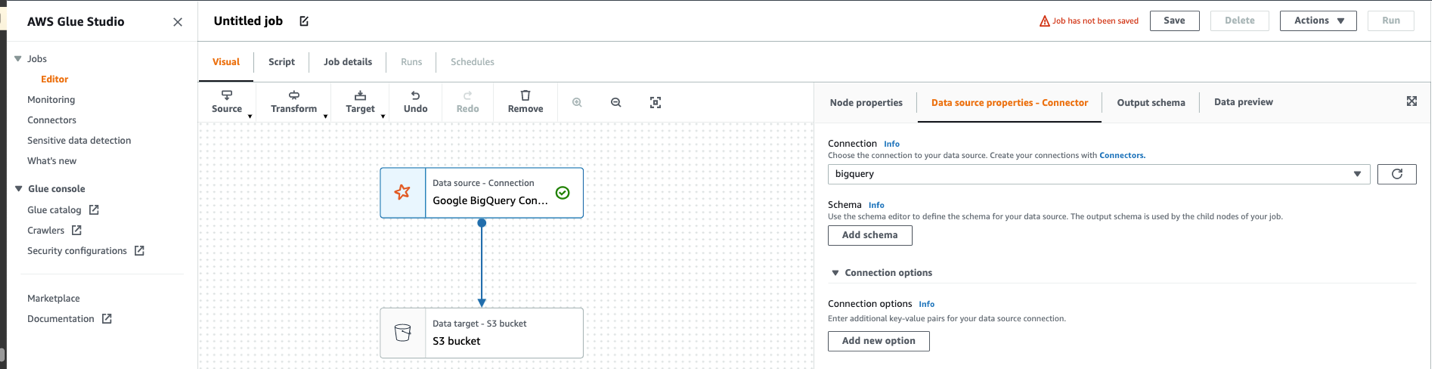
- Add following Key/Value.
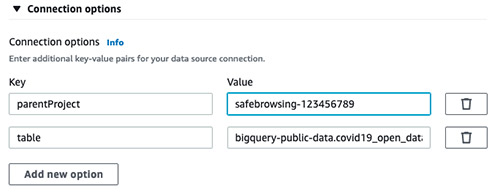
- Key:
parentProject, Value:<<google_project_id>> - Key:
table, Value:bigquery-public-data.covid19_open_data.covid19_open_data
- Key:
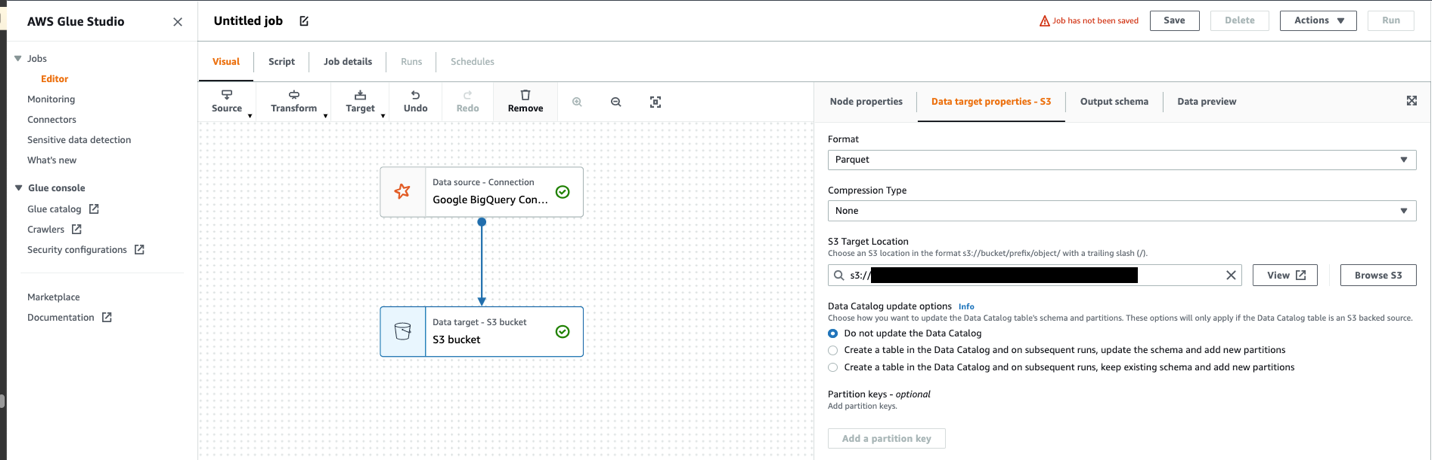
- Choose S3 bucket.
- Choose format and Compression Type.
- Specify S3 Target Location.
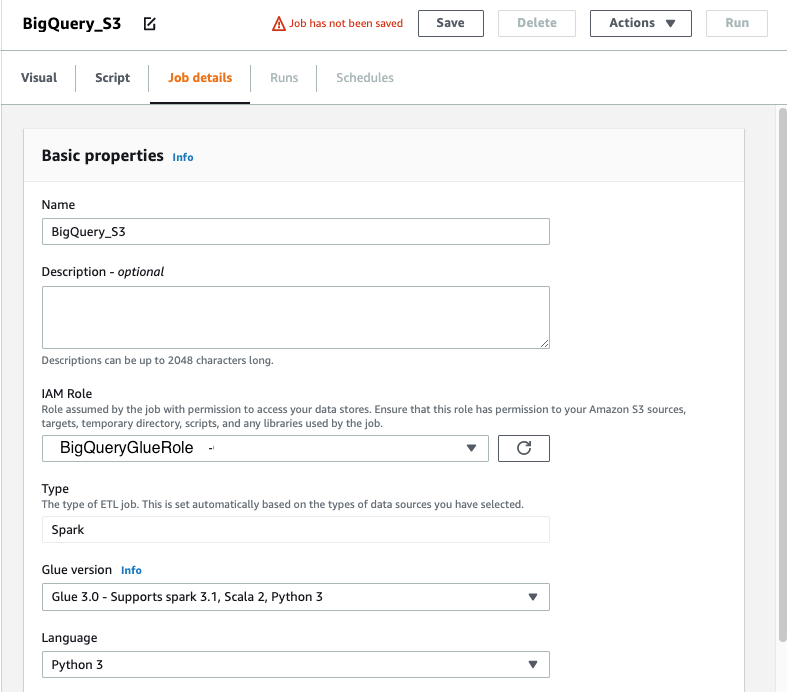
- Choose Job details.
- For Name, enter
BigQuery_S3. - For IAM Role, choose the role you created.
- For Type, choose Spark.
- For Glue version, choose Glue 3.0 – Supports Spark 3.1, Scala 2, Python3.
- Leave rest of the options as defaults.
- Choose Save.
- To run the job, choose the Run Job button.
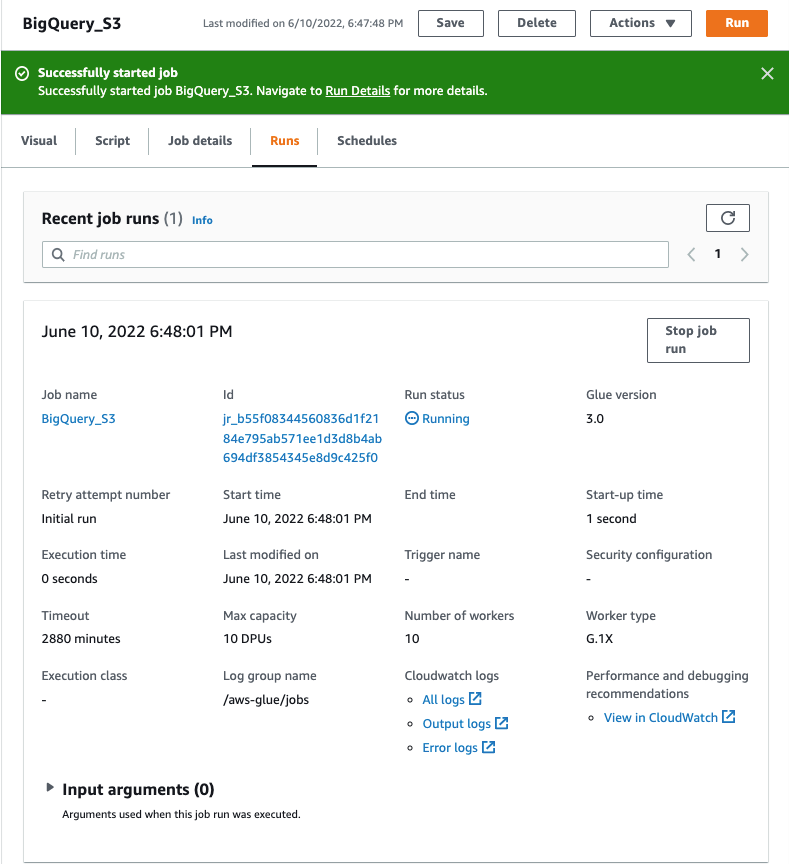
- Once the job run succeeds, check the S3 bucket for data.
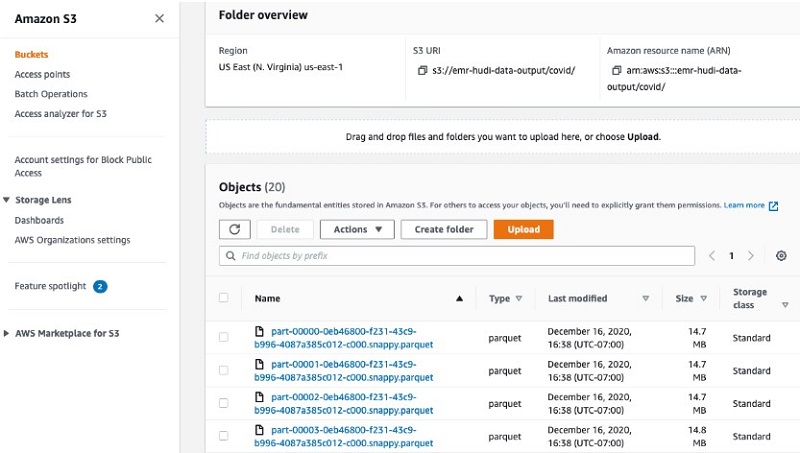
In this job, we use the connector to read data from the Big Query public dataset for COVID-19. For more information, see Apache Spark SQL connector for Google BigQuery on GitHub.
Querying the data
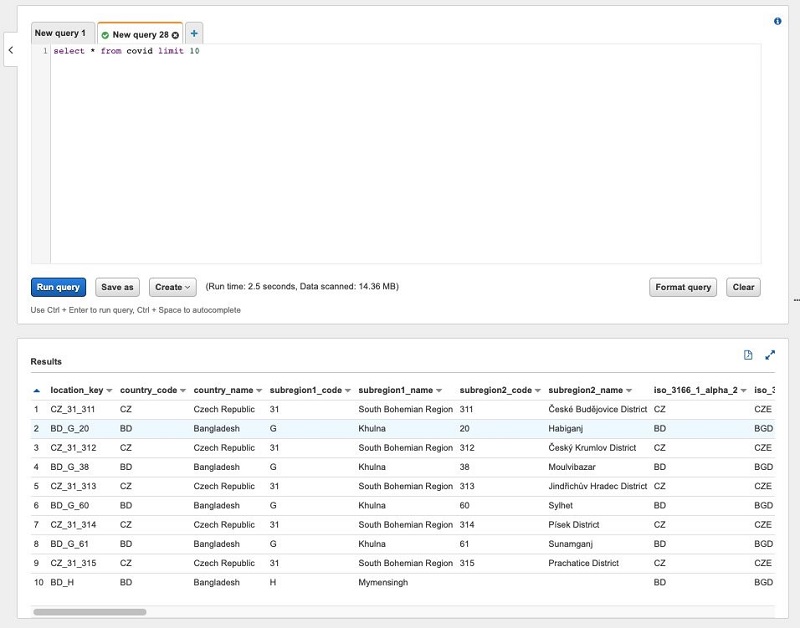
You can now use the Glue Crawlers to crawl the data in S3 bucket. It will create a table covid. You can now go to Athena and query this data. The following screenshot shows our query results.
Pricing considerations
There might be egress charges for migrating data out of Google BigQuery into Amazon S3. Review and calculate the cost for moving data into Amazon S3.
AWS Glue 3.0 charges $0.44 per DPU-hour, billed per second, with a 1-minute minimum for Spark ETL jobs. An Apache Spark job run in AWS Glue requires a minimum of 2 DPUs. By default, AWS Glue allocates 10 DPUs to each Apache Spark job. Modify the number of workers based on your job requirements. With Auto Scaling enabled, AWS Glue automatically adds and removes workers from the cluster depending on the parallelism at each stage or microbatch of the job run. You no longer need to worry about over-provisioning resources for jobs, spend time optimizing the number of workers, or pay for idle workers. For more information, see AWS Glue pricing.
Conclusion
In this post, we learned how to easily use AWS Glue ETL to connect to BigQuery tables and migrate the data into Amazon S3, and then query the data immediately with Athena. With AWS Glue, you can significantly reduce the cost, complexity, and time spent creating ETL jobs. AWS Glue is serverless, so there is no infrastructure to set up or manage. You pay only for the resources consumed while your jobs are running.
For more information about AWS Glue ETL jobs, see Simplify data pipelines with AWS Glue automatic code generation and workflows and Making ETL easier with AWS Glue Studio.
About the Author
 Saurabh Bhutyani is a Senior Big Data Specialist Solutions Architect at Amazon Web Services. He is an early adopter of open-source big data technologies. At AWS, he works with customers to provide architectural guidance for running analytics solutions on Amazon EMR, Amazon Athena, AWS Glue, and AWS Lake Formation. In his free time, he likes to watch movies and spend time with his family.
Saurabh Bhutyani is a Senior Big Data Specialist Solutions Architect at Amazon Web Services. He is an early adopter of open-source big data technologies. At AWS, he works with customers to provide architectural guidance for running analytics solutions on Amazon EMR, Amazon Athena, AWS Glue, and AWS Lake Formation. In his free time, he likes to watch movies and spend time with his family.