AWS Big Data Blog
Category: Amazon Redshift

Automating deployment of Amazon Redshift ETL jobs with AWS CodeBuild, AWS Batch, and DBT
This post was last reviewed and updated June, 2022 to update the code and service used on the AWS CloudFormation template. Data has become an essential part of every business, and its volume, velocity, and variety continue to increase. This has resulted in more complex ETL jobs with interdependencies between each other. There is also […]

Federating single sign-on access to your Amazon Redshift cluster with PingIdentity
Single sign-on (SSO) enables users to have a seamless user experience while accessing various applications in the organization. If you’re responsible for setting up security and database access privileges for users and tasked with enabling SSO for Amazon Redshift, you can set up SSO authentication using ADFS, PingIdentity, Okta, Azure AD or other SAML browser […]

Best practices using AWS SCT and AWS Snowball to migrate from Teradata to Amazon Redshift
This is a guest post from ZS. In their own words, “ZS is a professional services firm that works closely with companies to help develop and deliver products and solutions that drive customer value and company results. ZS engagements involve a blend of technology, consulting, analytics, and operations, and are targeted toward improving the commercial […]
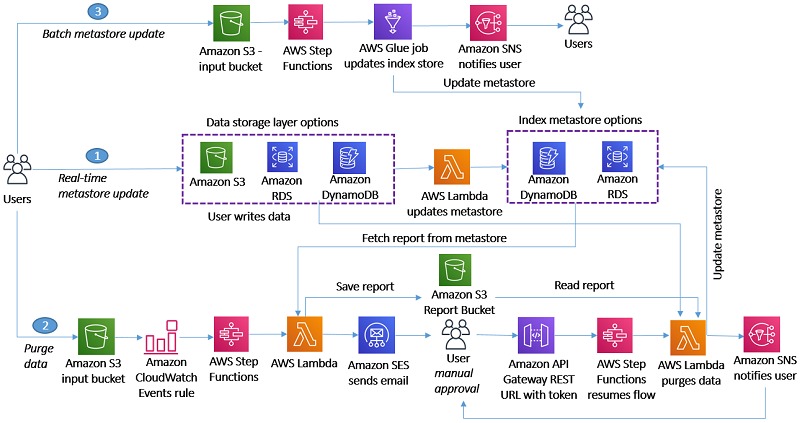
How to delete user data in an AWS data lake
General Data Protection Regulation (GDPR) is an important aspect of today’s technology world, and processing data in compliance with GDPR is a necessity for those who implement solutions within the AWS public cloud. One article of GDPR is the “right to erasure” or “right to be forgotten” which may require you to implement a solution […]
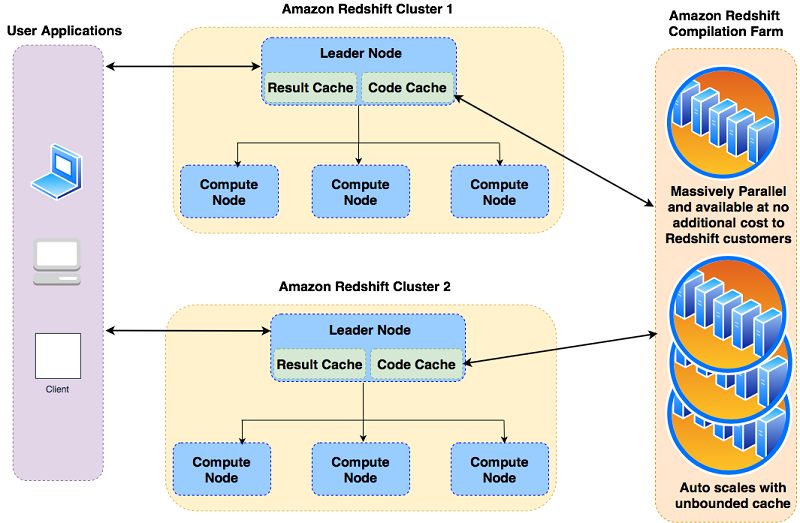
Fast and predictable performance with serverless compilation using Amazon Redshift
Amazon Redshift is a fast, fully managed cloud data warehouse that makes it simple and cost-effective to analyze all your data using standard SQL and your existing business intelligence (BI) tools. Customers tell us that they want extremely fast query response times so they can make equally fast decisions. This post presents the recently launched, […]
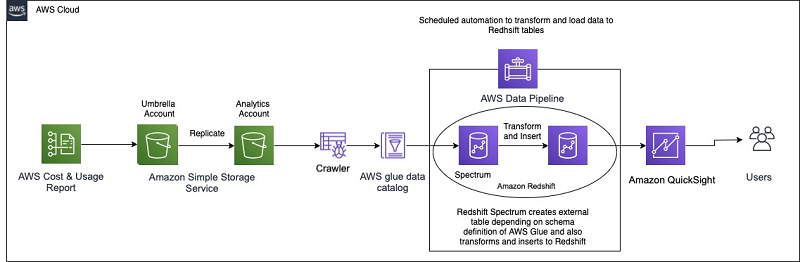
How Aruba Networks built a cost analysis solution using AWS Glue, Amazon Redshift, and Amazon QuickSight
February 2023 Update: Console access to the AWS Data Pipeline service will be removed on April 30, 2023. On this date, you will no longer be able to access AWS Data Pipeline though the console. You will continue to have access to AWS Data Pipeline through the command line interface and API. Please note that […]

Top 10 performance tuning techniques for Amazon Redshift
Customers use Amazon Redshift for everything from accelerating existing database environments, to ingesting weblogs for big data analytics. Amazon Redshift is a fully managed, petabyte-scale, massively parallel data warehouse that offers simple operations and high performance. Amazon Redshift provides an open standard JDBC/ODBC driver interface, which allows you to connect your existing business intelligence (BI) tools and reuse existing analytics queries. Amazon Redshift can run any type of data model, from a production transaction system third-normal-form model to star and snowflake schemas, data vault, or simple flat tables. This post takes you through the most common performance-related opportunities when adopting Amazon Redshift and gives you concrete guidance on how to optimize each one.
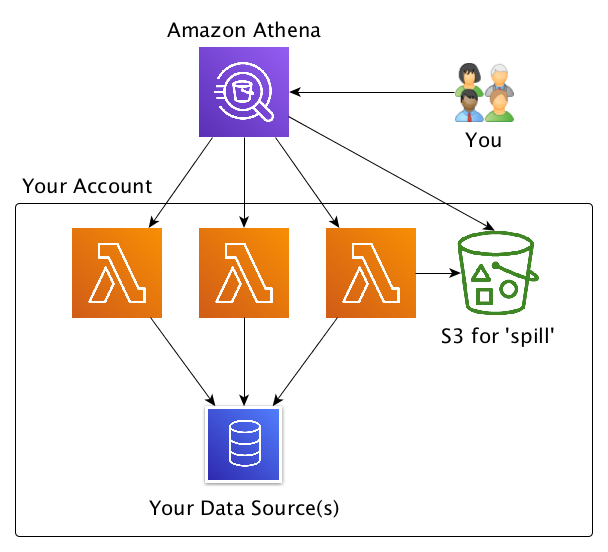
Configure and optimize performance of Amazon Athena federation with Amazon Redshift
This post provides guidance on how to configure Amazon Athena federation with AWS Lambda and Amazon Redshift, while addressing performance considerations to ensure proper use.

Speed up data ingestion on Amazon Redshift with BryteFlow
This is a guest post by Pradnya Bhandary, Co-Founder and CEO at Bryte Systems. Data can be transformative for an organization. How and where you store your data for analysis and business intelligence is therefore an especially important decision that each organization needs to make. Should you choose an on-premises data warehouse solution or embrace […]
Stream, transform, and analyze XML data in real time with Amazon Kinesis, AWS Lambda, and Amazon Redshift
August 30, 2023: Amazon Kinesis Data Analytics has been renamed to Amazon Managed Service for Apache Flink. Read the announcement in the AWS News Blog and learn more. February 9, 2024: Amazon Kinesis Data Firehose has been renamed to Amazon Data Firehose. Read the AWS What’s New post to learn more. When we look at […]