AWS Big Data Blog
Category: Advanced (300)

Create a comprehensive view of AWS support cases with Amazon QuickSight
AWS customers are looking for an efficient tracking method of support cases raised with AWS Support across their multiple interconnected accounts. Having a unified view lets the cloud operations team derive actionable insights across the support cases raised by different business units and accounts. This helps ensure that the team has a comprehensive understanding of […]

Access Amazon OpenSearch Serverless collections using a VPC endpoint
Amazon OpenSearch Serverless helps you index, analyze, and search your logs and data using OpenSearch APIs and dashboards. The OpenSearch Serverless collection is a group of indexes. API and dashboard clients can access the collections from public networks or one or more VPCs. For VPC access to collections and dashboards, you can create VPC endpoints. […]

Extract time series from satellite weather data with AWS Lambda
Extracting time series on given geographical coordinates from satellite or Numerical Weather Prediction data can be challenging because of the volume of data and of its multidimensional nature (time, latitude, longitude, height, multiple parameters). This type of processing can be found in weather and climate research, but also in applications like photovoltaic and wind power. […]

Backtesting index rebalancing arbitrage with Amazon EMR and Apache Iceberg
Backtesting is a process used in quantitative finance to evaluate trading strategies using historical data. This helps traders determine the potential profitability of a strategy and identify any risks associated with it, enabling them to optimize it for better performance. Index rebalancing arbitrage takes advantage of short-term price discrepancies resulting from ETF managers’ efforts to […]

Migrate from Amazon Kinesis Data Analytics for SQL Applications to Amazon Managed Service for Apache Flink Studio
February 9, 2024: Amazon Kinesis Data Firehose has been renamed to Amazon Data Firehose. Read the AWS What’s New post to learn more. August 30, 2023: Amazon Kinesis Data Analytics has been renamed to Amazon Managed Service for Apache Flink. Read the announcement in the AWS News Blog and learn more. In this post, we […]

Centralize near-real-time governance through alerts on Amazon Redshift data warehouses for sensitive queries
Amazon Redshift is a fully managed, petabyte-scale data warehouse service in the cloud that delivers powerful and secure insights on all your data with the best price-performance. With Amazon Redshift, you can analyze your data to derive holistic insights about your business and your customers. In many organizations, one or multiple Amazon Redshift data warehouses […]

Build an Amazon Redshift data warehouse using an Amazon DynamoDB single-table design
DynamoDB zero-ETL integration with Amazon Redshift is now generally available and provides fully-managed replication of DynamoDB tables into an Amazon Redshift database. Learn more at DynamoDB zero-ETL integration with Amazon Redshift. Amazon DynamoDB is a fully managed NoSQL service that delivers single-digit millisecond performance at any scale. It’s used by thousands of customers for mission-critical […]

Stream VPC Flow Logs to Datadog via Amazon Kinesis Data Firehose
February 9, 2024: Amazon Kinesis Data Firehose has been renamed to Amazon Data Firehose. Read the AWS What’s New post to learn more. It’s common to store the logs generated by customer’s applications and services in various tools. These logs are important for compliance, audits, troubleshooting, security incident responses, meeting security policies, and many other […]

Accelerate data science feature engineering on transactional data lakes using Amazon Athena with Apache Iceberg
Amazon Athena is an interactive query service that makes it easy to analyze data in Amazon Simple Storage Service (Amazon S3) and data sources residing in AWS, on-premises, or other cloud systems using SQL or Python. Athena is built on open-source Trino and Presto engines, and Apache Spark frameworks, with no provisioning or configuration effort […]
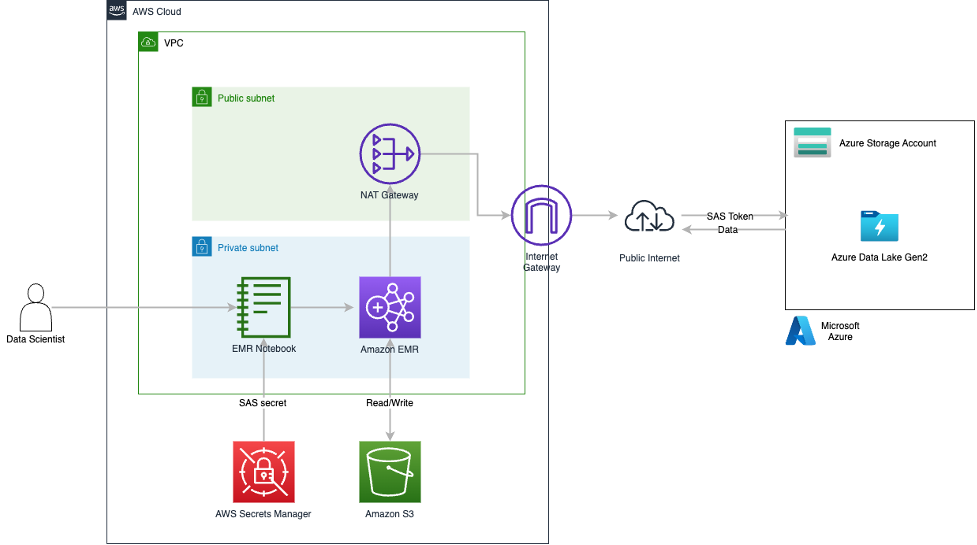
Enable remote reads from Azure ADLS with SAS tokens using Spark in Amazon EMR
Organizations use data from many sources to understand, analyze, and grow their business. These data sources are often spread across various public cloud providers. Enterprises may also expand their footprint by mergers and acquisitions, and during such events they often end up with data spread across different public cloud providers. These scenarios can create the […]