AWS Big Data Blog
Category: Advanced (300)
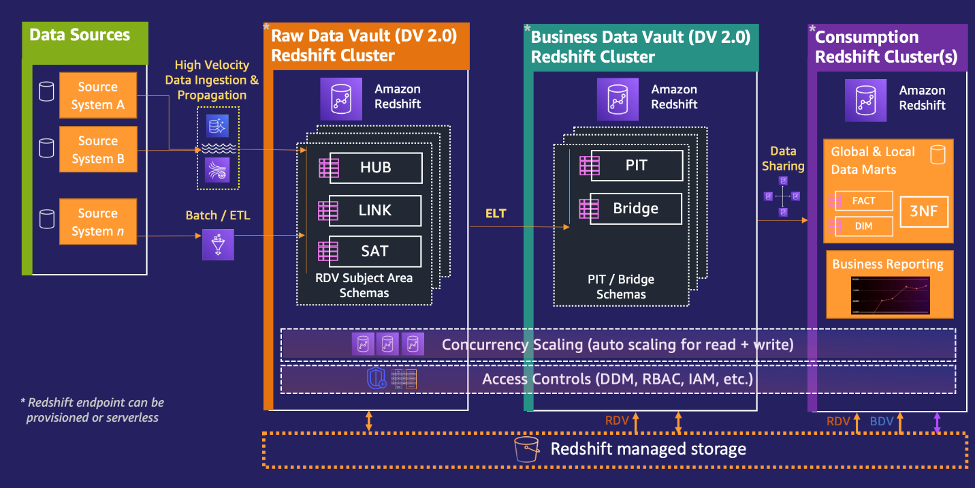
Power enterprise-grade Data Vaults with Amazon Redshift – Part 2
Amazon Redshift is a popular cloud data warehouse, offering a fully managed cloud-based service that seamlessly integrates with an organization’s Amazon Simple Storage Service (Amazon S3) data lake, real-time streams, machine learning (ML) workflows, transactional workflows, and much more—all while providing up to 7.9x better price-performance than any other cloud data warehouses. As with all […]

Implement Apache Flink real-time data enrichment patterns
You can use several approaches to enrich your real-time data in Amazon Managed Service for Apache Flink depending on your use case and Apache Flink abstraction level. Each method has different effects on the throughput, network traffic, and CPU (or memory) utilization. For a general overview of data enrichment patterns, refer to Common streaming data enrichment patterns in Amazon Managed Service for Apache Flink. This post covers how you can implement data enrichment for real-time streaming events with Apache Flink and how you can optimize performance. To compare the performance of the enrichment patterns, we ran performance testing based on synthetic data. The result of this test is useful as a general reference. It’s important to note that the actual performance for your Flink workload will depend on various and different factors, such as API latency, throughput, size of the event, and cache hit ratio.

Clean up your Excel and CSV files without writing code using AWS Glue DataBrew
Managing data within an organization is complex. Handling data from outside the organization adds even more complexity. As the organization receives data from multiple external vendors, it often arrives in different formats, typically Excel or CSV files, with each vendor using their own unique data layout and structure. In this blog post, we’ll explore a […]

Use IAM runtime roles with Amazon EMR Studio Workspaces and AWS Lake Formation for cross-account fine-grained access control
Amazon EMR Studio is an integrated development environment (IDE) that makes it straightforward for data scientists and data engineers to develop, visualize, and debug data engineering and data science applications written in R, Python, Scala, and PySpark. EMR Studio provides fully managed Jupyter notebooks and tools such as Spark UI and YARN Timeline Server via […]

Implement model versioning with Amazon Redshift ML
Amazon Redshift ML allows data analysts, developers, and data scientists to train machine learning (ML) models using SQL. In previous posts, we demonstrated how you can use the automatic model training capability of Redshift ML to train classification and regression models. Redshift ML allows you to create a model using SQL and specify your algorithm, […]

Enable Multi-AZ deployments for your Amazon Redshift data warehouse
November 2023: This post was reviewed and updated with the general availability of Multi-AZ deployments for provisioned RA3 clusters. Originally published on December 9th, 2022. Amazon Redshift is a fully managed, petabyte scale cloud data warehouse that enables you to analyze large datasets using standard SQL. Data warehouse workloads are increasingly being used with mission-critical […]

Use Snowflake with Amazon MWAA to orchestrate data pipelines
This blog post is co-written with James Sun from Snowflake. Customers rely on data from different sources such as mobile applications, clickstream events from websites, historical data, and more to deduce meaningful patterns to optimize their products, services, and processes. With a data pipeline, which is a set of tasks used to automate the movement […]

Spark on AWS Lambda: An Apache Spark runtime for AWS Lambda
Spark on AWS Lambda (SoAL) is a framework that runs Apache Spark workloads on AWS Lambda. It’s designed for both batch and event-based workloads, handling data payload sizes from 10 KB to 400 MB. This post highlights the SoAL architecture, provides infrastructure as code (IaC), offers step-by-step instructions for setting up the SoAL framework in your AWS account, and outlines SoAL architectural patterns for enterprises.

Simplify Amazon Redshift monitoring using the new unified SYS views
Amazon Redshift is a fully managed, petabyte-scale data warehouse service in the cloud, providing up to five times better price-performance than any other cloud data warehouse, with performance innovation out of the box at no additional cost to you. Tens of thousands of customers use Amazon Redshift to process exabytes of data every day to […]

Run Spark SQL on Amazon Athena Spark
At AWS re:Invent 2022, Amazon Athena launched support for Apache Spark. With this launch, Amazon Athena supports two open-source query engines: Apache Spark and Trino. Athena Spark allows you to build Apache Spark applications using a simplified notebook experience on the Athena console or through Athena APIs. Athena Spark notebooks support PySpark and notebook magics […]