AWS Big Data Blog
Category: Learning Levels

Configure end-to-end data pipelines with Etleap, Amazon Redshift, and dbt
This blog post is co-written with Zygimantas Koncius from Etleap. Organizations use their data to extract valuable insights and drive informed business decisions. With a wide array of data sources, including transactional databases, log files, and event streams, you need a simple-to-use solution capable of efficiently ingesting and transforming large volumes of data in real […]

Level up your React app with Amazon QuickSight: How to embed your dashboard for anonymous access
Using embedded analytics from Amazon QuickSight can simplify the process of equipping your application with functional visualizations without any complex development. There are multiple ways to embed QuickSight dashboards into application. In this post, we look at how it can be done using React and the Amazon QuickSight Embedding SDK. Dashboard consumers often don’t have […]

Access Amazon OpenSearch Serverless collections using a VPC endpoint
Amazon OpenSearch Serverless helps you index, analyze, and search your logs and data using OpenSearch APIs and dashboards. The OpenSearch Serverless collection is a group of indexes. API and dashboard clients can access the collections from public networks or one or more VPCs. For VPC access to collections and dashboards, you can create VPC endpoints. […]

Extract time series from satellite weather data with AWS Lambda
Extracting time series on given geographical coordinates from satellite or Numerical Weather Prediction data can be challenging because of the volume of data and of its multidimensional nature (time, latitude, longitude, height, multiple parameters). This type of processing can be found in weather and climate research, but also in applications like photovoltaic and wind power. […]

Backtesting index rebalancing arbitrage with Amazon EMR and Apache Iceberg
Backtesting is a process used in quantitative finance to evaluate trading strategies using historical data. This helps traders determine the potential profitability of a strategy and identify any risks associated with it, enabling them to optimize it for better performance. Index rebalancing arbitrage takes advantage of short-term price discrepancies resulting from ETF managers’ efforts to […]

Migrate from Amazon Kinesis Data Analytics for SQL Applications to Amazon Managed Service for Apache Flink Studio
February 9, 2024: Amazon Kinesis Data Firehose has been renamed to Amazon Data Firehose. Read the AWS What’s New post to learn more. August 30, 2023: Amazon Kinesis Data Analytics has been renamed to Amazon Managed Service for Apache Flink. Read the announcement in the AWS News Blog and learn more. In this post, we […]

Centralize near-real-time governance through alerts on Amazon Redshift data warehouses for sensitive queries
Amazon Redshift is a fully managed, petabyte-scale data warehouse service in the cloud that delivers powerful and secure insights on all your data with the best price-performance. With Amazon Redshift, you can analyze your data to derive holistic insights about your business and your customers. In many organizations, one or multiple Amazon Redshift data warehouses […]

Getting started guide for near-real time operational analytics using Amazon Aurora zero-ETL integration with Amazon Redshift
November 2023: This post was reviewed and updated to include the latest enhancements in Aurora MySQL zero-ETL integration with Amazon Redshift on general availability (GA). Amazon Aurora zero-ETL integration with Amazon Redshift was announced at AWS re:Invent 2022 and is now generally available (GA) for Aurora MySQL 3.05.0 (compatible with MySQL 8.0.32) and higher version […]
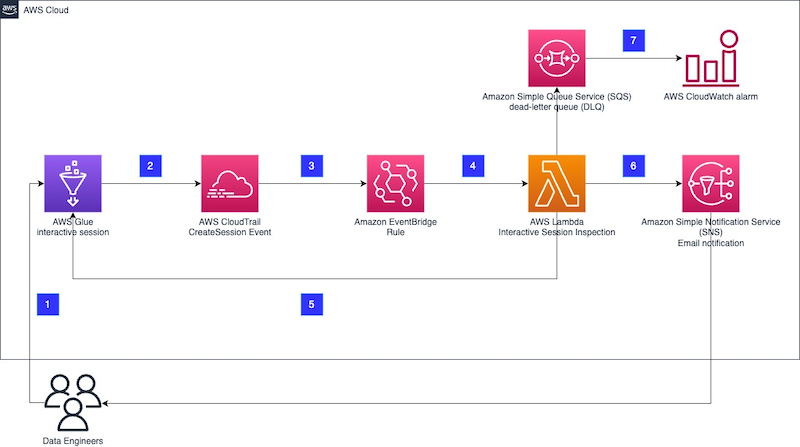
Enforce boundaries on AWS Glue interactive sessions
AWS Glue interactive sessions allow engineers to build, test, and run data preparation and analytics workloads in an interactive notebook. Interactive sessions provide isolated development environments, take care of the underlying compute cluster, and allow for configuration to stop idling resources. Glue interactive sessions provides default recommended configurations, and also allows users to customize the […]

Get started managing partitions for Amazon S3 tables backed by the AWS Glue Data Catalog
Large organizations processing huge volumes of data usually store it in Amazon Simple Storage Service (Amazon S3) and query the data to make data-driven business decisions using distributed analytics engines such as Amazon Athena. If you simply run queries without considering the optimal data layout on Amazon S3, it results in a high volume of […]