AWS Big Data Blog
How SOCAR handles large IoT data with Amazon MSK and Amazon ElastiCache for Redis
This is a guest blog post co-written with SangSu Park and JaeHong Ahn from SOCAR.
As companies continue to expand their digital footprint, the importance of real-time data processing and analysis cannot be overstated. The ability to quickly measure and draw insights from data is critical in today’s business landscape, where rapid decision-making is key. With this capability, businesses can stay ahead of the curve and develop new initiatives that drive success.
This post is a continuation of How SOCAR built a streaming data pipeline to process IoT data for real-time analytics and control. In this post, we provide a detailed overview of streaming messages with Amazon Managed Streaming for Apache Kafka (Amazon MSK) and Amazon ElastiCache for Redis, covering technical aspects and design considerations that are essential for achieving optimal results.
SOCAR is the leading Korean mobility company with strong competitiveness in car-sharing. SOCAR wanted to design and build a solution for a new Fleet Management System (FMS). This system involves the collection, processing, storage, and analysis of Internet of Things (IoT) streaming data from various vehicle devices, as well as historical operational data such as location, speed, fuel level, and component status.
This post demonstrates a solution for SOCAR’s production application that allows them to load streaming data from Amazon MSK into ElastiCache for Redis, optimizing the speed and efficiency of their data processing pipeline. We also discuss the key features, considerations, and design of the solution.
Background
SOCAR operates about 20,000 cars and is planning to include other large vehicle types such as commercial vehicles and courier trucks. SOCAR has deployed in-car devices that capture data using AWS IoT Core. This data was then stored in Amazon Relational Database Service (Amazon RDS). The challenge with this approach included inefficient performance and high resource usage. Therefore, SOCAR looked for purpose-built databases tailored to the needs of their application and usage patterns while meeting the future requirements of SOCAR’s business and technical requirements. The key requirements for SOCAR included achieving maximum performance for real-time data analytics, which required storing data in an in-memory data store.
After careful consideration, ElastiCache for Redis was selected as the optimal solution due to its ability to handle complex data aggregation rules with ease. One of the challenges faced was loading data from Amazon MSK into the database, because there was no built-in Kafka connector and consumer available for this task. This post focuses on the development of a Kafka consumer application that was designed to tackle this challenge by enabling performant data loading from Amazon MSK to Redis.
Solution overview
Extracting valuable insights from streaming data can be a challenge for businesses with diverse use cases and workloads. That’s why SOCAR built a solution to seamlessly bring data from Amazon MSK into multiple purpose-built databases, while also empowering users to transform data as needed. With fully managed Apache Kafka, Amazon MSK provides a reliable and efficient platform for ingesting and processing real-time data.
The following figure shows an example of the data flow at SOCAR.
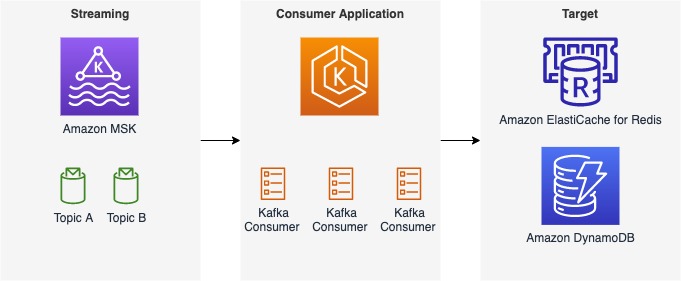
This architecture consists of three components:
- Streaming data – Amazon MSK serves as a scalable and reliable platform for streaming data, capable of receiving and storing messages from a variety of sources, including AWS IoT Core, with messages organized into multiple topics and partitions
- Consumer application – With a consumer application, users can seamlessly bring data from Amazon MSK into a target database or data storage while also defining data transformation rules as needed
- Target databases – With the consumer application, the SOCAR team was able to load data from Amazon MSK into two separate databases, each serving a specific workload
Although this post focuses on a specific use case with ElastiCache for Redis as the target database and a single topic called gps, the consumer application we describe can handle additional topics and messages, as well as different streaming sources and target databases such as Amazon DynamoDB. Our post covers the most important aspects of the consumer application, including its features and components, design considerations, and a detailed guide to the code implementation.
Components of the consumer application
The consumer application comprises three main parts that work together to consume, transform, and load messages from Amazon MSK into a target database. The following diagram shows an example of data transformations in the handler component.

The details of each component are as follows:
- Consumer – This consumes messages from Amazon MSK and then forwards the messages to a downstream handler.
- Loader – This is where users specify a target database. For example, SOCAR’s target databases include ElastiCache for Redis and DynamoDB.
- Handler – This is where users can apply data transformation rules to the incoming messages before loading them into a target database.
Features of the consumer application
This connection has three features:
- Scalability – This solution is designed to be scalable, ensuring that the consumer application can handle an increasing volume of data and accommodate additional applications in the future. For instance, SOCAR sought to develop a solution capable of handling not only the current data from approximately 20,000 vehicles but also a larger volume of messages as the business and data continue to grow rapidly.
- Performance – With this consumer application, users can achieve consistent performance, even as the volume of source messages and target databases increases. The application supports multithreading, allowing for concurrent data processing, and can handle unexpected spikes in data volume by easily increasing compute resources.
- Flexibility – This consumer application can be reused for any new topics without having to build the entire consumer application again. The consumer application can be used to ingest new messages with different configuration values in the handler. SOCAR deployed multiple handlers to ingest many different messages. Also, this consumer application allows users to add additional target locations. For example, SOCAR initially developed a solution for ElastiCache for Redis and then replicated the consumer application for DynamoDB.
Design considerations of the consumer application
Note the following design considerations for the consumer application:
- Scale out – A key design principle of this solution is scalability. To achieve this, the consumer application runs with Amazon Elastic Kubernetes Service (Amazon EKS) because it can allow users to increase and replicate consumer applications easily.
- Consumption patterns – To receive, store, and consume data efficiently, it’s important to design Kafka topics depending on messages and consumption patterns. Depending on messages consumed at the end, messages can be received into multiple topics of different schemas. For example, SOCAR has many different topics that are consumed by different workloads.
- Purpose-built database – The consumer application supports loading data into multiple target options based on the specific use case. For example, SOCAR stored real-time IoT data in ElastiCache for Redis to power real-time dashboard and web applications, while storing recent trip information in DynamoDB that didn’t require real-time processing.
Walkthrough overview
The producer of this solution is AWS IoT Core, which sends out messages into a topic called gps. The target database of this solution is ElastiCache for Redis. ElastiCache for Redis a fast in-memory data store that provides sub-millisecond latency to power internet-scale, real-time applications. Built on open-source Redis and compatible with the Redis APIs, ElastiCache for Redis combines the speed, simplicity, and versatility of open-source Redis with the manageability, security, and scalability from Amazon to power the most demanding real-time applications.
The target location can be either another database or storage depending on the use case and workload. SOCAR uses Amazon EKS to operate the containerized solution to achieve scalability, performance, and flexibility. Amazon EKS is a managed Kubernetes service to run Kubernetes in the AWS Cloud. Amazon EKS automatically manages the availability and scalability of the Kubernetes control plane nodes responsible for scheduling containers, managing application availability, storing cluster data, and other key tasks.
For the programming language, the SOCAR team decided to use the Go Programming language, utilizing both the AWS SDK for Go and a Goroutine, a lightweight logical or virtual thread managed by the Go runtime, which makes it easy to manage multiple threads. The AWS SDK for Go simplifies the use of AWS services by providing a set of libraries that are consistent and familiar for Go developers.
In the following sections, we walk through the steps to implement the solution:
- Create a consumer.
- Create a loader.
- Create a handler.
- Build a consumer application with the consumer, loader, and handler.
- Deploy the consumer application.
Prerequisites
For this walkthrough, you should have the following:
- An AWS account
- An MSK cluster
- An EKS cluster or Amazon Elastic Compute Cloud (Amazon EC2) instance
- ElastiCache for Redis
- An AWS Identity and Access Management (IAM) user for Amazon MSK (for more information, refer to How Amazon MSK works with IAM)
- Go (programming language)
Create a consumer
In this example, we use a topic called gps, and the consumer includes a Kafka client that receives messages from the topic. SOCAR created a struct and built a consumer (called NewConsumer in the code) to make it extendable. With this approach, any additional parameters and rules can be added easily.
To authenticate with Amazon MSK, SOCAR uses IAM. Because SOCAR already uses IAM to authenticate other resources, such as Amazon EKS, it uses the same IAM role (aws_msk_iam_v2) to authenticate clients for both Amazon MSK and Apache Kafka actions.
The following code creates the consumer:
Create a loader
The loader function, represented by the Loader struct, is responsible for loading messages to the target location, which in this case is ElastiCache for Redis. The NewLoader function initializes a new instance of the Loader struct with a logger and a Redis cluster client, which is used to communicate with the ElastiCache cluster. The redis.NewClusterClient object is initialized using the NewRedisClient function, which uses IAM to authenticate the client for Redis actions. This ensures secure and authorized access to the ElastiCache cluster. The Loader struct also contains the Close method to close the Kafka reader and free up resources.
The following code creates a loader:
Create a handler
A handler is used to include business rules and data transformation logic that prepares data before loading it into the target location. It acts as a bridge between a consumer and a loader. In this example, the topic name is cars.gps.json, and the message includes two keys, lng and lat, with data type Float64. The business logic can be defined in a function like handlerFuncGpsToRedis and then applied as follows:
Build a consumer application with the consumer, loader, and handler
Now you have created the consumer, loader, and handler. The next step is to build a consumer application using them. In a consumer application, you read messages from your stream with a consumer, transform them using a handler, and then load transformed messages into a target location with a loader. These three components are parameterized in a consumer application function such as the one shown in the following code:
Deploy the consumer application
To achieve maximum parallelism, SOCAR containerizes the consumer application and deploys it into multiple pods on Amazon EKS. Each consumer application contains a unique consumer, loader, and handler. For example, if you need to receive messages from a single topic with five partitions, you can deploy five identical consumer applications, each running in its own pod. Similarly, if you have two topics with three partitions each, you should deploy two consumer applications, resulting in a total of six pods. It’s a best practice to run one consumer application per topic, and the number of pods should match the number of partitions to enable concurrent message processing. The pod number can be specified in the Kubernetes deployment configuration
There are two stages in the Dockerfile. The first stage is the builder, which installs build tools and dependencies, and builds the application. The second stage is the runner, which uses a smaller base image (Alpine) and copies only the necessary files from the builder stage. It also sets the appropriate user permissions and runs the application. It’s also worth noting that the builder stage uses a specific version of the Golang image, while the runner stage uses a specific version of the Alpine image, both of which are considered to be lightweight and secure images.
The following code is an example of the Dockerfile:
Conclusion
In this post, we discussed SOCAR’s approach to building a consumer application that enables IoT real-time streaming from Amazon MSK to target locations such as ElastiCache for Redis. We hope you found this post informative and useful. Thank you for reading!
About the Authors
 SangSu Park is the Head of Operation Group at SOCAR. His passion is to keep learning, embrace challenges, and strive for mutual growth through communication. He loves to travel in search of new cities and places.
SangSu Park is the Head of Operation Group at SOCAR. His passion is to keep learning, embrace challenges, and strive for mutual growth through communication. He loves to travel in search of new cities and places.
 JaeHong Ahn is a DevOps Engineer in SOCAR’s cloud infrastructure team. He is dedicated to promoting collaboration between developers and operators. He enjoys creating DevOps tools and is committed to using his coding abilities to help build a better world. He loves to cook delicious meals as a private chef for his wife.
JaeHong Ahn is a DevOps Engineer in SOCAR’s cloud infrastructure team. He is dedicated to promoting collaboration between developers and operators. He enjoys creating DevOps tools and is committed to using his coding abilities to help build a better world. He loves to cook delicious meals as a private chef for his wife.
 Younggu Yun works at AWS Data Lab in Korea. His role involves helping customers across the APAC region meet their business objectives and overcome technical challenges by providing prescriptive architectural guidance, sharing best practices, and building innovative solutions together.
Younggu Yun works at AWS Data Lab in Korea. His role involves helping customers across the APAC region meet their business objectives and overcome technical challenges by providing prescriptive architectural guidance, sharing best practices, and building innovative solutions together.